 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Easy and Realistic Network Infrastructure Testing for Large-scale Machine Learning
Apr 29, 2025


This paper lays the foundation for Genie, a testing framework that captures the impact of real hardware network behavior on ML workload performance, without requiring expensive GPUs. Genie uses CPU-initiated traffic over a hardware testbed to emulate GPU to GPU communication, and adapts the ASTRA-sim simulator to model interaction between the network and the ML workload.
TrainMover: Efficient ML Training Live Migration with No Memory Overhead
Dec 17, 2024



Machine learning training has emerged as one of the most prominent workloads in modern data centers. These training jobs are large-scale, long-lasting, and tightly coupled, and are often disrupted by various events in the cluster such as failures, maintenance, and job scheduling. To handle these events, we rely on cold migration, where we first checkpoint the entire cluster, replace the related machines, and then restart the training. This approach leads to disruptions to the training jobs, resulting in significant downtime. In this paper, we present TrainMover, a live migration system that enables machine replacement during machine learning training. TrainMover minimizes downtime by leveraging member replacement of collective communication groups and sandbox lazy initialization. Our evaluation demonstrates that TrainMover achieves 16x less downtime compared to all baselines, effectively handling data center events like straggler rebalancing, maintenance, and unexpected failures.
HawkVision: Low-Latency Modeless Edge AI Serving
May 29, 2024The trend of modeless ML inference is increasingly growing in popularity as it hides the complexity of model inference from users and caters to diverse user and application accuracy requirements. Previous work mostly focuses on modeless inference in data centers. To provide low-latency inference, in this paper, we promote modeless inference at the edge. The edge environment introduces additional challenges related to low power consumption, limited device memory, and volatile network environments. To address these challenges, we propose HawkVision, which provides low-latency modeless serving of vision DNNs. HawkVision leverages a two-layer edge-DC architecture that employs confidence scaling to reduce the number of model options while meeting diverse accuracy requirements. It also supports lossy inference under volatile network environments. Our experimental results show that HawkVision outperforms current serving systems by up to 1.6X in P99 latency for providing modeless service. Our FPGA prototype demonstrates similar performance at certain accuracy levels with up to a 3.34X reduction in power consumption.
THC: Accelerating Distributed Deep Learning Using Tensor Homomorphic Compression
Feb 16, 2023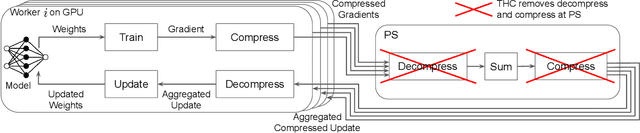

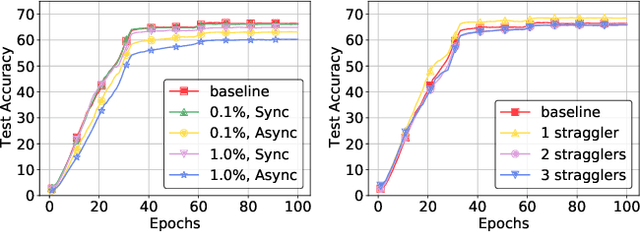
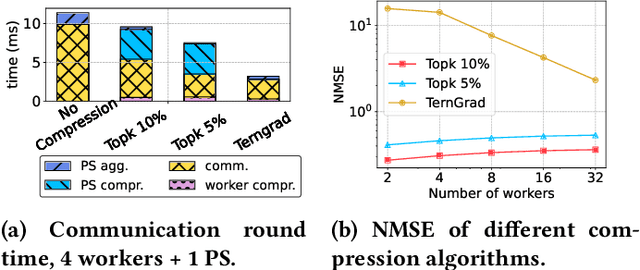
Deep neural networks (DNNs) are the de-facto standard for essential use cases, such as image classification, computer vision, and natural language processing. As DNNs and datasets get larger, they require distributed training on increasingly larger clusters. A main bottleneck is then the resulting communication overhead where workers exchange model updates (i.e., gradients) on a per-round basis. To address this bottleneck and accelerate training, a widely-deployed approach is compression. However, previous deployments often apply bi-directional compression schemes by simply using a uni-directional gradient compression scheme in each direction. This results in significant computational overheads at the parameter server and increased compression error, leading to longer training and lower accuracy. We introduce Tensor Homomorphic Compression (THC), a novel bi-directional compression framework that enables the direct aggregation of compressed values while optimizing the bandwidth to accuracy tradeoff, thus eliminating the aforementioned overheads. Moreover, THC is compatible with in-network aggregation (INA), which allows for further acceleration. Evaluation over a testbed shows that THC improves time-to-accuracy in comparison to alternatives by up to 1.32x with a software PS and up to 1.51x using INA. Finally, we demonstrate that THC is scalable and tolerant for acceptable packet-loss rates.
Efficient Data-Plane Memory Scheduling for In-Network Aggregation
Jan 17, 2022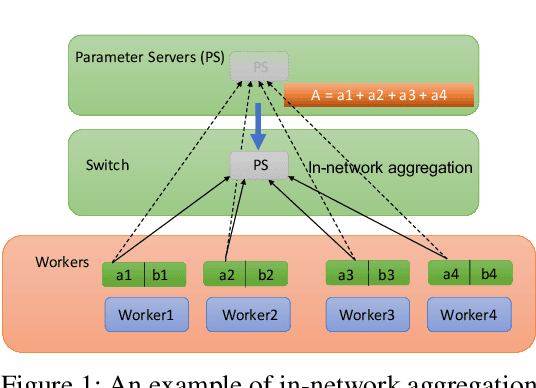

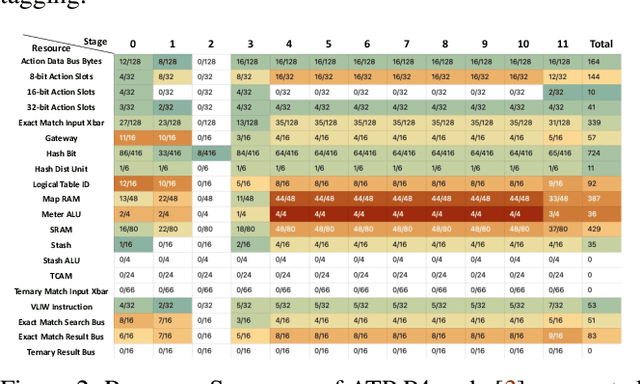
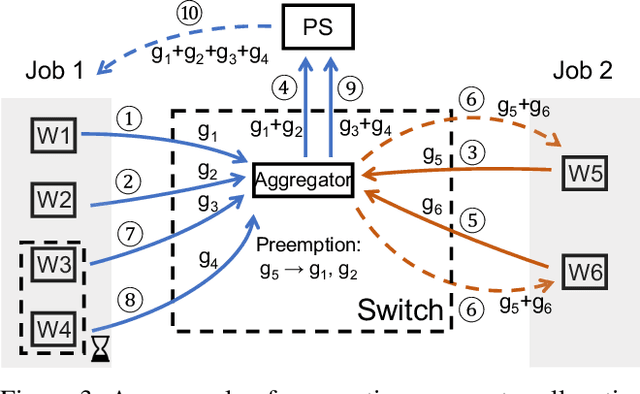
As the scale of distributed training grows, communication becomes a bottleneck. To accelerate the communication, recent works introduce In-Network Aggregation (INA), which moves the gradients summation into network middle-boxes, e.g., programmable switches to reduce the traffic volume. However, switch memory is scarce compared to the volume of gradients transmitted in distributed training. Although literature applies methods like pool-based streaming or dynamic sharing to tackle the mismatch, switch memory is still a potential performance bottleneck. Furthermore, we observe the under-utilization of switch memory due to the synchronization requirement for aggregator deallocation in recent works. To improve the switch memory utilization, we propose ESA, an $\underline{E}$fficient Switch Memory $\underline{S}$cheduler for In-Network $\underline{A}$ggregation. At its cores, ESA enforces the preemptive aggregator allocation primitive and introduces priority scheduling at the data-plane, which improves the switch memory utilization and average job completion time (JCT). Experiments show that ESA can improve the average JCT by up to $1.35\times$.