 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALText: Contextual Attention Localization for Offline Handwritten Text
Nov 06, 2021
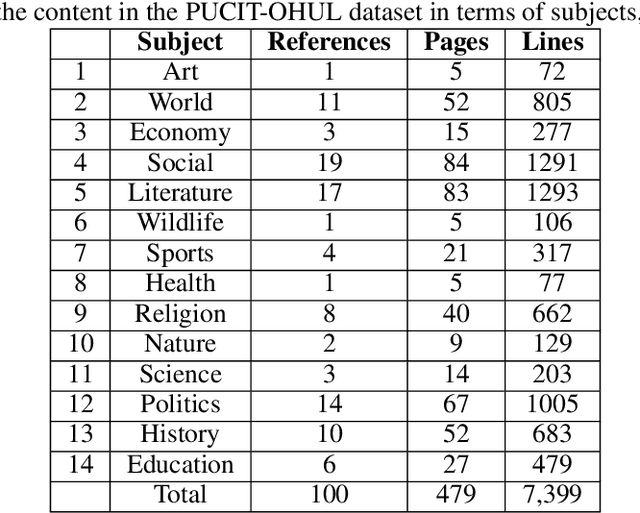

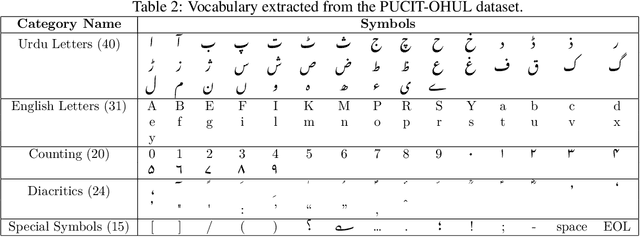
Recognition of Arabic-like scripts such as Persian and Urdu is more challenging than Latin-based scripts. This is due to the presence of a two-dimensional structure, context-dependent character shapes, spaces and overlaps, and placement of diacritics. Not much research exists for offline handwritten Urdu script which is the 10th most spoken language in the world. We present an attention based encoder-decoder model that learns to read Urdu in context. A novel localization penalty is introduced to encourage the model to attend only one location at a time when recognizing the next character. In addition, we comprehensively refine the only complete and publicly available handwritten Urdu dataset in terms of ground-truth annotations. We evaluate the model on both Urdu and Arabic datasets and show that contextual attention localization outperforms both simple attention and multi-directional LSTM models.