 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Multi-Agent Systems
Apr 28, 2026Recursive or looped language models have recently emerged as a new scaling axis by iteratively refining the same model computation over latent states to deepen reasoning. We extend such scaling principle from a single model to multi-agent systems, and ask: Can agent collaboration itself be scaled through recursion? To this end, we introduce RecursiveMAS, a recursive multi-agent framework that casts the entire system as a unified latent-space recursive computation. RecursiveMAS connects heterogeneous agents as a collaboration loop through the lightweight RecursiveLink module, enabling in-distribution latent thoughts generation and cross-agent latent state transfer. To optimize our framework, we develop an inner-outer loop learning algorithm for iterative whole-system co-optimization through shared gradient-based credit assignment across recursion rounds. Theoretical analyses of runtime complexity and learning dynamics establish that RecursiveMAS is more efficient than standard text-based MAS and maintains stable gradients during recursive training. Empirically, we instantiate RecursiveMAS under 4 representative agent collaboration patterns and evaluate across 9 benchmarks spanning mathematics, science, medicine, search, and code generation. In comparison with advanced single/multi-agent and recursive computation baselines, RecursiveMAS consistently delivers an average accuracy improvement of 8.3%, together with 1.2$\times$-2.4$\times$ end-to-end inference speedup, and 34.6%-75.6% token usage reduction. Code and Data are provided in https://recursivemas.github.io.
AgentSPEX: An Agent SPecification and EXecution Language
Apr 14, 2026Language-model agent systems commonly rely on reactive prompting, in which a single instruction guides the model through an open-ended sequence of reasoning and tool-use steps, leaving control flow and intermediate state implicit and making agent behavior potentially difficult to control. Orchestration frameworks such as LangGraph, DSPy, and CrewAI impose greater structure through explicit workflow definitions, but tightly couple workflow logic with Python, making agents difficult to maintain and modify. In this paper, we introduce AgentSPEX, an Agent SPecification and EXecution Language for specifying LLM-agent workflows with explicit control flow and modular structure, along with a customizable agent harness. AgentSPEX supports typed steps, branching and loops, parallel execution, reusable submodules, and explicit state management, and these workflows execute within an agent harness that provides tool access, a sandboxed virtual environment, and support for checkpointing, verification, and logging. Furthermore, we provide a visual editor with synchronized graph and workflow views for authoring and inspection. We include ready-to-use agents for deep research and scientific research, and we evaluate AgentSPEX on 7 benchmarks. Finally, we show through a user study that AgentSPEX provides a more interpretable and accessible workflow-authoring paradigm than a popular existing agent framework.
LLM-powered Real-time Patent Citation Recommendation for Financial Technologies
Jan 23, 2026Rapid financial innovation has been accompanied by a sharp increase in patenting activity, making timely and comprehensive prior-art discovery more difficult. This problem is especially evident in financial technologies, where innovations develop quickly, patent collections grow continuously, and citation recommendation systems must be updated as new applications arrive. Existing patent retrieval and citation recommendation methods typically rely on static indexes or periodic retraining, which limits their ability to operate effectively in such dynamic settings. In this study, we propose a real-time patent citation recommendation framework designed for large and fast-changing financial patent corpora. Using a dataset of 428,843 financial patents granted by the China National Intellectual Property Administration (CNIPA) between 2000 and 2024, we build a three-stage recommendation pipeline. The pipeline uses large language model (LLM) embeddings to represent the semantic content of patent abstracts, applies efficient approximate nearest-neighbor search to construct a manageable candidate set, and ranks candidates by semantic similarity to produce top-k citation recommendations. In addition to improving recommendation accuracy, the proposed framework directly addresses the dynamic nature of patent systems. By using an incremental indexing strategy based on hierarchical navigable small-world (HNSW) graphs, newly issued patents can be added without rebuilding the entire index. A rolling day-by-day update experiment shows that incremental updating improves recall while substantially reducing computational cost compared with rebuild-based indexing. The proposed method also consistently outperforms traditional text-based baselines and alternative nearest-neighbor retrieval approaches.
PhysProver: Advancing Automatic Theorem Proving for Physics
Jan 22, 2026The combination of verifiable languages and LLMs has significantly influenced both the mathematical and computer science communities because it provides a rigorous foundation for theorem proving. Recent advancements in the field provide foundation models and sophisticated agentic systems pushing the boundaries of formal mathematical reasoning to approach the natural language capability of LLMs. However, little attention has been given to the formal physics reasoning, which also heavily relies on similar problem-solving and theorem-proving frameworks. To solve this problem, this paper presents, to the best of our knowledge, the first approach to enhance formal theorem proving in the physics domain. We compose a dedicated dataset PhysLeanData for the task. It is composed of theorems sampled from PhysLean and data generated by a conjecture-based formal data generation pipeline. In the training pipeline, we leverage DeepSeek-Prover-V2-7B, a strong open-source mathematical theorem prover, and apply Reinforcement Learning with Verifiable Rewards (RLVR) to train our model PhysProver. Comprehensive experiments demonstrate that, using only $\sim$5K training samples, PhysProver achieves an overall 2.4\% improvement in multiple sub-domains. Furthermore, after formal physics training, we observe 1.3\% gains on the MiniF2F-Test benchmark, which indicates non-trivial generalization beyond physics domains and enhancement for formal math capability as well. The results highlight the effectiveness and efficiency of our approach, which provides a paradigm for extending formal provers outside mathematical domains. To foster further research, we will release both our dataset and model to the community.
Investigating Tool-Memory Conflicts in Tool-Augmented LLMs
Jan 14, 2026Tool-augmented large language models (LLMs) have powered many applications. However, they are likely to suffer from knowledge conflict. In this paper, we propose a new type of knowledge conflict -- Tool-Memory Conflict (TMC), where the internal parametric knowledge contradicts with the external tool knowledge for tool-augmented LLMs. We find that existing LLMs, though powerful, suffer from TMC, especially on STEM-related tasks. We also uncover that under different conditions, tool knowledge and parametric knowledge may be prioritized differently. We then evaluate existing conflict resolving techniques, including prompting-based and RAG-based methods. Results show that none of these approaches can effectively resolve tool-memory conflicts.
Fail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion LLMs
Dec 23, 2025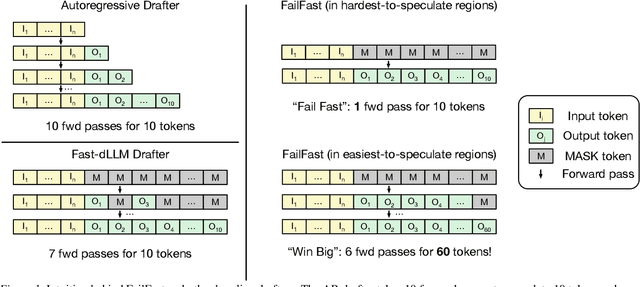
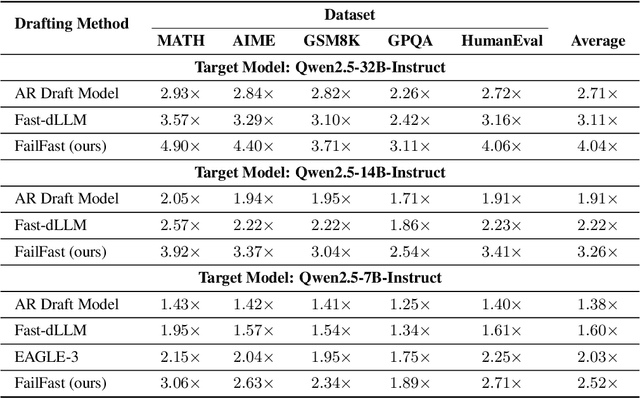
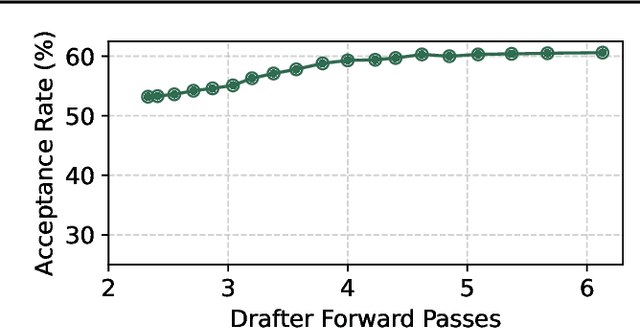

Diffusion Large Language Models (dLLMs) offer fast, parallel token generation, but their standalone use is plagued by an inherent efficiency-quality tradeoff. We show that, if carefully applied, the attributes of dLLMs can actually be a strength for drafters in speculative decoding with autoregressive (AR) verifiers. Our core insight is that dLLM's speed from parallel decoding drastically lowers the risk of costly rejections, providing a practical mechanism to effectively realize the (elusive) lengthy drafts that lead to large speedups with speculative decoding. We present FailFast, a dLLM-based speculative decoding framework that realizes this approach by dynamically adapting its speculation length. It "fails fast" by spending minimal compute in hard-to-speculate regions to shrink speculation latency and "wins big" by aggressively extending draft lengths in easier regions to reduce verification latency (in many cases, speculating and accepting 70 tokens at a time!). Without any fine-tuning, FailFast delivers lossless acceleration of AR LLMs and achieves up to 4.9$\times$ speedup over vanilla decoding, 1.7$\times$ over the best naive dLLM drafter, and 1.4$\times$ over EAGLE-3 across diverse models and workloads. We open-source FailFast at https://github.com/ruipeterpan/failfast.
NegoCollab: A Common Representation Negotiation Approach for Heterogeneous Collaborative Perception
Oct 31, 2025Collaborative perception improves task performance by expanding the perception range through information sharing among agents. . Immutable heterogeneity poses a significant challenge in collaborative perception, as participating agents may employ different and fixed perception models. This leads to domain gaps in the intermediate features shared among agents, consequently degrading collaborative performance. Aligning the features of all agents to a common representation can eliminate domain gaps with low training cost. However, in existing methods, the common representation is designated as the representation of a specific agent, making it difficult for agents with significant domain discrepancies from this specific agent to achieve proper alignment. This paper proposes NegoCollab, a heterogeneous collaboration method based on the negotiated common representation. It introduces a negotiator during training to derive the common representation from the local representations of each modality's agent, effectively reducing the inherent domain gap with the various local representations. In NegoCollab, the mutual transformation of features between the local representation space and the common representation space is achieved by a pair of sender and receiver. To better align local representations to the common representation containing multimodal information, we introduce structural alignment loss and pragmatic alignment loss in addition to the distribution alignment loss to supervise the training. This enables the knowledge in the common representation to be fully distilled into the sender.
Lean4Physics: Comprehensive Reasoning Framework for College-level Physics in Lean4
Oct 30, 2025We present **Lean4PHYS**, a comprehensive reasoning framework for college-level physics problems in Lean4. **Lean4PHYS** includes *LeanPhysBench*, a college-level benchmark for formal physics reasoning in Lean4, which contains 200 hand-crafted and peer-reviewed statements derived from university textbooks and physics competition problems. To establish a solid foundation for formal reasoning in physics, we also introduce *PhysLib*, a community-driven repository containing fundamental unit systems and theorems essential for formal physics reasoning. Based on the benchmark and Lean4 repository we composed in **Lean4PHYS**, we report baseline results using major expert Math Lean4 provers and state-of-the-art closed-source models, with the best performance of DeepSeek-Prover-V2-7B achieving only 16% and Claude-Sonnet-4 achieving 35%. We also conduct a detailed analysis showing that our *PhysLib* can achieve an average improvement of 11.75% in model performance. This demonstrates the challenging nature of our *LeanPhysBench* and the effectiveness of *PhysLib*. To the best of our knowledge, this is the first study to provide a physics benchmark in Lean4.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
Generalizable Geometric Image Caption Synthesis
Sep 18, 2025Multimodal large language models have various practical applications that demand strong reasoning abilities. Despite recent advancements, these models still struggle to solve complex geometric problems. A key challenge stems from the lack of high-quality image-text pair datasets for understanding geometric images. Furthermore, most template-based data synthesis pipelines typically fail to generalize to questions beyond their predefined templates. In this paper, we bridge this gap by introducing a complementary process of Reinforcement Learning with Verifiable Rewards (RLVR) into the data generation pipeline. By adopting RLVR to refine captions for geometric images synthesized from 50 basic geometric relations and using reward signals derived from mathematical problem-solving tasks, our pipeline successfully captures the key features of geometry problem-solving. This enables better task generalization and yields non-trivial improvements. Furthermore, even in out-of-distribution scenarios, the generated dataset enhances the general reasoning capabilities of multimodal large language models, yielding accuracy improvements of $2.8\%\text{-}4.8\%$ in statistics, arithmetic, algebraic, and numerical tasks with non-geometric input images of MathVista and MathVerse, along with $2.4\%\text{-}3.9\%$ improvements in Art, Design, Tech, and Engineering tasks in MMMU.