 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Face Recognition via Improved Localization
May 04, 2025Biometric authentication has become one of the most widely used tools in the current technological era to authenticate users and to distinguish between genuine users and imposters. Face is the most common form of biometric modality that has proven effective. Deep learning-based face recognition systems are now commonly used across different domains. However, these systems usually operate like black-box models that do not provide necessary explanations or justifications for their decisions. This is a major disadvantage because users cannot trust such artificial intelligence-based biometric systems and may not feel comfortable using them when clear explanations or justifications are not provided. This paper addresses this problem by applying an efficient method for explainable face recognition systems. We use a Class Activation Mapping (CAM)-based discriminative localization (very narrow/specific localization) technique called Scaled Directed Divergence (SDD) to visually explain the results of deep learning-based face recognition systems. We perform fine localization of the face features relevant to the deep learning model for its prediction/decision. Our experiments show that the SDD Class Activation Map (CAM) highlights the relevant face features very specifically compared to the traditional CAM and very accurately. The provided visual explanations with narrow localization of relevant features can ensure much-needed transparency and trust for deep learning-based face recognition systems.
Deep Learning-Based Approaches for Contactless Fingerprints Segmentation and Extraction
Nov 26, 2023

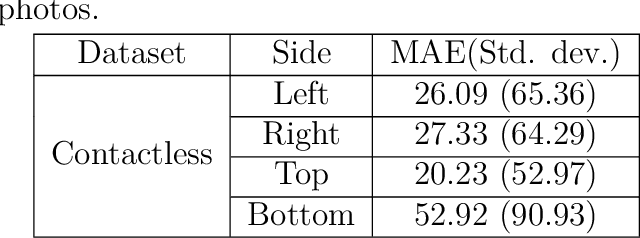
Fingerprints are widely recognized as one of the most unique and reliable characteristics of human identity. Most modern fingerprint authentication systems rely on contact-based fingerprints, which require the use of fingerprint scanners or fingerprint sensors for capturing fingerprints during the authentication process. Various types of fingerprint sensors, such as optical, capacitive, and ultrasonic sensors, employ distinct techniques to gather and analyze fingerprint data. This dependency on specific hardware or sensors creates a barrier or challenge for the broader adoption of fingerprint based biometric systems. This limitation hinders the widespread adoption of fingerprint authentication in various applications and scenarios. Border control, healthcare systems, educational institutions, financial transactions, and airport security face challenges when fingerprint sensors are not universally available. To mitigate the dependence on additional hardware, the use of contactless fingerprints has emerged as an alternative. Developing precise fingerprint segmentation methods, accurate fingerprint extraction tools, and reliable fingerprint matchers are crucial for the successful implementation of a robust contactless fingerprint authentication system. This paper focuses on the development of a deep learning-based segmentation tool for contactless fingerprint localization and segmentation. Our system leverages deep learning techniques to achieve high segmentation accuracy and reliable extraction of fingerprints from contactless fingerprint images. In our evaluation, our segmentation method demonstrated an average mean absolute error (MAE) of 30 pixels, an error in angle prediction (EAP) of 5.92 degrees, and a labeling accuracy of 97.46%. These results demonstrate the effectiveness of our novel contactless fingerprint segmentation and extraction tools.
Deep Age-Invariant Fingerprint Segmentation System
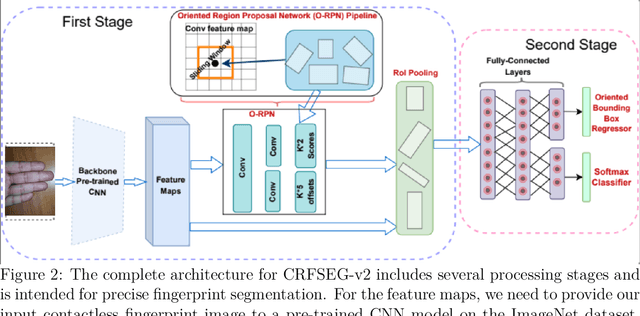
Mar 06, 2023Fingerprint-based identification systems achieve higher accuracy when a slap containing multiple fingerprints of a subject is used instead of a single fingerprint. However, segmenting or auto-localizing all fingerprints in a slap image is a challenging task due to the different orientations of fingerprints, noisy backgrounds, and the smaller size of fingertip components. The presence of slap images in a real-world dataset where one or more fingerprints are rotated makes it challenging for a biometric recognition system to localize and label the fingerprints automatically. Improper fingerprint localization and finger labeling errors lead to poor matching performance. In this paper, we introduce a method to generate arbitrary angled bounding boxes using a deep learning-based algorithm that precisely localizes and labels fingerprints from both axis-aligned and over-rotated slap images. We built a fingerprint segmentation model named CRFSEG (Clarkson Rotated Fingerprint segmentation Model) by updating the previously proposed CFSEG model which was based on traditional Faster R-CNN architecture [21]. CRFSEG improves upon the Faster R-CNN algorithm with arbitrarily angled bounding boxes that allow the CRFSEG to perform better in challenging slap images. After training the CRFSEG algorithm on a new dataset containing slap images collected from both adult and children subjects, our results suggest that the CRFSEG model was invariant across different age groups and can handle over-rotated slap images successfully. In the Combined dataset containing both normal and rotated images of adult and children subjects, we achieved a matching accuracy of 97.17%, which outperformed state-of-the-art VeriFinger (94.25%) and NFSEG segmentation systems (80.58%).
Deep Slap Fingerprint Segmentation for Juveniles and Adults
Oct 06, 2021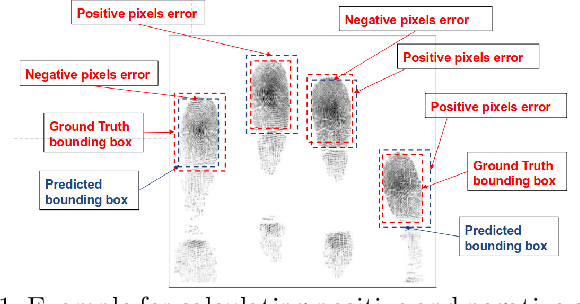
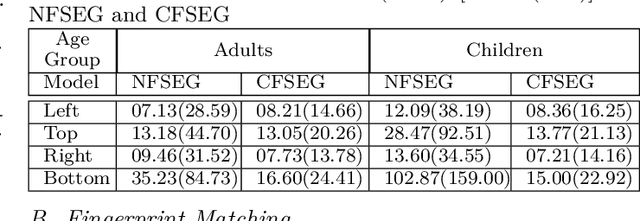
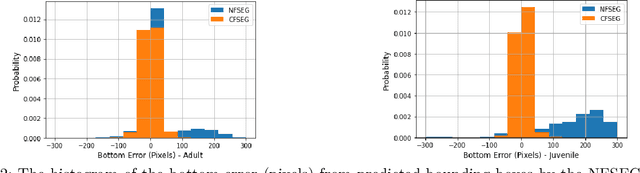
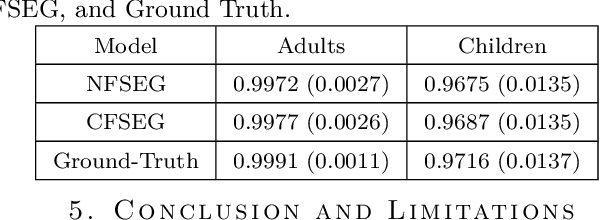
Many fingerprint recognition systems capture four fingerprints in one image. In such systems, the fingerprint processing pipeline must first segment each four-fingerprint slap into individual fingerprints. Note that most of the current fingerprint segmentation algorithms have been designed and evaluated using only adult fingerprint datasets. In this work, we have developed a human-annotated in-house dataset of 15790 slaps of which 9084 are adult samples and 6706 are samples drawn from children from ages 4 to 12. Subsequently, the dataset is used to evaluate the matching performance of the NFSEG, a slap fingerprint segmentation system developed by NIST, on slaps from adults and juvenile subjects. Our results reveal the lower performance of NFSEG on slaps from juvenile subjects. Finally, we utilized our novel dataset to develop the Mask-RCNN based Clarkson Fingerprint Segmentation (CFSEG). Our matching results using the Verifinger fingerprint matcher indicate that CFSEG outperforms NFSEG for both adults and juvenile slaps. The CFSEG model is publicly available at \url{https://github.com/keivanB/Clarkson_Finger_Segment}
Pulmonary Disease Classification Using Globally Correlated Maximum Likelihood: an Auxiliary Attention mechanism for Convolutional Neural Networks
Sep 01, 2021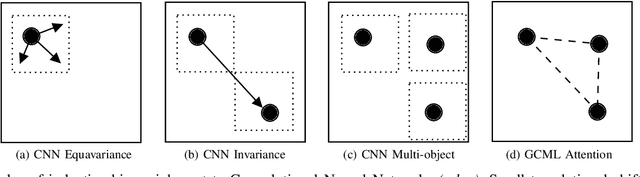



Convolutional neural networks (CNN) are now being widely used for classifying and detecting pulmonary abnormalities in chest radiographs. Two complementary generalization properties of CNNs, translation invariance and equivariance, are particularly useful in detecting manifested abnormalities associated with pulmonary disease, regardless of their spatial locations within the image. However, these properties also come with the loss of exact spatial information and global relative positions of abnormalities detected in local regions. Global relative positions of such abnormalities may help distinguish similar conditions, such as COVID-19 and viral pneumonia. In such instances, a global attention mechanism is needed, which CNNs do not support in their traditional architectures that aim for generalization afforded by translation invariance and equivariance. Vision Transformers provide a global attention mechanism, but lack translation invariance and equivariance, requiring significantly more training data samples to match generalization of CNNs. To address the loss of spatial information and global relations between features, while preserving the inductive biases of CNNs, we present a novel technique that serves as an auxiliary attention mechanism to existing CNN architectures, in order to extract global correlations between salient features.
Improving Explainability of Image Classification in Scenarios with Class Overlap: Application to COVID-19 and Pneumonia
Aug 16, 2020
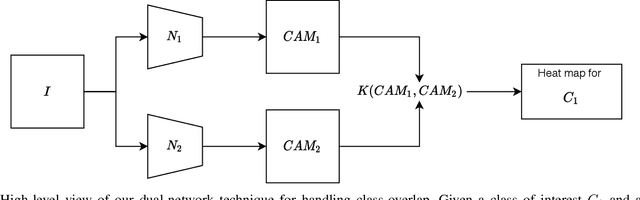

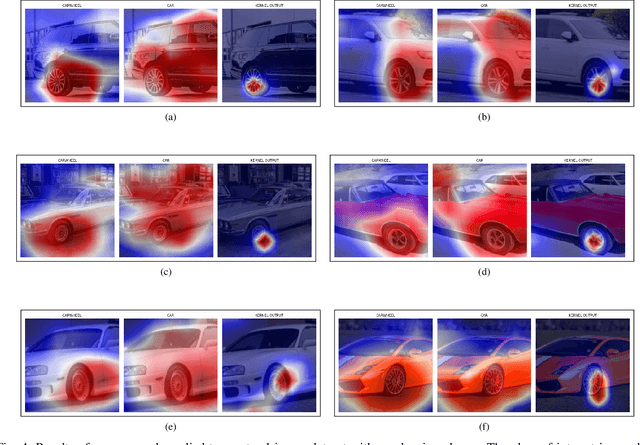
Trust in predictions made by machine learning models is increased if the model generalizes well on previously unseen samples and when inference is accompanied by cogent explanations of the reasoning behind predictions. In the image classification domain, generalization can be assessed through accuracy, sensitivity, and specificity. Explainability can be assessed by how well the model localizes the object of interest within an image. However, both generalization and explainability through localization are degraded in scenarios with significant overlap between classes. We propose a method based on binary expert networks that enhances the explainability of image classifications through better localization by mitigating the model uncertainty induced by class overlap. Our technique performs discriminative localization on images that contain features with significant class overlap, without explicitly training for localization. Our method is particularly promising in real-world class overlap scenarios, such as COVID-19 and pneumonia, where expertly labeled data for localization is not readily available. This can be useful for early, rapid, and trustworthy screening for COVID-19.
FlexServe: Deployment of PyTorch Models as Flexible REST Endpoints
Feb 29, 2020
The integration of artificial intelligence capabilities into modern software systems is increasingly being simplified through the use of cloud-based machine learning services and representational state transfer architecture design. However, insufficient information regarding underlying model provenance and the lack of control over model evolution serve as an impediment to the more widespread adoption of these services in many operational environments which have strict security requirements. Furthermore, tools such as TensorFlow Serving allow models to be deployed as RESTful endpoints, but require error-prone transformations for PyTorch models as these dynamic computational graphs. This is in contrast to the static computational graphs of TensorFlow. To enable rapid deployments of PyTorch models without intermediate transformations we have developed FlexServe, a simple library to deploy multi-model ensembles with flexible batching.
The Utility of Feature Reuse: Transfer Learning in Data-Starved Regimes
Feb 29, 2020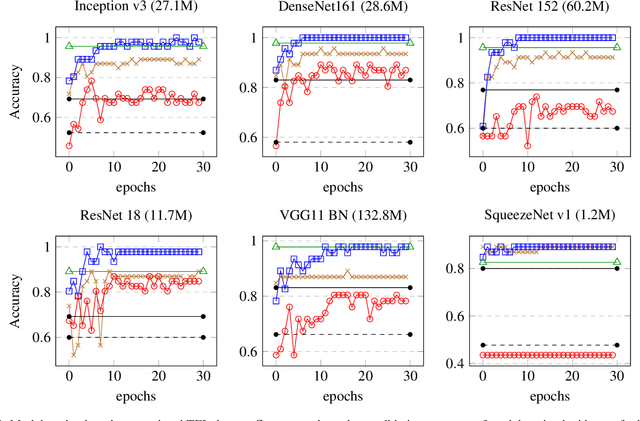
The use of transfer learning with deep neural networks has increasingly become widespread for deploying well-tested computer vision systems to newer domains, especially those with limited datasets. We describe a transfer learning use case for a domain with a data-starved regime, having fewer than 100 labeled target samples. We evaluate the effectiveness of convolutional feature extraction and fine-tuning of overparameterized models with respect to the size of target training data, as well as their generalization performance on data with covariate shift, or out-of-distribution (OOD) data. Our experiments show that both overparameterization and feature reuse contribute to successful application of transfer learning in training image classifiers in data-starved regimes.
Hazard Detection in Supermarkets using Deep Learning on the Edge
Feb 29, 2020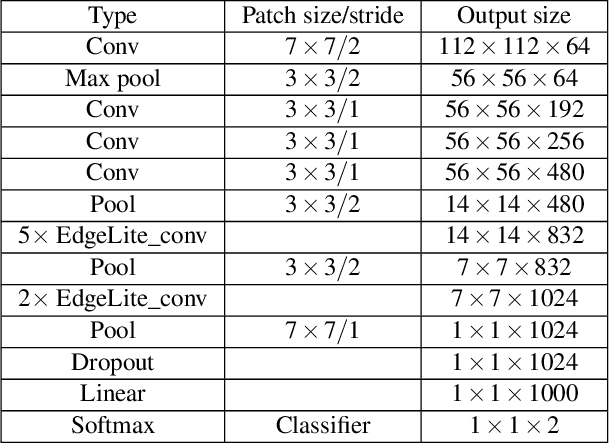

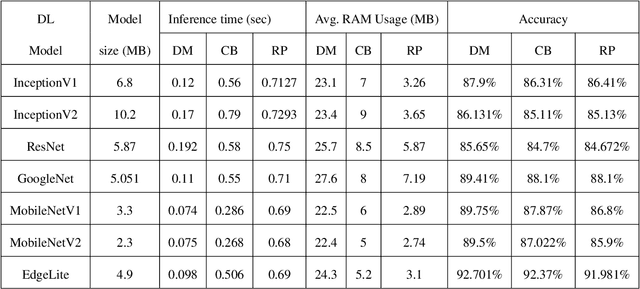
Supermarkets need to ensure clean and safe environments for both shoppers and employees. Slips, trips, and falls can result in injuries that have a physical as well as financial cost. Timely detection of hazardous conditions such as spilled liquids or fallen items on supermarket floors can reduce the chances of serious injuries. This paper presents EdgeLite, a novel, lightweight deep learning model for easy deployment and inference on resource-constrained devices. We describe the use of EdgeLite on two edge devices for detecting supermarket floor hazards. On a hazard detection dataset that we developed, EdgeLite, when deployed on edge devices, outperformed six state-of-the-art object detection models in terms of accuracy while having comparable memory usage and inference time.
Machine Learning at the Network Edge: A Survey
Jul 31, 2019
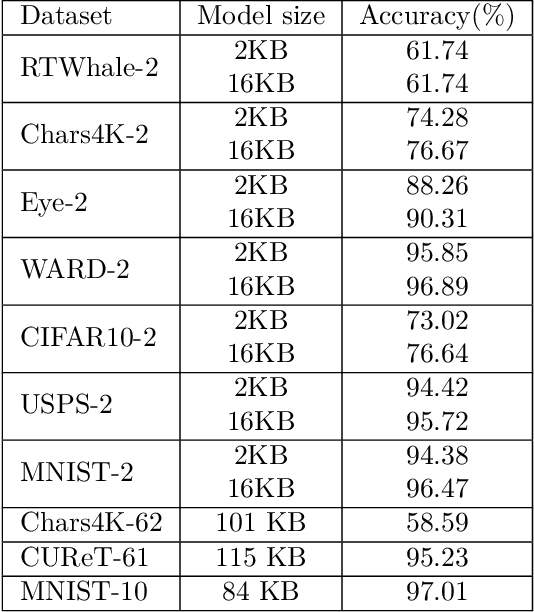
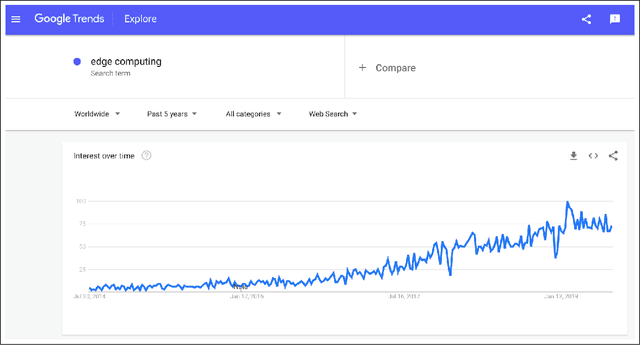
Devices comprising the Internet of Things, such as sensors and small cameras, usually have small memories and limited computational power. The proliferation of such resource-constrained devices in recent years has led to the generation of large quantities of data. These data-producing devices are appealing targets for machine learning applications but struggle to run machine learning algorithms due to their limited computing capability. They typically offload input data to external computing systems (such as cloud servers) for further processing. The results of the machine learning computations are communicated back to the resource-scarce devices, but this worsens latency, leads to increased communication costs, and adds to privacy concerns. Therefore, efforts have been made to place additional computing devices at the edge of the network, i.e close to the IoT devices where the data is generated. Deploying machine learning systems on such edge devices alleviates the above issues by allowing computations to be performed close to the data sources. This survey describes major research efforts where machine learning has been deployed at the edge of computer networks.