 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Linear Regression for Learning Local Receptive Fields for Facial Expression Synthesis
Paper and Code


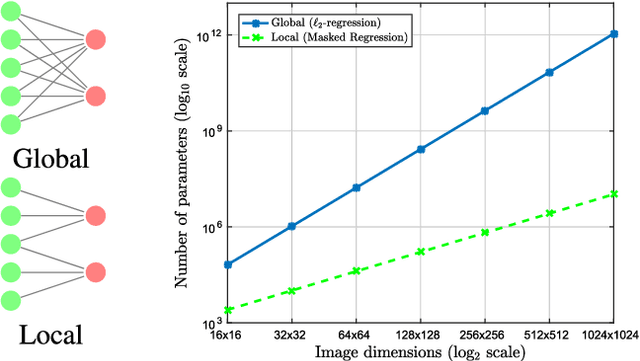

Compared to facial expression recognition, expression synthesis requires a very high-dimensional mapping. This problem exacerbates with increasing image sizes and limits existing expression synthesis approaches to relatively small images. We observe that facial expressions often constitute sparsely distributed and locally correlated changes from one expression to another. By exploiting this observation, the number of parameters in an expression synthesis model can be significantly reduced. Therefore, we propose a constrained version of ridge regression that exploits the local and sparse structure of facial expressions. We consider this model as masked regression for learning local receptive fields. In contrast to the existing approaches, our proposed model can be efficiently trained on larger image sizes. Experiments using three publicly available datasets demonstrate that our model is significantly better than $\ell_0, \ell_1$ and $\ell_2$-regression, SVD based approaches, and kernelized regression in terms of mean-squared-error, visual quality as well as computational and spatial complexities. The reduction in the number of parameters allows our method to generalize better even after training on smaller datasets. The proposed algorithm is also compared with state-of-the-art GANs including Pix2Pix, CycleGAN, StarGAN and GANimation. These GANs produce photo-realistic results as long as the testing and the training distributions are similar. In contrast, our results demonstrate significant generalization of the proposed algorithm over out-of-dataset human photographs, pencil sketches and even animal faces.