 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Face Recognition via Improved Localization
May 04, 2025Biometric authentication has become one of the most widely used tools in the current technological era to authenticate users and to distinguish between genuine users and imposters. Face is the most common form of biometric modality that has proven effective. Deep learning-based face recognition systems are now commonly used across different domains. However, these systems usually operate like black-box models that do not provide necessary explanations or justifications for their decisions. This is a major disadvantage because users cannot trust such artificial intelligence-based biometric systems and may not feel comfortable using them when clear explanations or justifications are not provided. This paper addresses this problem by applying an efficient method for explainable face recognition systems. We use a Class Activation Mapping (CAM)-based discriminative localization (very narrow/specific localization) technique called Scaled Directed Divergence (SDD) to visually explain the results of deep learning-based face recognition systems. We perform fine localization of the face features relevant to the deep learning model for its prediction/decision. Our experiments show that the SDD Class Activation Map (CAM) highlights the relevant face features very specifically compared to the traditional CAM and very accurately. The provided visual explanations with narrow localization of relevant features can ensure much-needed transparency and trust for deep learning-based face recognition systems.
Impact of Data Breadth and Depth on Performance of Siamese Neural Network Model: Experiments with Three Keystroke Dynamic Datasets
Jan 10, 2025Deep learning models, such as the Siamese Neural Networks (SNN), have shown great potential in capturing the intricate patterns in behavioral data. However, the impacts of dataset breadth (i.e., the number of subjects) and depth (e.g., the amount of training samples per subject) on the performance of these models is often informally assumed, and remains under-explored. To this end, we have conducted extensive experiments using the concepts of "feature space" and "density" to guide and gain deeper understanding on the impact of dataset breadth and depth on three publicly available keystroke datasets (Aalto, CMU and Clarkson II). Through varying the number of training subjects, number of samples per subject, amount of data in each sample, and number of triplets used in training, we found that when feasible, increasing dataset breadth enables the training of a well-trained model that effectively captures more inter-subject variability. In contrast, we find that the extent of depth's impact from a dataset depends on the nature of the dataset. Free-text datasets are influenced by all three depth-wise factors; inadequate samples per subject, sequence length, training triplets and gallery sample size, which may all lead to an under-trained model. Fixed-text datasets are less affected by these factors, and as such make it easier to create a well-trained model. These findings shed light on the importance of dataset breadth and depth in training deep learning models for behavioral biometrics and provide valuable insights for designing more effective authentication systems.
Deep Learning-Based Approaches for Contactless Fingerprints Segmentation and Extraction
Nov 26, 2023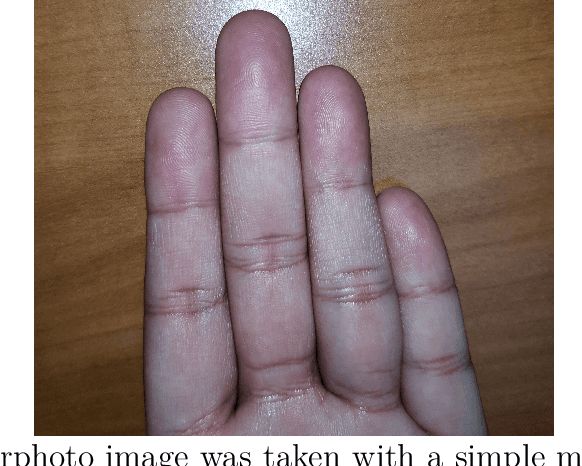

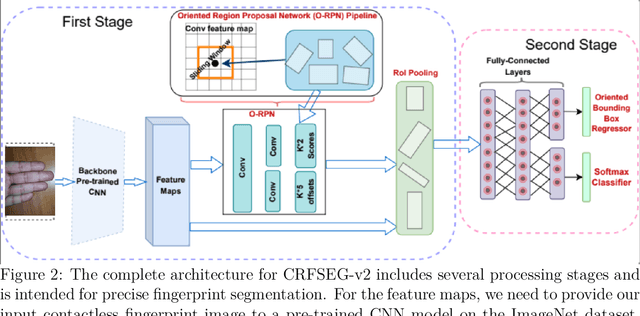
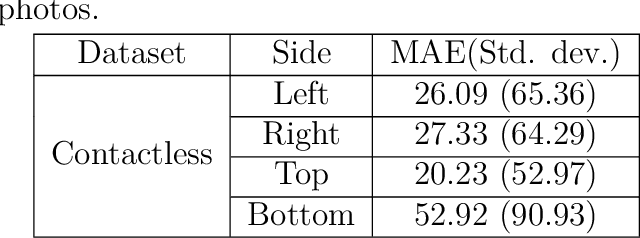
Fingerprints are widely recognized as one of the most unique and reliable characteristics of human identity. Most modern fingerprint authentication systems rely on contact-based fingerprints, which require the use of fingerprint scanners or fingerprint sensors for capturing fingerprints during the authentication process. Various types of fingerprint sensors, such as optical, capacitive, and ultrasonic sensors, employ distinct techniques to gather and analyze fingerprint data. This dependency on specific hardware or sensors creates a barrier or challenge for the broader adoption of fingerprint based biometric systems. This limitation hinders the widespread adoption of fingerprint authentication in various applications and scenarios. Border control, healthcare systems, educational institutions, financial transactions, and airport security face challenges when fingerprint sensors are not universally available. To mitigate the dependence on additional hardware, the use of contactless fingerprints has emerged as an alternative. Developing precise fingerprint segmentation methods, accurate fingerprint extraction tools, and reliable fingerprint matchers are crucial for the successful implementation of a robust contactless fingerprint authentication system. This paper focuses on the development of a deep learning-based segmentation tool for contactless fingerprint localization and segmentation. Our system leverages deep learning techniques to achieve high segmentation accuracy and reliable extraction of fingerprints from contactless fingerprint images. In our evaluation, our segmentation method demonstrated an average mean absolute error (MAE) of 30 pixels, an error in angle prediction (EAP) of 5.92 degrees, and a labeling accuracy of 97.46%. These results demonstrate the effectiveness of our novel contactless fingerprint segmentation and extraction tools.
Machine Learning at the Network Edge: A Survey
Jul 31, 2019
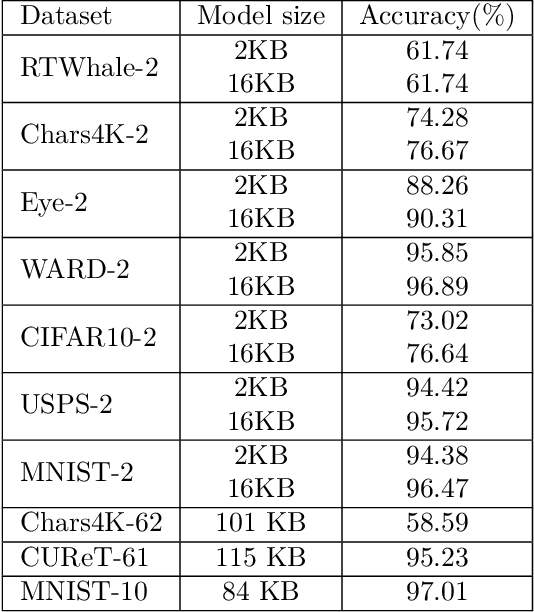
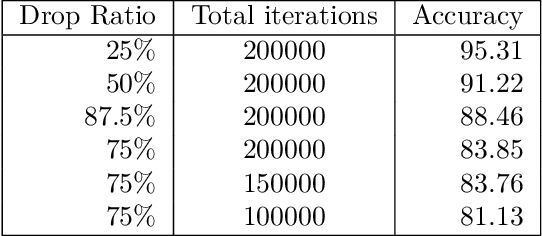
Devices comprising the Internet of Things, such as sensors and small cameras, usually have small memories and limited computational power. The proliferation of such resource-constrained devices in recent years has led to the generation of large quantities of data. These data-producing devices are appealing targets for machine learning applications but struggle to run machine learning algorithms due to their limited computing capability. They typically offload input data to external computing systems (such as cloud servers) for further processing. The results of the machine learning computations are communicated back to the resource-scarce devices, but this worsens latency, leads to increased communication costs, and adds to privacy concerns. Therefore, efforts have been made to place additional computing devices at the edge of the network, i.e close to the IoT devices where the data is generated. Deploying machine learning systems on such edge devices alleviates the above issues by allowing computations to be performed close to the data sources. This survey describes major research efforts where machine learning has been deployed at the edge of computer networks.