 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffload or Overload: A Platform Measurement Study of Mobile Robotic Manipulation Workloads
Mar 18, 2026Mobile robotic manipulation--the ability of robots to navigate spaces and interact with objects--is a core capability of physical AI. Foundation models have led to breakthroughs in their performance, but at a significant computational cost. We present the first measurement study of mobile robotic manipulation workloads across onboard, edge, and cloud GPU platforms. We find that the full workload stack is infeasible to run on smaller onboard GPUs, while larger onboard GPUs drain robot batteries several hours faster. Offloading alleviates these constraints but introduces its own challenges, as additional network latency degrades task accuracy, and the bandwidth requirement makes naive cloud offloading impractical. Finally, we quantify opportunities and pitfalls of sharing compute across robot fleets. We believe our measurement study will be crucial to designing inference systems for mobile robots.
EVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025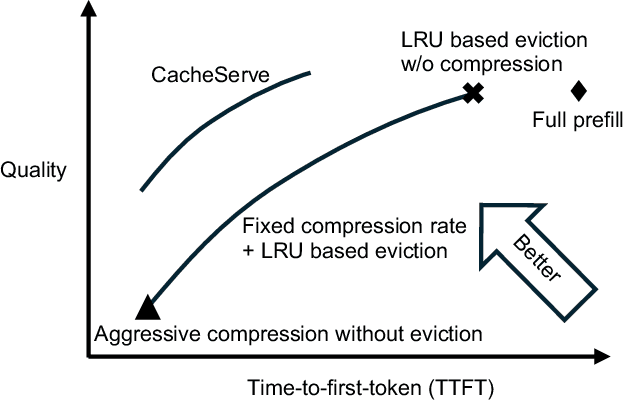
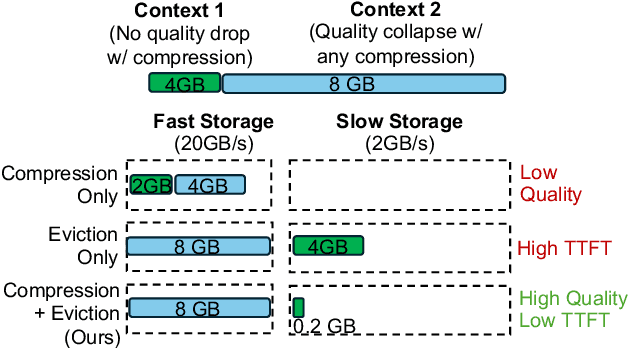
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
Enterprise AI Must Enforce Participant-Aware Access Control
Sep 18, 2025Large language models (LLMs) are increasingly deployed in enterprise settings where they interact with multiple users and are trained or fine-tuned on sensitive internal data. While fine-tuning enhances performance by internalizing domain knowledge, it also introduces a critical security risk: leakage of confidential training data to unauthorized users. These risks are exacerbated when LLMs are combined with Retrieval-Augmented Generation (RAG) pipelines that dynamically fetch contextual documents at inference time. We demonstrate data exfiltration attacks on AI assistants where adversaries can exploit current fine-tuning and RAG architectures to leak sensitive information by leveraging the lack of access control enforcement. We show that existing defenses, including prompt sanitization, output filtering, system isolation, and training-level privacy mechanisms, are fundamentally probabilistic and fail to offer robust protection against such attacks. We take the position that only a deterministic and rigorous enforcement of fine-grained access control during both fine-tuning and RAG-based inference can reliably prevent the leakage of sensitive data to unauthorized recipients. We introduce a framework centered on the principle that any content used in training, retrieval, or generation by an LLM is explicitly authorized for \emph{all users involved in the interaction}. Our approach offers a simple yet powerful paradigm shift for building secure multi-user LLM systems that are grounded in classical access control but adapted to the unique challenges of modern AI workflows. Our solution has been deployed in Microsoft Copilot Tuning, a product offering that enables organizations to fine-tune models using their own enterprise-specific data.
RAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
Dec 13, 2024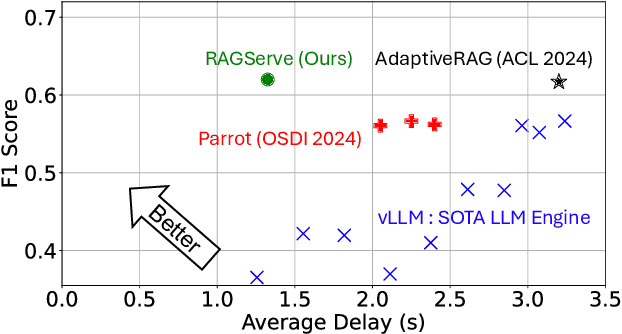

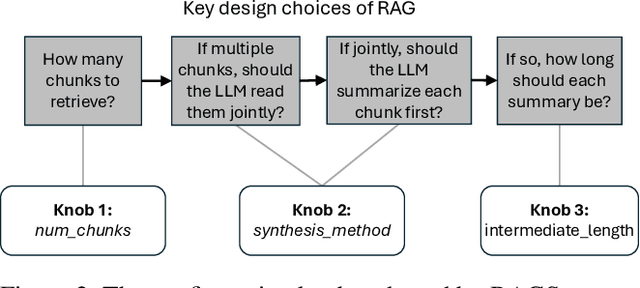
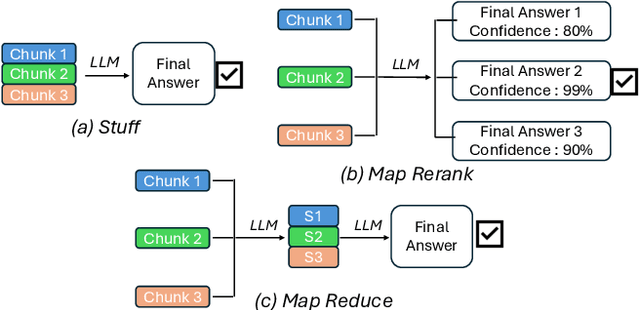
RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.
Distributed AI Platform for the 6G RAN
Oct 01, 2024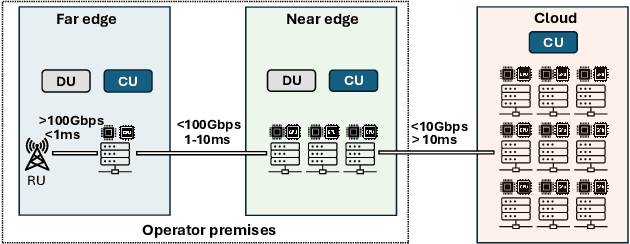
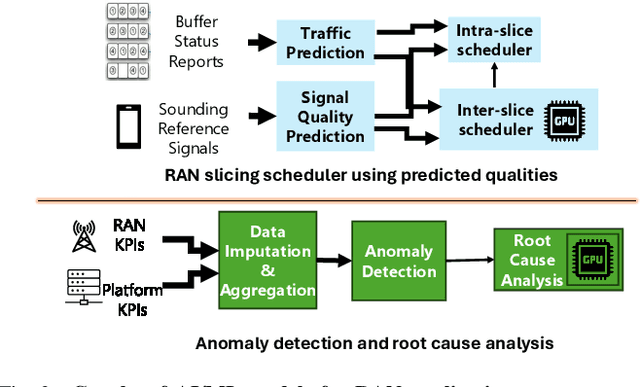
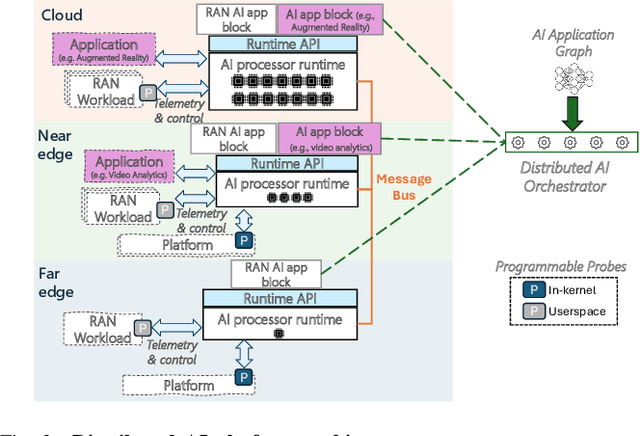
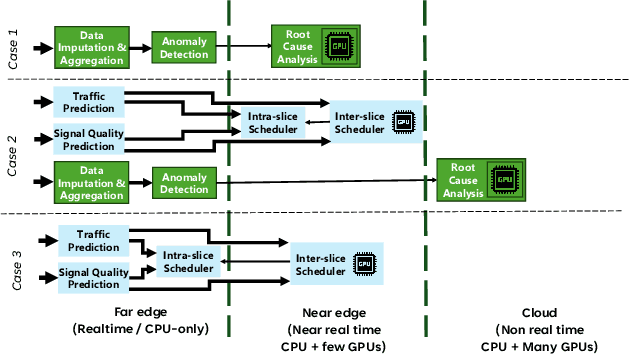
Cellular Radio Access Networks (RANs) are rapidly evolving towards 6G, driven by the need to reduce costs and introduce new revenue streams for operators and enterprises. In this context, AI emerges as a key enabler in solving complex RAN problems spanning both the management and application domains. Unfortunately, and despite the undeniable promise of AI, several practical challenges still remain, hindering the widespread adoption of AI applications in the RAN space. This article attempts to shed light to these challenges and argues that existing approaches in addressing them are inadequate for realizing the vision of a truly AI-native 6G network. Motivated by this lack of solutions, it proposes a generic distributed AI platform architecture, tailored to the needs of an AI-native RAN and discusses its alignment with ongoing standardization efforts.
HawkVision: Low-Latency Modeless Edge AI Serving
May 29, 2024The trend of modeless ML inference is increasingly growing in popularity as it hides the complexity of model inference from users and caters to diverse user and application accuracy requirements. Previous work mostly focuses on modeless inference in data centers. To provide low-latency inference, in this paper, we promote modeless inference at the edge. The edge environment introduces additional challenges related to low power consumption, limited device memory, and volatile network environments. To address these challenges, we propose HawkVision, which provides low-latency modeless serving of vision DNNs. HawkVision leverages a two-layer edge-DC architecture that employs confidence scaling to reduce the number of model options while meeting diverse accuracy requirements. It also supports lossy inference under volatile network environments. Our experimental results show that HawkVision outperforms current serving systems by up to 1.6X in P99 latency for providing modeless service. Our FPGA prototype demonstrates similar performance at certain accuracy levels with up to a 3.34X reduction in power consumption.
CacheGen: Fast Context Loading for Language Model Applications
Oct 11, 2023



As large language models (LLMs) take on more complex tasks, their inputs incorporate longer contexts to respond to questions that require domain knowledge or user-specific conversational histories. Yet, using long contexts poses a challenge for responsive LLM systems, as nothing can be generated until all the contexts are fetched to and processed by the LLM. Existing systems optimize only the computation delay in context processing (e.g., by caching intermediate key-value features of the text context) but often cause longer network delays in context fetching (e.g., key-value features consume orders of magnitude larger bandwidth than the text context). This paper presents CacheGen to minimize the delays in fetching and processing contexts for LLMs. CacheGen reduces the bandwidth needed for transmitting long contexts' key-value (KV) features through a novel encoder that compresses KV features into more compact bitstream representations. The encoder combines adaptive quantization with a tailored arithmetic coder, taking advantage of the KV features' distributional properties, such as locality across tokens. Furthermore, CacheGen minimizes the total delay in fetching and processing a context by using a controller that determines when to load the context as compressed KV features or raw text and picks the appropriate compression level if loaded as KV features. We test CacheGen on three models of various sizes and three datasets of different context lengths. Compared to recent methods that handle long contexts, CacheGen reduces bandwidth usage by 3.7-4.3x and the total delay in fetching and processing contexts by 2.7-3x while maintaining similar LLM performance on various tasks as loading the text contexts.
OneAdapt: Fast Adaptation for Deep Learning Applications via Backpropagation
Oct 03, 2023



Deep learning inference on streaming media data, such as object detection in video or LiDAR feeds and text extraction from audio waves, is now ubiquitous. To achieve high inference accuracy, these applications typically require significant network bandwidth to gather high-fidelity data and extensive GPU resources to run deep neural networks (DNNs). While the high demand for network bandwidth and GPU resources could be substantially reduced by optimally adapting the configuration knobs, such as video resolution and frame rate, current adaptation techniques fail to meet three requirements simultaneously: adapt configurations (i) with minimum extra GPU or bandwidth overhead; (ii) to reach near-optimal decisions based on how the data affects the final DNN's accuracy, and (iii) do so for a range of configuration knobs. This paper presents OneAdapt, which meets these requirements by leveraging a gradient-ascent strategy to adapt configuration knobs. The key idea is to embrace DNNs' differentiability to quickly estimate the accuracy's gradient to each configuration knob, called AccGrad. Specifically, OneAdapt estimates AccGrad by multiplying two gradients: InputGrad (i.e. how each configuration knob affects the input to the DNN) and DNNGrad (i.e. how the DNN input affects the DNN inference output). We evaluate OneAdapt across five types of configurations, four analytic tasks, and five types of input data. Compared to state-of-the-art adaptation schemes, OneAdapt cuts bandwidth usage and GPU usage by 15-59% while maintaining comparable accuracy or improves accuracy by 1-5% while using equal or fewer resources.
GEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022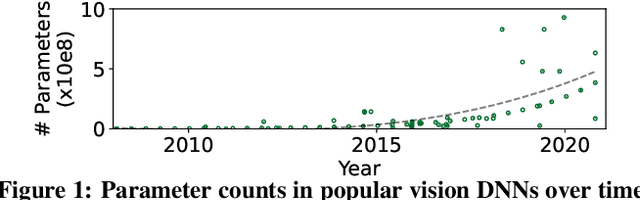
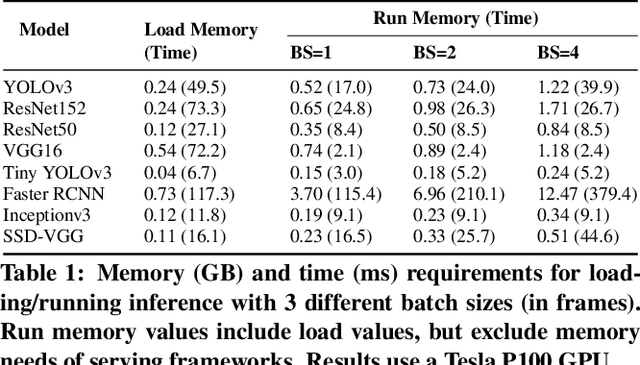
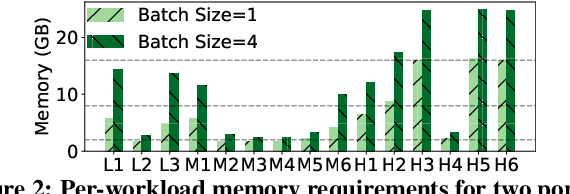

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.
Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers
Dec 19, 2020
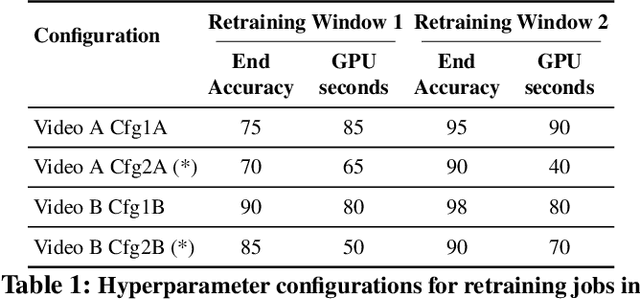
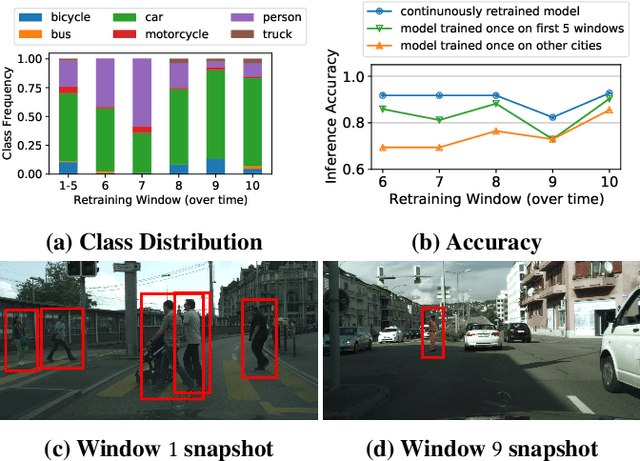

Video analytics applications use edge compute servers for the analytics of the videos (for bandwidth and privacy). Compressed models that are deployed on the edge servers for inference suffer from data drift, where the live video data diverges from the training data. Continuous learning handles data drift by periodically retraining the models on new data. Our work addresses the challenge of jointly supporting inference and retraining tasks on edge servers, which requires navigating the fundamental tradeoff between the retrained model's accuracy and the inference accuracy. Our solution Ekya balances this tradeoff across multiple models and uses a micro-profiler to identify the models that will benefit the most by retraining. Ekya's accuracy gain compared to a baseline scheduler is 29% higher, and the baseline requires 4x more GPU resources to achieve the same accuracy as Ekya.