 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstroMLab 4: Benchmark-Topping Performance in Astronomy Q&A with a 70B-Parameter Domain-Specialized Reasoning Model
May 23, 2025General-purpose large language models, despite their broad capabilities, often struggle with specialized domain knowledge, a limitation particularly pronounced in more accessible, lower-parameter versions. This gap hinders their deployment as effective agents in demanding fields such as astronomy. Building on our prior work with AstroSage-8B, this study introduces AstroSage-70B, a significantly larger and more advanced domain-specialized natural-language AI assistant. It is designed for research and education across astronomy, astrophysics, space science, astroparticle physics, cosmology, and astronomical instrumentation. Developed from the Llama-3.1-70B foundation, AstroSage-70B underwent extensive continued pre-training on a vast corpus of astronomical literature, followed by supervised fine-tuning and model merging. Beyond its 70-billion parameter scale, this model incorporates refined datasets, judiciously chosen learning hyperparameters, and improved training procedures, achieving state-of-the-art performance on complex astronomical tasks. Notably, we integrated reasoning chains into the SFT dataset, enabling AstroSage-70B to either answer the user query immediately, or first emit a human-readable thought process. Evaluated on the AstroMLab-1 benchmark -- comprising 4,425 questions from literature withheld during training -- AstroSage-70B achieves state-of-the-art performance. It surpasses all other tested open-weight and proprietary models, including leading systems like o3, Gemini-2.5-Pro, Claude-3.7-Sonnet, Deepseek-R1, and Qwen-3-235B, even those with API costs two orders of magnitude higher. This work demonstrates that domain specialization, when applied to large-scale models, can enable them to outperform generalist counterparts in specialized knowledge areas like astronomy, thereby advancing the frontier of AI capabilities in the field.
Empirically evaluating commonsense intelligence in large language models with large-scale human judgments
May 15, 2025



Commonsense intelligence in machines is often assessed by static benchmarks that compare a model's output against human-prescribed correct labels. An important, albeit implicit, assumption of these labels is that they accurately capture what any human would think, effectively treating human common sense as homogeneous. However, recent empirical work has shown that humans vary enormously in what they consider commonsensical; thus what appears self-evident to one benchmark designer may not be so to another. Here, we propose a novel method for evaluating common sense in artificial intelligence (AI), specifically in large language models (LLMs), that incorporates empirically observed heterogeneity among humans by measuring the correspondence between a model's judgment and that of a human population. We first find that, when treated as independent survey respondents, most LLMs remain below the human median in their individual commonsense competence. Second, when used as simulators of a hypothetical population, LLMs correlate with real humans only modestly in the extent to which they agree on the same set of statements. In both cases, smaller, open-weight models are surprisingly more competitive than larger, proprietary frontier models. Our evaluation framework, which ties commonsense intelligence to its cultural basis, contributes to the growing call for adapting AI models to human collectivities that possess different, often incompatible, social stocks of knowledge.
AstroMLab 2: AstroLLaMA-2-70B Model and Benchmarking Specialised LLMs for Astronomy
Sep 29, 2024Continual pretraining of large language models on domain-specific data has been proposed to enhance performance on downstream tasks. In astronomy, the previous absence of astronomy-focused benchmarks has hindered objective evaluation of these specialized LLM models. Leveraging a recent initiative to curate high-quality astronomical MCQs, this study aims to quantitatively assess specialized LLMs in astronomy. We find that the previously released AstroLLaMA series, based on LLaMA-2-7B, underperforms compared to the base model. We demonstrate that this performance degradation can be partially mitigated by utilizing high-quality data for continual pretraining, such as summarized text from arXiv. Despite the observed catastrophic forgetting in smaller models, our results indicate that continual pretraining on the 70B model can yield significant improvements. However, the current supervised fine-tuning dataset still constrains the performance of instruct models. In conjunction with this study, we introduce a new set of models, AstroLLaMA-3-8B and AstroLLaMA-2-70B, building upon the previous AstroLLaMA series.
AstroMLab 1: Who Wins Astronomy Jeopardy!?
Jul 15, 2024We present a comprehensive evaluation of proprietary and open-weights large language models using the first astronomy-specific benchmarking dataset. This dataset comprises 4,425 multiple-choice questions curated from the Annual Review of Astronomy and Astrophysics, covering a broad range of astrophysical topics. Our analysis examines model performance across various astronomical subfields and assesses response calibration, crucial for potential deployment in research environments. Claude-3.5-Sonnet outperforms competitors by up to 4.6 percentage points, achieving 85.0% accuracy. For proprietary models, we observed a universal reduction in cost every 3-to-12 months to achieve similar score in this particular astronomy benchmark. Open-source models have rapidly improved, with LLaMA-3-70b (80.6%) and Qwen-2-72b (77.7%) now competing with some of the best proprietary models. We identify performance variations across topics, with non-English-focused models generally struggling more in exoplanet-related fields, stellar astrophysics, and instrumentation related questions. These challenges likely stem from less abundant training data, limited historical context, and rapid recent developments in these areas. This pattern is observed across both open-weights and proprietary models, with regional dependencies evident, highlighting the impact of training data diversity on model performance in specialized scientific domains. Top-performing models demonstrate well-calibrated confidence, with correlations above 0.9 between confidence and correctness, though they tend to be slightly underconfident. The development for fast, low-cost inference of open-weights models presents new opportunities for affordable deployment in astronomy. The rapid progress observed suggests that LLM-driven research in astronomy may become feasible in the near future.
Federated PCA on Grassmann Manifold for IoT Anomaly Detection
Jul 10, 2024



With the proliferation of the Internet of Things (IoT) and the rising interconnectedness of devices, network security faces significant challenges, especially from anomalous activities. While traditional machine learning-based intrusion detection systems (ML-IDS) effectively employ supervised learning methods, they possess limitations such as the requirement for labeled data and challenges with high dimensionality. Recent unsupervised ML-IDS approaches such as AutoEncoders and Generative Adversarial Networks (GAN) offer alternative solutions but pose challenges in deployment onto resource-constrained IoT devices and in interpretability. To address these concerns, this paper proposes a novel federated unsupervised anomaly detection framework, FedPCA, that leverages Principal Component Analysis (PCA) and the Alternating Directions Method Multipliers (ADMM) to learn common representations of distributed non-i.i.d. datasets. Building on the FedPCA framework, we propose two algorithms, FEDPE in Euclidean space and FEDPG on Grassmann manifolds. Our approach enables real-time threat detection and mitigation at the device level, enhancing network resilience while ensuring privacy. Moreover, the proposed algorithms are accompanied by theoretical convergence rates even under a subsampling scheme, a novel result. Experimental results on the UNSW-NB15 and TON-IoT datasets show that our proposed methods offer performance in anomaly detection comparable to nonlinear baselines, while providing significant improvements in communication and memory efficiency, underscoring their potential for securing IoT networks.
* Accepted for publication at IEEE/ACM Transactions on Networking
AstroLLaMA-Chat: Scaling AstroLLaMA with Conversational and Diverse Datasets
Jan 05, 2024We explore the potential of enhancing LLM performance in astronomy-focused question-answering through targeted, continual pre-training. By employing a compact 7B-parameter LLaMA-2 model and focusing exclusively on a curated set of astronomy corpora -- comprising abstracts, introductions, and conclusions -- we achieve notable improvements in specialized topic comprehension. While general LLMs like GPT-4 excel in broader question-answering scenarios due to superior reasoning capabilities, our findings suggest that continual pre-training with limited resources can still enhance model performance on specialized topics. Additionally, we present an extension of AstroLLaMA: the fine-tuning of the 7B LLaMA model on a domain-specific conversational dataset, culminating in the release of the chat-enabled AstroLLaMA for community use. Comprehensive quantitative benchmarking is currently in progress and will be detailed in an upcoming full paper. The model, AstroLLaMA-Chat, is now available at https://huggingface.co/universeTBD, providing the first open-source conversational AI tool tailored for the astronomy community.
On Partial Optimal Transport: Revising the Infeasibility of Sinkhorn and Efficient Gradient Methods
Dec 22, 2023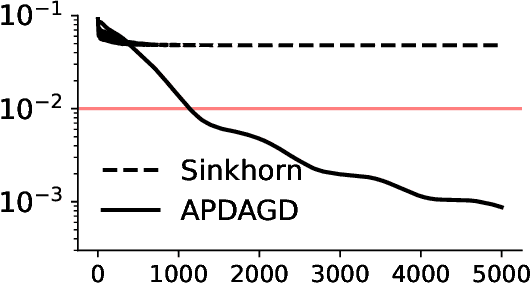

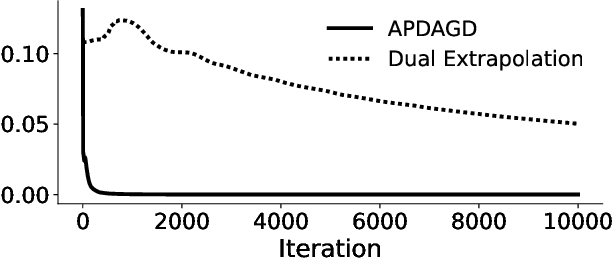
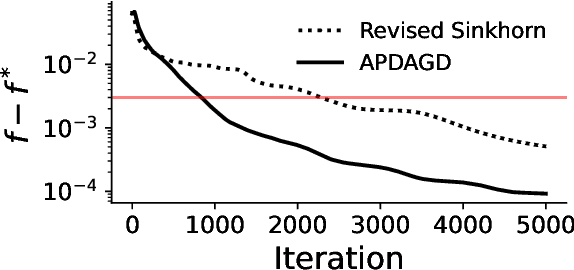
This paper studies the Partial Optimal Transport (POT) problem between two unbalanced measures with at most $n$ supports and its applications in various AI tasks such as color transfer or domain adaptation. There is hence the need for fast approximations of POT with increasingly large problem sizes in arising applications. We first theoretically and experimentally investigate the infeasibility of the state-of-the-art Sinkhorn algorithm for POT due to its incompatible rounding procedure, which consequently degrades its qualitative performance in real world applications like point-cloud registration. To this end, we propose a novel rounding algorithm for POT, and then provide a feasible Sinkhorn procedure with a revised computation complexity of $\mathcal{\widetilde O}(n^2/\varepsilon^4)$. Our rounding algorithm also permits the development of two first-order methods to approximate the POT problem. The first algorithm, Adaptive Primal-Dual Accelerated Gradient Descent (APDAGD), finds an $\varepsilon$-approximate solution to the POT problem in $\mathcal{\widetilde O}(n^{2.5}/\varepsilon)$, which is better in $\varepsilon$ than revised Sinkhorn. The second method, Dual Extrapolation, achieves the computation complexity of $\mathcal{\widetilde O}(n^2/\varepsilon)$, thereby being the best in the literature. We further demonstrate the flexibility of POT compared to standard OT as well as the practicality of our algorithms on real applications where two marginal distributions are unbalanced.
Federated Deep Equilibrium Learning: A Compact Shared Representation for Edge Communication Efficiency
Sep 27, 2023Federated Learning (FL) is a prominent distributed learning paradigm facilitating collaboration among nodes within an edge network to co-train a global model without centralizing data. By shifting computation to the network edge, FL offers robust and responsive edge-AI solutions and enhance privacy-preservation. However, deploying deep FL models within edge environments is often hindered by communication bottlenecks, data heterogeneity, and memory limitations. To address these challenges jointly, we introduce FeDEQ, a pioneering FL framework that effectively employs deep equilibrium learning and consensus optimization to exploit a compact shared data representation across edge nodes, allowing the derivation of personalized models specific to each node. We delve into a unique model structure composed of an equilibrium layer followed by traditional neural network layers. Here, the equilibrium layer functions as a global feature representation that edge nodes can adapt to personalize their local layers. Capitalizing on FeDEQ's compactness and representation power, we present a novel distributed algorithm rooted in the alternating direction method of multipliers (ADMM) consensus optimization and theoretically establish its convergence for smooth objectives. Experiments across various benchmarks demonstrate that FeDEQ achieves performance comparable to state-of-the-art personalized methods while employing models of up to 4 times smaller in communication size and 1.5 times lower memory footprint during training.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023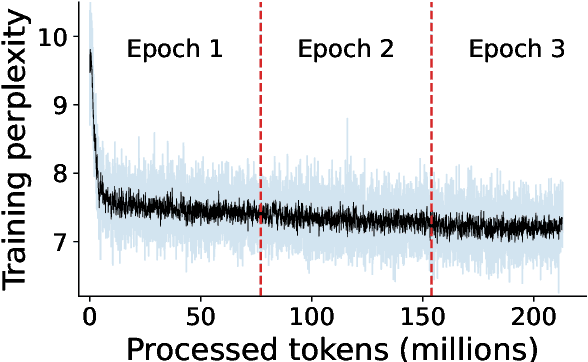

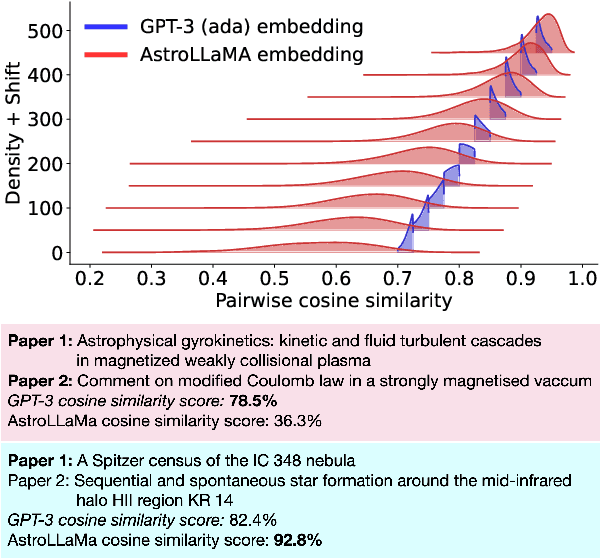
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.
On the Generalization of Wasserstein Robust Federated Learning
Jun 03, 2022

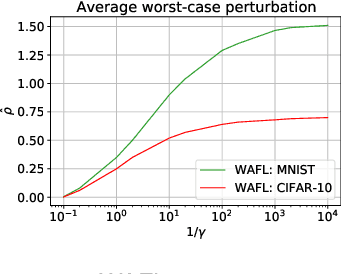

In federated learning, participating clients typically possess non-i.i.d. data, posing a significant challenge to generalization to unseen distributions. To address this, we propose a Wasserstein distributionally robust optimization scheme called WAFL. Leveraging its duality, we frame WAFL as an empirical surrogate risk minimization problem, and solve it using a local SGD-based algorithm with convergence guarantees. We show that the robustness of WAFL is more general than related approaches, and the generalization bound is robust to all adversarial distributions inside the Wasserstein ball (ambiguity set). Since the center location and radius of the Wasserstein ball can be suitably modified, WAFL shows its applicability not only in robustness but also in domain adaptation. Through empirical evaluation, we demonstrate that WAFL generalizes better than the vanilla FedAvg in non-i.i.d. settings, and is more robust than other related methods in distribution shift settings. Further, using benchmark datasets we show that WAFL is capable of generalizing to unseen target domains.