 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy and Memory-Efficient Federated Learning With Ordered Layer Freezing
Dec 29, 2025Federated Learning (FL) has emerged as a privacy-preserving paradigm for training machine learning models across distributed edge devices in the Internet of Things (IoT). By keeping data local and coordinating model training through a central server, FL effectively addresses privacy concerns and reduces communication overhead. However, the limited computational power, memory, and bandwidth of IoT edge devices pose significant challenges to the efficiency and scalability of FL, especially when training deep neural networks. Various FL frameworks have been proposed to reduce computation and communication overheads through dropout or layer freezing. However, these approaches often sacrifice accuracy or neglect memory constraints. To this end, in this work, we introduce Federated Learning with Ordered Layer Freezing (FedOLF). FedOLF consistently freezes layers in a predefined order before training, significantly mitigating computation and memory requirements. To further reduce communication and energy costs, we incorporate Tensor Operation Approximation (TOA), a lightweight alternative to conventional quantization that better preserves model accuracy. Experimental results demonstrate that over non-iid data, FedOLF achieves at least 0.3%, 6.4%, 5.81%, 4.4%, 6.27% and 1.29% higher accuracy than existing works respectively on EMNIST (with CNN), CIFAR-10 (with AlexNet), CIFAR-100 (with ResNet20 and ResNet44), and CINIC-10 (with ResNet20 and ResNet44), along with higher energy efficiency and lower memory footprint.
TrainMover: Efficient ML Training Live Migration with No Memory Overhead
Dec 17, 2024



Machine learning training has emerged as one of the most prominent workloads in modern data centers. These training jobs are large-scale, long-lasting, and tightly coupled, and are often disrupted by various events in the cluster such as failures, maintenance, and job scheduling. To handle these events, we rely on cold migration, where we first checkpoint the entire cluster, replace the related machines, and then restart the training. This approach leads to disruptions to the training jobs, resulting in significant downtime. In this paper, we present TrainMover, a live migration system that enables machine replacement during machine learning training. TrainMover minimizes downtime by leveraging member replacement of collective communication groups and sandbox lazy initialization. Our evaluation demonstrates that TrainMover achieves 16x less downtime compared to all baselines, effectively handling data center events like straggler rebalancing, maintenance, and unexpected failures.
Prompting Continual Person Search
Oct 25, 2024



The development of person search techniques has been greatly promoted in recent years for its superior practicality and challenging goals. Despite their significant progress, existing person search models still lack the ability to continually learn from increaseing real-world data and adaptively process input from different domains. To this end, this work introduces the continual person search task that sequentially learns on multiple domains and then performs person search on all seen domains. This requires balancing the stability and plasticity of the model to continually learn new knowledge without catastrophic forgetting. For this, we propose a Prompt-based Continual Person Search (PoPS) model in this paper. First, we design a compositional person search transformer to construct an effective pre-trained transformer without exhaustive pre-training from scratch on large-scale person search data. This serves as the fundamental for prompt-based continual learning. On top of that, we design a domain incremental prompt pool with a diverse attribute matching module. For each domain, we independently learn a set of prompts to encode the domain-oriented knowledge. Meanwhile, we jointly learn a group of diverse attribute projections and prototype embeddings to capture discriminative domain attributes. By matching an input image with the learned attributes across domains, the learned prompts can be properly selected for model inference. Extensive experiments are conducted to validate the proposed method for continual person search. The source code is available at https://github.com/PatrickZad/PoPS.
Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach
Jun 07, 2024

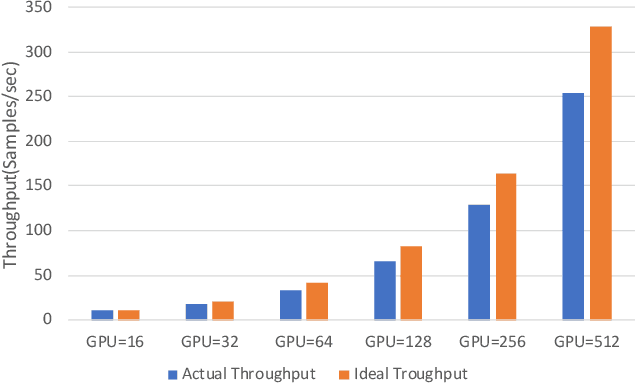

The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model. Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues. Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources. Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestions can greatly increase the waiting time for GPUs. To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are two folds. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction. By leveraging this feature, C4 can rapidly identify the faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection. Second, the predictable communication model of collective communication, involving few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion. C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.
RITFIS: Robust input testing framework for LLMs-based intelligent software
Feb 21, 2024The dependence of Natural Language Processing (NLP) intelligent software on Large Language Models (LLMs) is increasingly prominent, underscoring the necessity for robustness testing. Current testing methods focus solely on the robustness of LLM-based software to prompts. Given the complexity and diversity of real-world inputs, studying the robustness of LLMbased software in handling comprehensive inputs (including prompts and examples) is crucial for a thorough understanding of its performance. To this end, this paper introduces RITFIS, a Robust Input Testing Framework for LLM-based Intelligent Software. To our knowledge, RITFIS is the first framework designed to assess the robustness of LLM-based intelligent software against natural language inputs. This framework, based on given threat models and prompts, primarily defines the testing process as a combinatorial optimization problem. Successful test cases are determined by a goal function, creating a transformation space for the original examples through perturbation means, and employing a series of search methods to filter cases that meet both the testing objectives and language constraints. RITFIS, with its modular design, offers a comprehensive method for evaluating the robustness of LLMbased intelligent software. RITFIS adapts 17 automated testing methods, originally designed for Deep Neural Network (DNN)-based intelligent software, to the LLM-based software testing scenario. It demonstrates the effectiveness of RITFIS in evaluating LLM-based intelligent software through empirical validation. However, existing methods generally have limitations, especially when dealing with lengthy texts and structurally complex threat models. Therefore, we conducted a comprehensive analysis based on five metrics and provided insightful testing method optimization strategies, benefiting both researchers and everyday users.
A Spatial-Temporal Dual-Mode Mixed Flow Network for Panoramic Video Salient Object Detection
Oct 13, 2023



Salient object detection (SOD) in panoramic video is still in the initial exploration stage. The indirect application of 2D video SOD method to the detection of salient objects in panoramic video has many unmet challenges, such as low detection accuracy, high model complexity, and poor generalization performance. To overcome these hurdles, we design an Inter-Layer Attention (ILA) module, an Inter-Layer weight (ILW) module, and a Bi-Modal Attention (BMA) module. Based on these modules, we propose a Spatial-Temporal Dual-Mode Mixed Flow Network (STDMMF-Net) that exploits the spatial flow of panoramic video and the corresponding optical flow for SOD. First, the ILA module calculates the attention between adjacent level features of consecutive frames of panoramic video to improve the accuracy of extracting salient object features from the spatial flow. Then, the ILW module quantifies the salient object information contained in the features of each level to improve the fusion efficiency of the features of each level in the mixed flow. Finally, the BMA module improves the detection accuracy of STDMMF-Net. A large number of subjective and objective experimental results testify that the proposed method demonstrates better detection accuracy than the state-of-the-art (SOTA) methods. Moreover, the comprehensive performance of the proposed method is better in terms of memory required for model inference, testing time, complexity, and generalization performance.
Towards Fully Decoupled End-to-End Person Search
Sep 10, 2023



End-to-end person search aims to jointly detect and re-identify a target person in raw scene images with a unified model. The detection task unifies all persons while the re-id task discriminates different identities, resulting in conflict optimal objectives. Existing works proposed to decouple end-to-end person search to alleviate such conflict. Yet these methods are still sub-optimal on one or two of the sub-tasks due to their partially decoupled models, which limits the overall person search performance. In this paper, we propose to fully decouple person search towards optimal person search. A task-incremental person search network is proposed to incrementally construct an end-to-end model for the detection and re-id sub-task, which decouples the model architecture for the two sub-tasks. The proposed task-incremental network allows task-incremental training for the two conflicting tasks. This enables independent learning for different objectives thus fully decoupled the model for persons earch. Comprehensive experimental evaluations demonstrate the effectiveness of the proposed fully decoupled models for end-to-end person search.
LEAP: Efficient and Automated Test Method for NLP Software
Aug 22, 2023The widespread adoption of DNNs in NLP software has highlighted the need for robustness. Researchers proposed various automatic testing techniques for adversarial test cases. However, existing methods suffer from two limitations: weak error-discovering capabilities, with success rates ranging from 0% to 24.6% for BERT-based NLP software, and time inefficiency, taking 177.8s to 205.28s per test case, making them challenging for time-constrained scenarios. To address these issues, this paper proposes LEAP, an automated test method that uses LEvy flight-based Adaptive Particle swarm optimization integrated with textual features to generate adversarial test cases. Specifically, we adopt Levy flight for population initialization to increase the diversity of generated test cases. We also design an inertial weight adaptive update operator to improve the efficiency of LEAP's global optimization of high-dimensional text examples and a mutation operator based on the greedy strategy to reduce the search time. We conducted a series of experiments to validate LEAP's ability to test NLP software and found that the average success rate of LEAP in generating adversarial test cases is 79.1%, which is 6.1% higher than the next best approach (PSOattack). While ensuring high success rates, LEAP significantly reduces time overhead by up to 147.6s compared to other heuristic-based methods. Additionally, the experimental results demonstrate that LEAP can generate more transferable test cases and significantly enhance the robustness of DNN-based systems.
Towards Stealthy Backdoor Attacks against Speech Recognition via Elements of Sound
Jul 17, 2023Deep neural networks (DNNs) have been widely and successfully adopted and deployed in various applications of speech recognition. Recently, a few works revealed that these models are vulnerable to backdoor attacks, where the adversaries can implant malicious prediction behaviors into victim models by poisoning their training process. In this paper, we revisit poison-only backdoor attacks against speech recognition. We reveal that existing methods are not stealthy since their trigger patterns are perceptible to humans or machine detection. This limitation is mostly because their trigger patterns are simple noises or separable and distinctive clips. Motivated by these findings, we propose to exploit elements of sound ($e.g.$, pitch and timbre) to design more stealthy yet effective poison-only backdoor attacks. Specifically, we insert a short-duration high-pitched signal as the trigger and increase the pitch of remaining audio clips to `mask' it for designing stealthy pitch-based triggers. We manipulate timbre features of victim audios to design the stealthy timbre-based attack and design a voiceprint selection module to facilitate the multi-backdoor attack. Our attacks can generate more `natural' poisoned samples and therefore are more stealthy. Extensive experiments are conducted on benchmark datasets, which verify the effectiveness of our attacks under different settings ($e.g.$, all-to-one, all-to-all, clean-label, physical, and multi-backdoor settings) and their stealthiness. The code for reproducing main experiments are available at \url{https://github.com/HanboCai/BadSpeech_SoE}.
VSVC: Backdoor attack against Keyword Spotting based on Voiceprint Selection and Voice Conversion
Dec 20, 2022

Keyword spotting (KWS) based on deep neural networks (DNNs) has achieved massive success in voice control scenarios. However, training of such DNN-based KWS systems often requires significant data and hardware resources. Manufacturers often entrust this process to a third-party platform. This makes the training process uncontrollable, where attackers can implant backdoors in the model by manipulating third-party training data. An effective backdoor attack can force the model to make specified judgments under certain conditions, i.e., triggers. In this paper, we design a backdoor attack scheme based on Voiceprint Selection and Voice Conversion, abbreviated as VSVC. Experimental results demonstrated that VSVC is feasible to achieve an average attack success rate close to 97% in four victim models when poisoning less than 1% of the training data.