 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUS-GAN: On the importance of Ultimate Skip Connection for Facial Expression Synthesis
Paper and Code



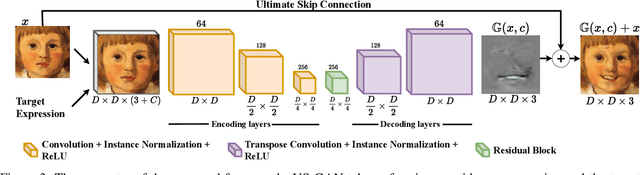
Recent studies have shown impressive results in multi-domain image-to-image translation for facial expression synthesis. While effective, these methods require a large number of labelled samples for plausible results. Their performance significantly degrades when we train them on smaller datasets. To address this limitation, in this work, we present US-GAN, a smaller and effective method for synthesizing plausible expressions by employing notably smaller datasets. The proposed method comprises of encoding layers, single residual block, decoding layers and an ultimate skip connection that links the input image to an output image. It has three times lesser parameters as compared to state-of-the-art facial expression synthesis methods. Experimental results demonstrate the quantitative and qualitative effectiveness of our proposed method. In addition, we also show that an ultimate skip connection is sufficient for recovering rich facial and overall color details of the input face image that a larger state-of-the-art model fails to recover.