 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARGAN: Spatial Attention-based Residuals for Facial Expression Manipulation
Mar 30, 2023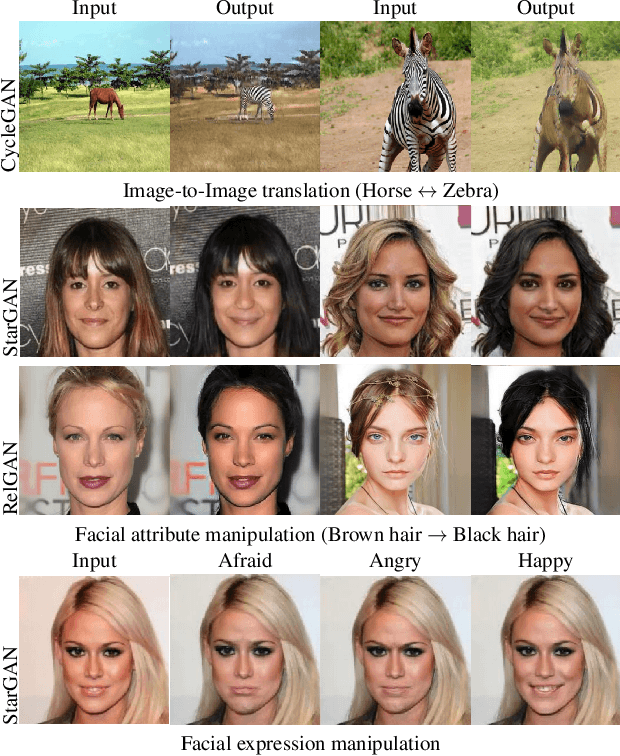


Encoder-decoder based architecture has been widely used in the generator of generative adversarial networks for facial manipulation. However, we observe that the current architecture fails to recover the input image color, rich facial details such as skin color or texture and introduces artifacts as well. In this paper, we present a novel method named SARGAN that addresses the above-mentioned limitations from three perspectives. First, we employed spatial attention-based residual block instead of vanilla residual blocks to properly capture the expression-related features to be changed while keeping the other features unchanged. Second, we exploited a symmetric encoder-decoder network to attend facial features at multiple scales. Third, we proposed to train the complete network with a residual connection which relieves the generator of pressure to generate the input face image thereby producing the desired expression by directly feeding the input image towards the end of the generator. Both qualitative and quantitative experimental results show that our proposed model performs significantly better than state-of-the-art methods. In addition, existing models require much larger datasets for training but their performance degrades on out-of-distribution images. In contrast, SARGAN can be trained on smaller facial expressions datasets, which generalizes well on out-of-distribution images including human photographs, portraits, avatars and statues.
US-GAN: On the importance of Ultimate Skip Connection for Facial Expression Synthesis
Dec 24, 2021


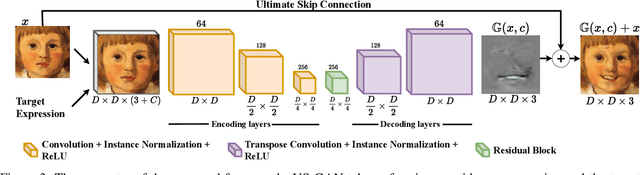
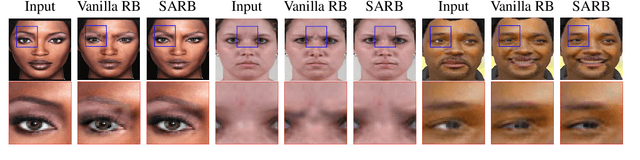
Recent studies have shown impressive results in multi-domain image-to-image translation for facial expression synthesis. While effective, these methods require a large number of labelled samples for plausible results. Their performance significantly degrades when we train them on smaller datasets. To address this limitation, in this work, we present US-GAN, a smaller and effective method for synthesizing plausible expressions by employing notably smaller datasets. The proposed method comprises of encoding layers, single residual block, decoding layers and an ultimate skip connection that links the input image to an output image. It has three times lesser parameters as compared to state-of-the-art facial expression synthesis methods. Experimental results demonstrate the quantitative and qualitative effectiveness of our proposed method. In addition, we also show that an ultimate skip connection is sufficient for recovering rich facial and overall color details of the input face image that a larger state-of-the-art model fails to recover.
Masked Linear Regression for Learning Local Receptive Fields for Facial Expression Synthesis
Nov 18, 2020

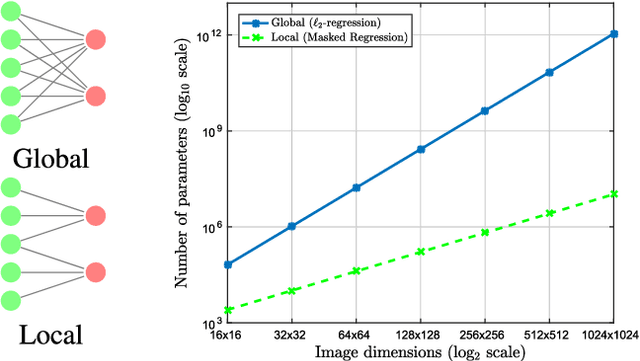

Compared to facial expression recognition, expression synthesis requires a very high-dimensional mapping. This problem exacerbates with increasing image sizes and limits existing expression synthesis approaches to relatively small images. We observe that facial expressions often constitute sparsely distributed and locally correlated changes from one expression to another. By exploiting this observation, the number of parameters in an expression synthesis model can be significantly reduced. Therefore, we propose a constrained version of ridge regression that exploits the local and sparse structure of facial expressions. We consider this model as masked regression for learning local receptive fields. In contrast to the existing approaches, our proposed model can be efficiently trained on larger image sizes. Experiments using three publicly available datasets demonstrate that our model is significantly better than $\ell_0, \ell_1$ and $\ell_2$-regression, SVD based approaches, and kernelized regression in terms of mean-squared-error, visual quality as well as computational and spatial complexities. The reduction in the number of parameters allows our method to generalize better even after training on smaller datasets. The proposed algorithm is also compared with state-of-the-art GANs including Pix2Pix, CycleGAN, StarGAN and GANimation. These GANs produce photo-realistic results as long as the testing and the training distributions are similar. In contrast, our results demonstrate significant generalization of the proposed algorithm over out-of-dataset human photographs, pencil sketches and even animal faces.
* IJCV Journal
Pixel-based Facial Expression Synthesis
Oct 27, 2020
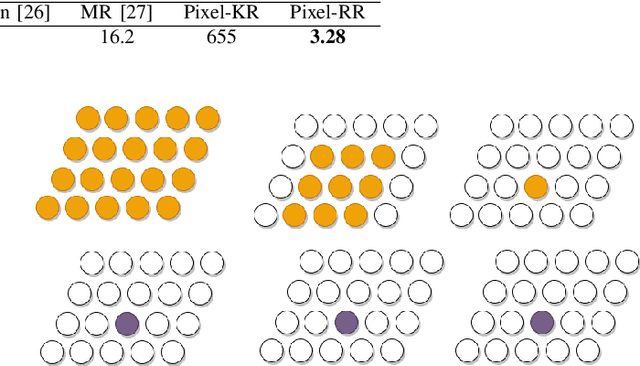


Facial expression synthesis has achieved remarkable advances with the advent of Generative Adversarial Networks (GANs). However, GAN-based approaches mostly generate photo-realistic results as long as the testing data distribution is close to the training data distribution. The quality of GAN results significantly degrades when testing images are from a slightly different distribution. Moreover, recent work has shown that facial expressions can be synthesized by changing localized face regions. In this work, we propose a pixel-based facial expression synthesis method in which each output pixel observes only one input pixel. The proposed method achieves good generalization capability by leveraging only a few hundred training images. Experimental results demonstrate that the proposed method performs comparably well against state-of-the-art GANs on in-dataset images and significantly better on out-of-dataset images. In addition, the proposed model is two orders of magnitude smaller which makes it suitable for deployment on resource-constrained devices.