 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
Paper and Code
Dec 13, 2024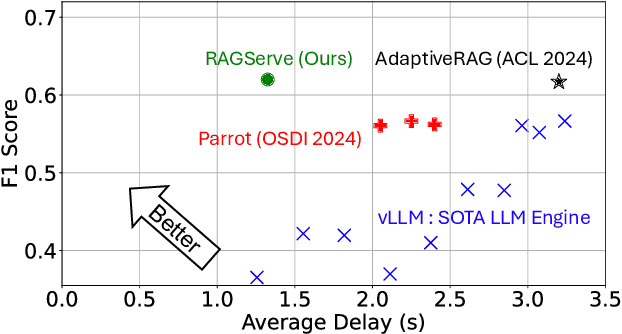

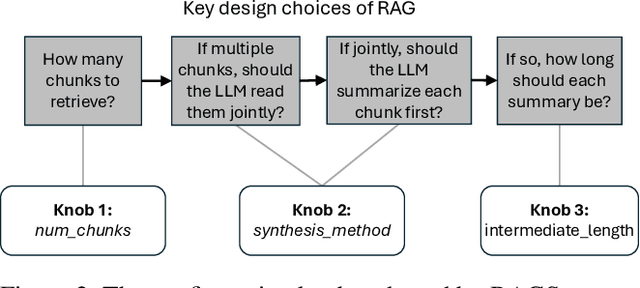
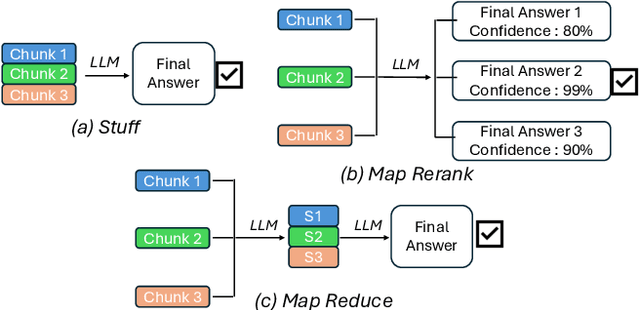
RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.