 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARGAN: Spatial Attention-based Residuals for Facial Expression Manipulation
Mar 30, 2023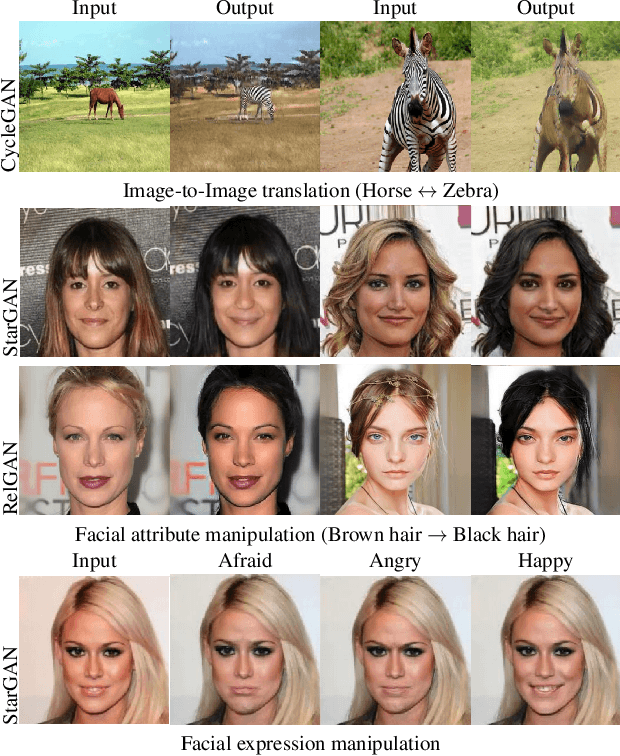
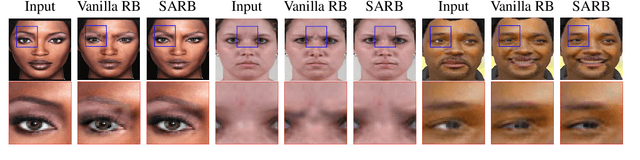


Encoder-decoder based architecture has been widely used in the generator of generative adversarial networks for facial manipulation. However, we observe that the current architecture fails to recover the input image color, rich facial details such as skin color or texture and introduces artifacts as well. In this paper, we present a novel method named SARGAN that addresses the above-mentioned limitations from three perspectives. First, we employed spatial attention-based residual block instead of vanilla residual blocks to properly capture the expression-related features to be changed while keeping the other features unchanged. Second, we exploited a symmetric encoder-decoder network to attend facial features at multiple scales. Third, we proposed to train the complete network with a residual connection which relieves the generator of pressure to generate the input face image thereby producing the desired expression by directly feeding the input image towards the end of the generator. Both qualitative and quantitative experimental results show that our proposed model performs significantly better than state-of-the-art methods. In addition, existing models require much larger datasets for training but their performance degrades on out-of-distribution images. In contrast, SARGAN can be trained on smaller facial expressions datasets, which generalizes well on out-of-distribution images including human photographs, portraits, avatars and statues.
US-GAN: On the importance of Ultimate Skip Connection for Facial Expression Synthesis
Dec 24, 2021


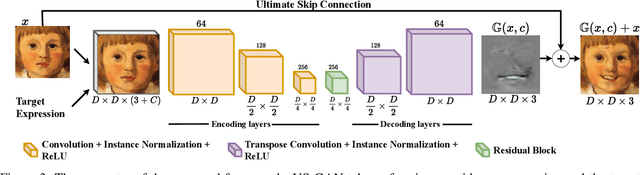
Recent studies have shown impressive results in multi-domain image-to-image translation for facial expression synthesis. While effective, these methods require a large number of labelled samples for plausible results. Their performance significantly degrades when we train them on smaller datasets. To address this limitation, in this work, we present US-GAN, a smaller and effective method for synthesizing plausible expressions by employing notably smaller datasets. The proposed method comprises of encoding layers, single residual block, decoding layers and an ultimate skip connection that links the input image to an output image. It has three times lesser parameters as compared to state-of-the-art facial expression synthesis methods. Experimental results demonstrate the quantitative and qualitative effectiveness of our proposed method. In addition, we also show that an ultimate skip connection is sufficient for recovering rich facial and overall color details of the input face image that a larger state-of-the-art model fails to recover.
CALText: Contextual Attention Localization for Offline Handwritten Text
Nov 06, 2021

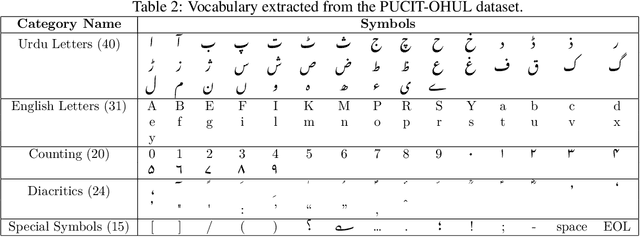
Recognition of Arabic-like scripts such as Persian and Urdu is more challenging than Latin-based scripts. This is due to the presence of a two-dimensional structure, context-dependent character shapes, spaces and overlaps, and placement of diacritics. Not much research exists for offline handwritten Urdu script which is the 10th most spoken language in the world. We present an attention based encoder-decoder model that learns to read Urdu in context. A novel localization penalty is introduced to encourage the model to attend only one location at a time when recognizing the next character. In addition, we comprehensively refine the only complete and publicly available handwritten Urdu dataset in terms of ground-truth annotations. We evaluate the model on both Urdu and Arabic datasets and show that contextual attention localization outperforms both simple attention and multi-directional LSTM models.
Pulmonary Disease Classification Using Globally Correlated Maximum Likelihood: an Auxiliary Attention mechanism for Convolutional Neural Networks
Sep 01, 2021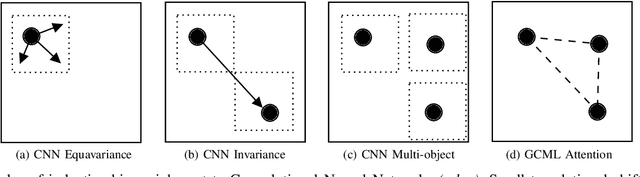



Convolutional neural networks (CNN) are now being widely used for classifying and detecting pulmonary abnormalities in chest radiographs. Two complementary generalization properties of CNNs, translation invariance and equivariance, are particularly useful in detecting manifested abnormalities associated with pulmonary disease, regardless of their spatial locations within the image. However, these properties also come with the loss of exact spatial information and global relative positions of abnormalities detected in local regions. Global relative positions of such abnormalities may help distinguish similar conditions, such as COVID-19 and viral pneumonia. In such instances, a global attention mechanism is needed, which CNNs do not support in their traditional architectures that aim for generalization afforded by translation invariance and equivariance. Vision Transformers provide a global attention mechanism, but lack translation invariance and equivariance, requiring significantly more training data samples to match generalization of CNNs. To address the loss of spatial information and global relations between features, while preserving the inductive biases of CNNs, we present a novel technique that serves as an auxiliary attention mechanism to existing CNN architectures, in order to extract global correlations between salient features.
Masked Linear Regression for Learning Local Receptive Fields for Facial Expression Synthesis
Nov 18, 2020

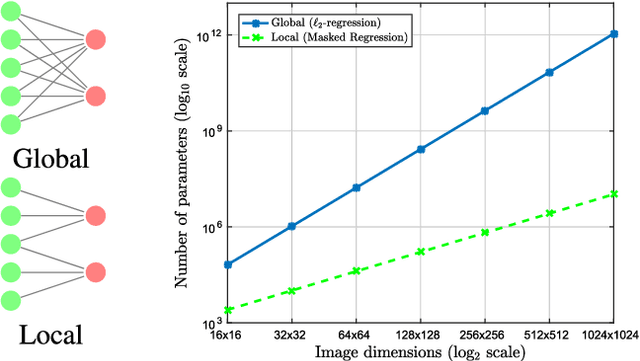

Compared to facial expression recognition, expression synthesis requires a very high-dimensional mapping. This problem exacerbates with increasing image sizes and limits existing expression synthesis approaches to relatively small images. We observe that facial expressions often constitute sparsely distributed and locally correlated changes from one expression to another. By exploiting this observation, the number of parameters in an expression synthesis model can be significantly reduced. Therefore, we propose a constrained version of ridge regression that exploits the local and sparse structure of facial expressions. We consider this model as masked regression for learning local receptive fields. In contrast to the existing approaches, our proposed model can be efficiently trained on larger image sizes. Experiments using three publicly available datasets demonstrate that our model is significantly better than $\ell_0, \ell_1$ and $\ell_2$-regression, SVD based approaches, and kernelized regression in terms of mean-squared-error, visual quality as well as computational and spatial complexities. The reduction in the number of parameters allows our method to generalize better even after training on smaller datasets. The proposed algorithm is also compared with state-of-the-art GANs including Pix2Pix, CycleGAN, StarGAN and GANimation. These GANs produce photo-realistic results as long as the testing and the training distributions are similar. In contrast, our results demonstrate significant generalization of the proposed algorithm over out-of-dataset human photographs, pencil sketches and even animal faces.
* IJCV Journal
Pixel-based Facial Expression Synthesis
Oct 27, 2020
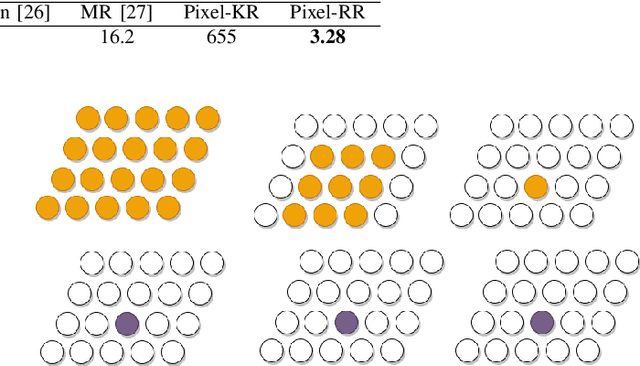


Facial expression synthesis has achieved remarkable advances with the advent of Generative Adversarial Networks (GANs). However, GAN-based approaches mostly generate photo-realistic results as long as the testing data distribution is close to the training data distribution. The quality of GAN results significantly degrades when testing images are from a slightly different distribution. Moreover, recent work has shown that facial expressions can be synthesized by changing localized face regions. In this work, we propose a pixel-based facial expression synthesis method in which each output pixel observes only one input pixel. The proposed method achieves good generalization capability by leveraging only a few hundred training images. Experimental results demonstrate that the proposed method performs comparably well against state-of-the-art GANs on in-dataset images and significantly better on out-of-dataset images. In addition, the proposed model is two orders of magnitude smaller which makes it suitable for deployment on resource-constrained devices.
Improving Explainability of Image Classification in Scenarios with Class Overlap: Application to COVID-19 and Pneumonia
Aug 16, 2020
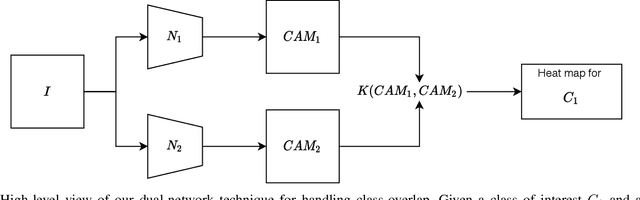

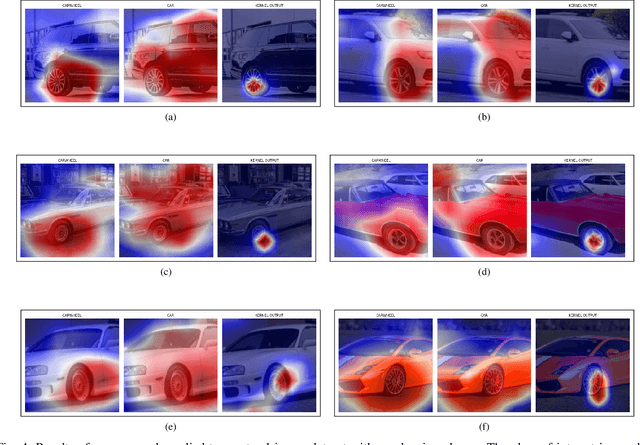
Trust in predictions made by machine learning models is increased if the model generalizes well on previously unseen samples and when inference is accompanied by cogent explanations of the reasoning behind predictions. In the image classification domain, generalization can be assessed through accuracy, sensitivity, and specificity. Explainability can be assessed by how well the model localizes the object of interest within an image. However, both generalization and explainability through localization are degraded in scenarios with significant overlap between classes. We propose a method based on binary expert networks that enhances the explainability of image classifications through better localization by mitigating the model uncertainty induced by class overlap. Our technique performs discriminative localization on images that contain features with significant class overlap, without explicitly training for localization. Our method is particularly promising in real-world class overlap scenarios, such as COVID-19 and pneumonia, where expertly labeled data for localization is not readily available. This can be useful for early, rapid, and trustworthy screening for COVID-19.
Hazard Detection in Supermarkets using Deep Learning on the Edge
Feb 29, 2020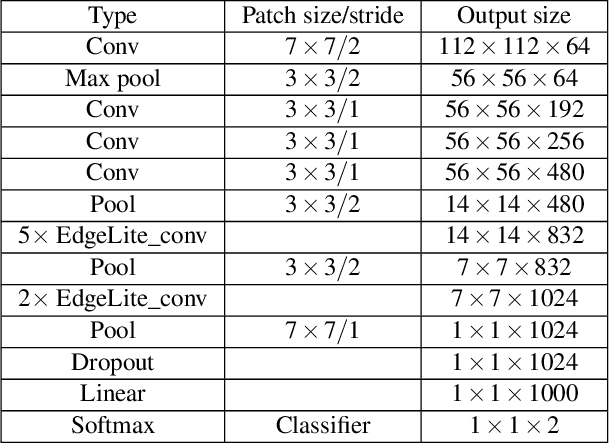

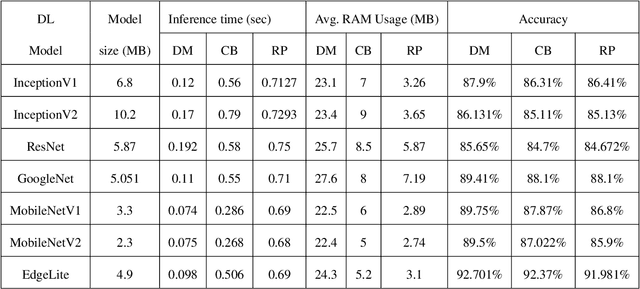
Supermarkets need to ensure clean and safe environments for both shoppers and employees. Slips, trips, and falls can result in injuries that have a physical as well as financial cost. Timely detection of hazardous conditions such as spilled liquids or fallen items on supermarket floors can reduce the chances of serious injuries. This paper presents EdgeLite, a novel, lightweight deep learning model for easy deployment and inference on resource-constrained devices. We describe the use of EdgeLite on two edge devices for detecting supermarket floor hazards. On a hazard detection dataset that we developed, EdgeLite, when deployed on edge devices, outperformed six state-of-the-art object detection models in terms of accuracy while having comparable memory usage and inference time.
Machine Learning at the Network Edge: A Survey
Jul 31, 2019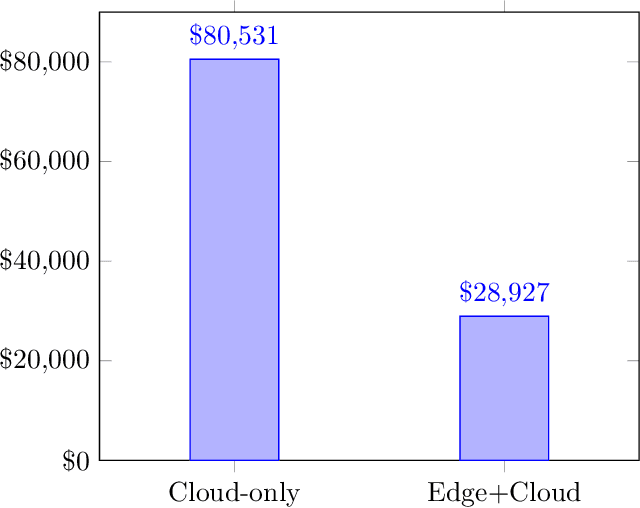
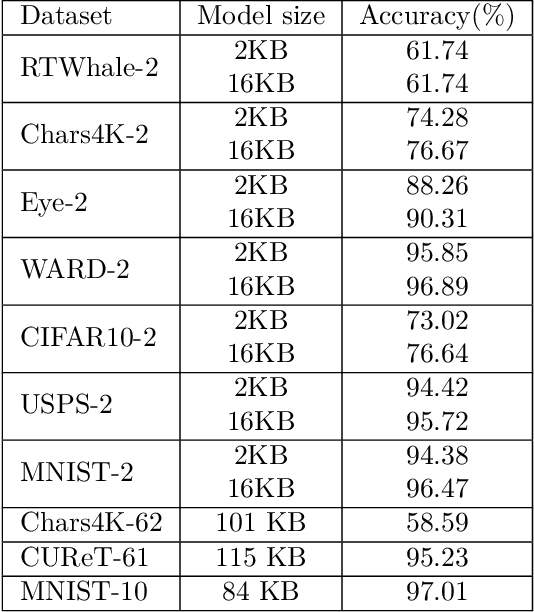
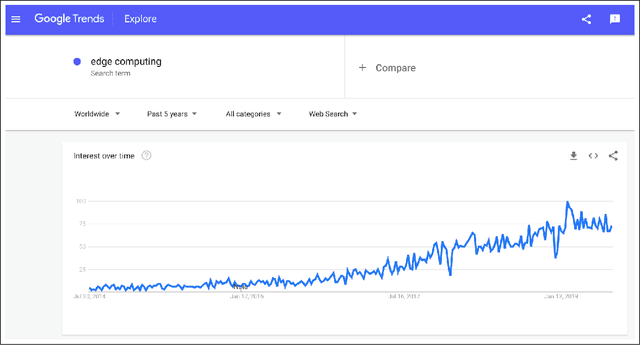
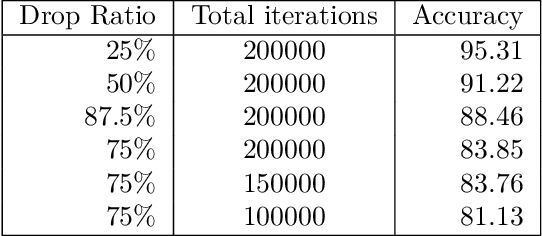
Devices comprising the Internet of Things, such as sensors and small cameras, usually have small memories and limited computational power. The proliferation of such resource-constrained devices in recent years has led to the generation of large quantities of data. These data-producing devices are appealing targets for machine learning applications but struggle to run machine learning algorithms due to their limited computing capability. They typically offload input data to external computing systems (such as cloud servers) for further processing. The results of the machine learning computations are communicated back to the resource-scarce devices, but this worsens latency, leads to increased communication costs, and adds to privacy concerns. Therefore, efforts have been made to place additional computing devices at the edge of the network, i.e close to the IoT devices where the data is generated. Deploying machine learning systems on such edge devices alleviates the above issues by allowing computations to be performed close to the data sources. This survey describes major research efforts where machine learning has been deployed at the edge of computer networks.