 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfTracker: Online Performance Troubleshooting for Large-scale Model Training in Production
Jun 12, 2025



Troubleshooting performance problems of large model training (LMT) is immensely challenging, due to unprecedented scales of modern GPU clusters, the complexity of software-hardware interactions, and the data intensity of the training process. Existing troubleshooting approaches designed for traditional distributed systems or datacenter networks fall short and can hardly apply to real-world training systems. In this paper, we present PerfTracker, the first online troubleshooting system utilizing fine-grained profiling, to diagnose performance issues of large-scale model training in production. PerfTracker can diagnose performance issues rooted in both hardware (e.g., GPUs and their interconnects) and software (e.g., Python functions and GPU operations). It scales to LMT on modern GPU clusters. PerfTracker effectively summarizes runtime behavior patterns of fine-grained LMT functions via online profiling, and leverages differential observability to localize the root cause with minimal production impact. PerfTracker has been deployed as a production service for large-scale GPU clusters of O(10, 000) GPUs (product homepage https://help.aliyun.com/zh/pai/user-guide/perftracker-online-performance-analysis-diagnostic-tool). It has been used to diagnose a variety of difficult performance issues.
TrainMover: Efficient ML Training Live Migration with No Memory Overhead
Dec 17, 2024



Machine learning training has emerged as one of the most prominent workloads in modern data centers. These training jobs are large-scale, long-lasting, and tightly coupled, and are often disrupted by various events in the cluster such as failures, maintenance, and job scheduling. To handle these events, we rely on cold migration, where we first checkpoint the entire cluster, replace the related machines, and then restart the training. This approach leads to disruptions to the training jobs, resulting in significant downtime. In this paper, we present TrainMover, a live migration system that enables machine replacement during machine learning training. TrainMover minimizes downtime by leveraging member replacement of collective communication groups and sandbox lazy initialization. Our evaluation demonstrates that TrainMover achieves 16x less downtime compared to all baselines, effectively handling data center events like straggler rebalancing, maintenance, and unexpected failures.
Cora: Accelerating Stateful Network Applications with SmartNICs
Oct 29, 2024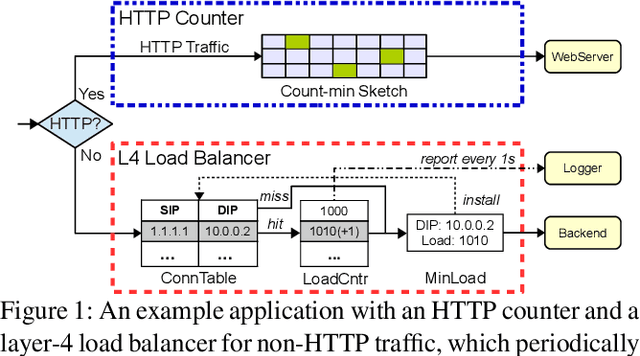
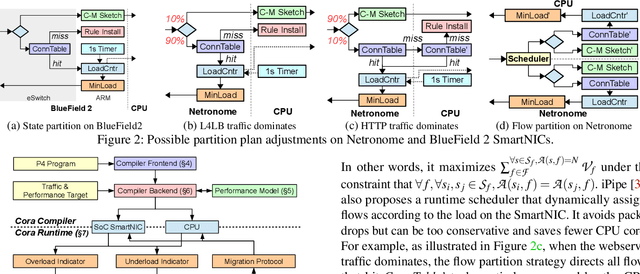
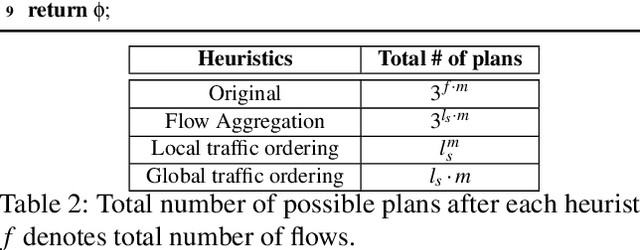
With the growing performance requirements on networked applications, there is a new trend of offloading stateful network applications to SmartNICs to improve performance and reduce the total cost of ownership. However, offloading stateful network applications is non-trivial due to state operation complexity, state resource consumption, and the complicated relationship between traffic and state. Naively partitioning the program by state or traffic can result in a suboptimal partition plan with higher CPU usage or even packet drops. In this paper, we propose Cora, a compiler and runtime that offloads stateful network applications to SmartNIC-accelerated hosts. Cora compiler introduces an accurate performance model for each SmartNIC and employs an efficient compiling algorithm to search the offloading plan. Cora runtime can monitor traffic dynamics and adapt to minimize CPU usage. Cora is built atop Netronome Agilio and BlueField 2 SmartNICs. Our evaluation shows that for the same throughput target, Cora can propose partition plans saving up to 94.0% CPU cores, 1.9 times more than baseline solutions. Under the same resource constraint, Cora can accelerate network functions by 44.9%-82.3%. Cora runtime can adapt to traffic changes and keep CPU usage low.
Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach
Jun 07, 2024


The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model. Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues. Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources. Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestions can greatly increase the waiting time for GPUs. To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are two folds. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction. By leveraging this feature, C4 can rapidly identify the faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection. Second, the predictable communication model of collective communication, involving few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion. C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.