 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecoMind: A Reinforcement Learning Framework for Optimizing In-Session User Satisfaction in Recommendation Systems
Jul 31, 2025Existing web-scale recommendation systems commonly use supervised learning methods that prioritize immediate user feedback. Although reinforcement learning (RL) offers a solution to optimize longer-term goals, such as in-session engagement, applying it at web scale is challenging due to the extremely large action space and engineering complexity. In this paper, we introduce RecoMind, a simulator-based RL framework designed for the effective optimization of session-based goals at web-scale. RecoMind leverages existing recommendation models to establish a simulation environment and to bootstrap the RL policy to optimize immediate user interactions from the outset. This method integrates well with existing industry pipelines, simplifying the training and deployment of RL policies. Additionally, RecoMind introduces a custom exploration strategy to efficiently explore web-scale action spaces with hundreds of millions of items. We evaluated RecoMind through extensive offline simulations and online A/B testing on a video streaming platform. Both methods showed that the RL policy trained using RecoMind significantly outperforms traditional supervised learning recommendation approaches in in-session user satisfaction. In online A/B tests, the RL policy increased videos watched for more than 10 seconds by 15.81\% and improved session depth by 4.71\% for sessions with at least 10 interactions. As a result, RecoMind presents a systematic and scalable approach for embedding RL into web-scale recommendation systems, showing great promise for optimizing session-based user satisfaction.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach
Jun 07, 2024


The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model. Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues. Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources. Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestions can greatly increase the waiting time for GPUs. To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are two folds. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction. By leveraging this feature, C4 can rapidly identify the faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection. Second, the predictable communication model of collective communication, involving few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion. C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.
Pelvic floor MRI segmentation based on semi-supervised deep learning
Nov 06, 2023



The semantic segmentation of pelvic organs via MRI has important clinical significance. Recently, deep learning-enabled semantic segmentation has facilitated the three-dimensional geometric reconstruction of pelvic floor organs, providing clinicians with accurate and intuitive diagnostic results. However, the task of labeling pelvic floor MRI segmentation, typically performed by clinicians, is labor-intensive and costly, leading to a scarcity of labels. Insufficient segmentation labels limit the precise segmentation and reconstruction of pelvic floor organs. To address these issues, we propose a semi-supervised framework for pelvic organ segmentation. The implementation of this framework comprises two stages. In the first stage, it performs self-supervised pre-training using image restoration tasks. Subsequently, fine-tuning of the self-supervised model is performed, using labeled data to train the segmentation model. In the second stage, the self-supervised segmentation model is used to generate pseudo labels for unlabeled data. Ultimately, both labeled and unlabeled data are utilized in semi-supervised training. Upon evaluation, our method significantly enhances the performance in the semantic segmentation and geometric reconstruction of pelvic organs, Dice coefficient can increase by 2.65% averagely. Especially for organs that are difficult to segment, such as the uterus, the accuracy of semantic segmentation can be improved by up to 3.70%.
Neuro-Dynamic State Estimation for Networked Microgrids
Aug 25, 2022
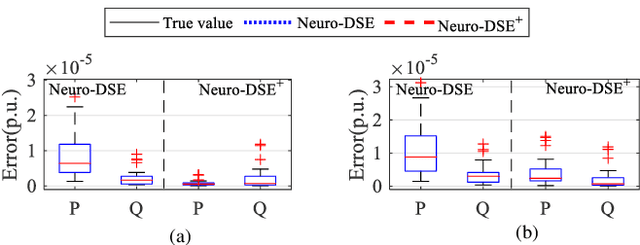
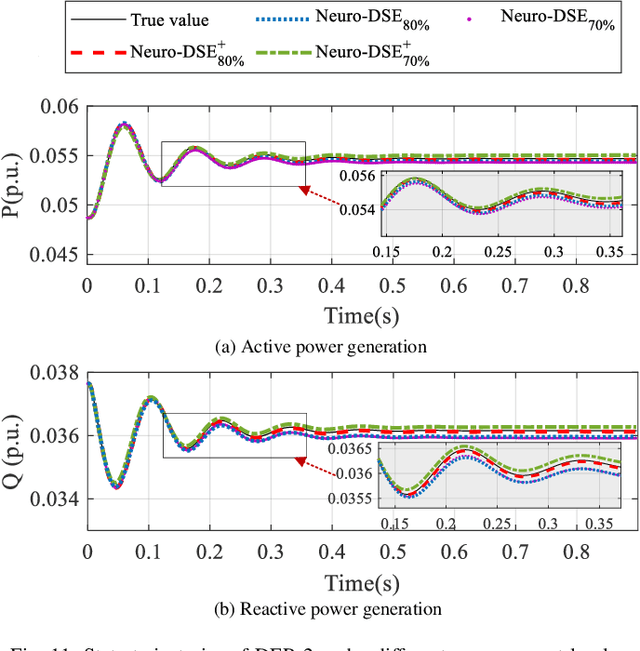
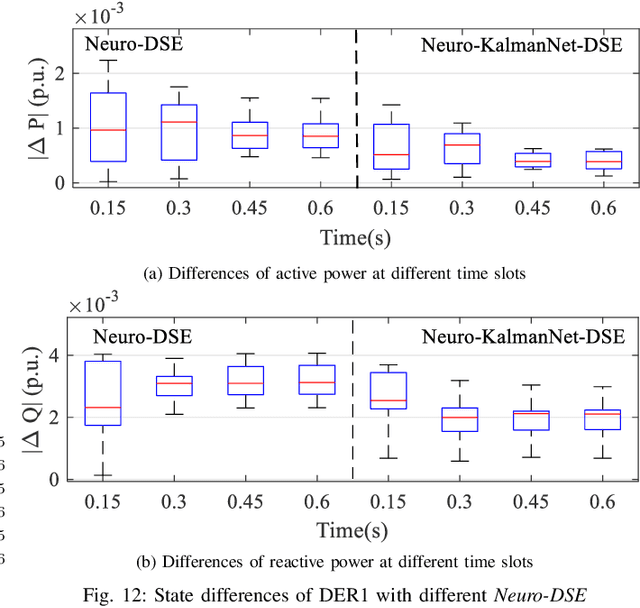
We devise neuro-dynamic state estimation (Neuro-DSE), a learning-based dynamic state estimation (DSE) algorithm for networked microgrids (NMs) under unknown subsystems. Our contributions include: 1) a data-driven Neuro-DSE algorithm for NMs DSE with partially unidentified dynamic models, which incorporates the neural-ordinary-differential-equations (ODE-Net) into Kalman filters; 2) a self-refining Neuro-DSE algorithm (Neuro-DSE+) which enables data-driven DSE under limited and noisy measurements by establishing an automatic filtering, augmenting and correcting framework; 3) a Neuro-KalmanNet-DSE algorithm which further integrates KalmanNet with Neuro-DSE to relieve the model mismatch of both neural- and physics-based dynamic models; and 4) an augmented Neuro-DSE for joint estimation of NMs states and unknown parameters (e.g., inertia). Extensive case studies demonstrate the efficacy of Neuro-DSE and its variants under different noise levels, control modes, power sources, observabilities and model knowledge, respectively.
Image enhancement in acoustic-resolution photoacoustic microscopy enabled by a novel directional algorithm
Nov 19, 2021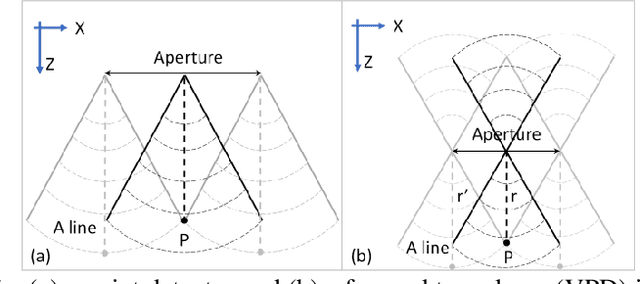



Acoustic-resolution photoacoustic microscopy (AR-PAM) is a promising tool for microvascular imaging. In the focal region, resolution of AR-PAM is determined by the ultrasound transducer and ultimately limited by acoustic diffraction. In the out-of-focus region, resolution deteriorates with increasing distance from the focal plane, which restricts depth of focus (DOF). Besides, a trade-off exists between resolution and DOF. Previously, synthetic aperture focusing technique (SAFT) and/or deconvolution methods have been demonstrated to enhance AR-PAM images. However, they suffer from issues in low resolution, low signal-to-noise ratio (SNR), and/or poor image fidelity. Here, we propose a novel algorithm for AR-PAM to enhance image resolution, SNR, and fidelity. The algorithm consists of a Fourier accumulation SAFT (FA-SAFT) and a directional model-based (D-MB) deconvolution method. Inspired from Fourier denoising technique and directional SAFT, FA-SAFT mainly compensates for the defocusing effect. Besides, D-MB deconvolution enhances the resolution as well as preserves the image fidelity, especially for the objects with line patterns such as microvasculature. Full width at half maximum of 26-31 um over DOF of 1.8 mm and minimum resolvable distance of 46-49 um are experimentally achieved by imaging tungsten wire phantom. Moreover, imaging of leaf skeleton phantom and in vivo imaging of mouse blood vessels also prove that our algorithm is capable of providing high-resolution, high-SNR, and good-fidelity results for complex structures and for in vivo applications.
Provably Correct Optimization and Exploration with Non-linear Policies
Mar 22, 2021
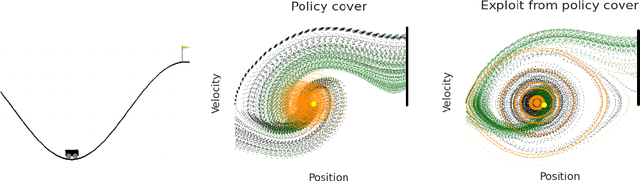
Policy optimization methods remain a powerful workhorse in empirical Reinforcement Learning (RL), with a focus on neural policies that can easily reason over complex and continuous state and/or action spaces. Theoretical understanding of strategic exploration in policy-based methods with non-linear function approximation, however, is largely missing. In this paper, we address this question by designing ENIAC, an actor-critic method that allows non-linear function approximation in the critic. We show that under certain assumptions, e.g., a bounded eluder dimension $d$ for the critic class, the learner finds a near-optimal policy in $O(\poly(d))$ exploration rounds. The method is robust to model misspecification and strictly extends existing works on linear function approximation. We also develop some computational optimizations of our approach with slightly worse statistical guarantees and an empirical adaptation building on existing deep RL tools. We empirically evaluate this adaptation and show that it outperforms prior heuristics inspired by linear methods, establishing the value via correctly reasoning about the agent's uncertainty under non-linear function approximation.
Provably Efficient Exploration for RL with Unsupervised Learning
Mar 15, 2020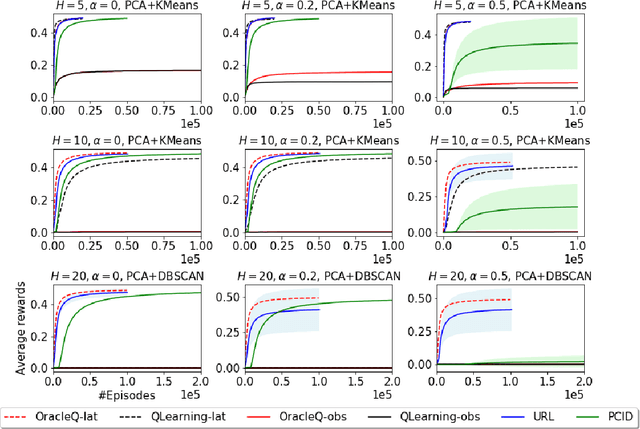
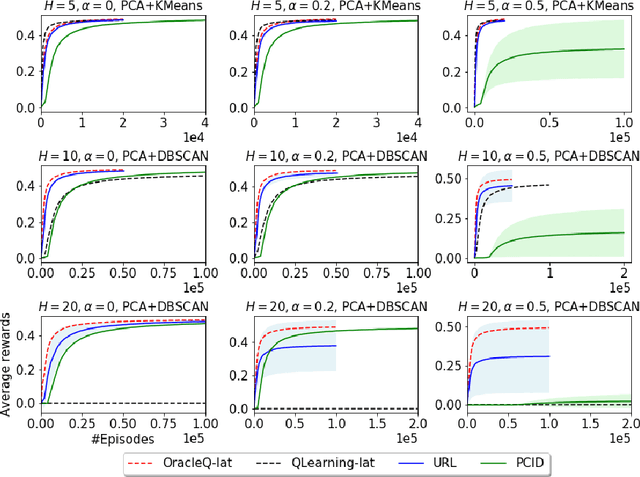
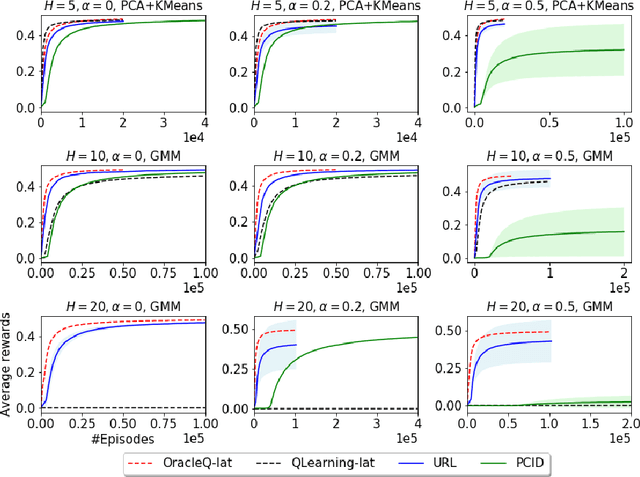
We study how to use unsupervised learning for efficient exploration in reinforcement learning with rich observations generated from a small number of latent states. We present a novel algorithmic framework that is built upon two components: an unsupervised learning algorithm and a no-regret reinforcement learning algorithm. We show that our algorithm provably finds a near-optimal policy with sample complexity polynomial in the number of latent states, which is significantly smaller than the number of possible observations. Our result gives theoretical justification to the prevailing paradigm of using unsupervised learning for efficient exploration [tang2017exploration,bellemare2016unifying].
Adaptive Distraction Context Aware Tracking Based on Correlation Filter
Dec 24, 2019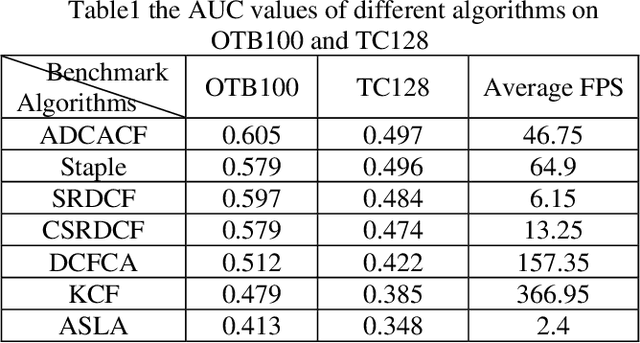
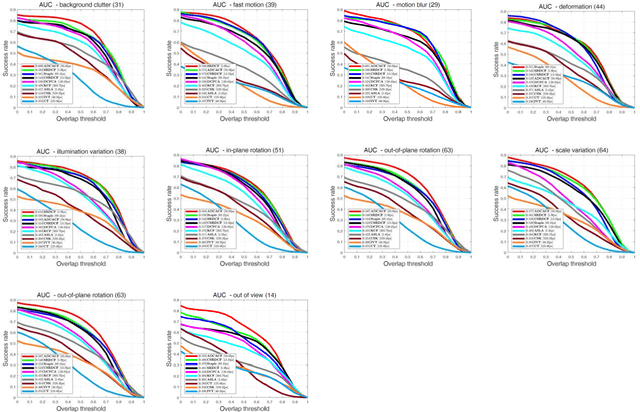

The Discriminative Correlation Filter (CF) uses a circulant convolution operation to provide several training samples for the design of a classifier that can distinguish the target from the background. The filter design may be interfered by objects close to the target during the tracking process, resulting in tracking failure. This paper proposes an adaptive distraction context aware tracking algorithm to solve this problem. In the response map obtained for the previous frame by the CF algorithm, we adaptively find the image blocks that are similar to the target and use them as negative samples. This diminishes the influence of similar image blocks on the classifier in the tracking process and its accuracy is improved. The tracking results on video sequences show that the algorithm can cope with rapid changes such as occlusion and rotation, and can adaptively use the distractive objects around the target as negative samples to improve the accuracy of target tracking.
Does Knowledge Transfer Always Help to Learn a Better Policy?
Dec 06, 2019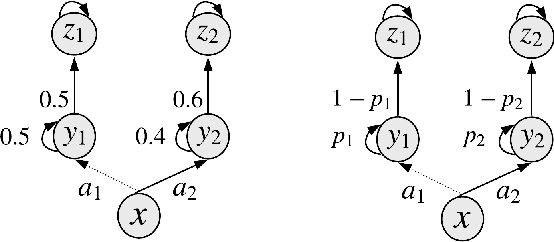
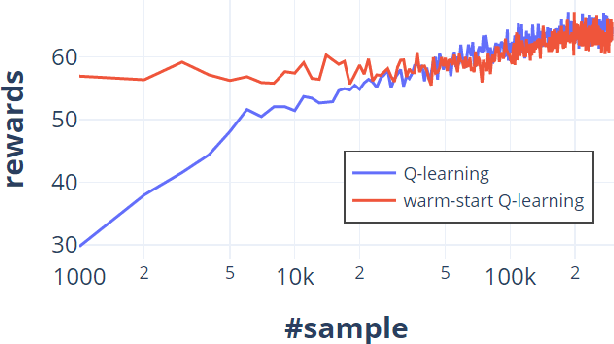

One of the key approaches to save samples when learning a policy for a reinforcement learning problem is to use knowledge from an approximate model such as its simulator. However, does knowledge transfer from approximate models always help to learn a better policy? Despite numerous empirical studies of transfer reinforcement learning, an answer to this question is still elusive. In this paper, we provide a strong negative result, showing that even the full knowledge of an approximate model may not help reduce the number of samples for learning an accurate policy of the true model. We construct an example of reinforcement learning models and show that the complexity with or without knowledge transfer has the same order. On the bright side, effective knowledge transferring is still possible under additional assumptions. In particular, we demonstrate that knowing the (linear) bases of the true model significantly reduces the number of samples for learning an accurate policy.