 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedVideoMAE: Efficient Privacy-Preserving Federated Video Moderation
Dec 21, 2025



The rapid growth of short-form video platforms increases the need for privacy-preserving moderation, as cloud-based pipelines expose raw videos to privacy risks, high bandwidth costs, and inference latency. To address these challenges, we propose an on-device federated learning framework for video violence detection that integrates self-supervised VideoMAE representations, LoRA-based parameter-efficient adaptation, and defense-in-depth privacy protection. Our approach reduces the trainable parameter count to 5.5M (~3.5% of a 156M backbone) and incorporates DP-SGD with configurable privacy budgets and secure aggregation. Experiments on RWF-2000 with 40 clients achieve 77.25% accuracy without privacy protection and 65-66% under strong differential privacy, while reducing communication cost by $28.3\times$ compared to full-model federated learning. The code is available at: {https://github.com/zyt-599/FedVideoMAE}
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025



The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
Federated PCA on Grassmann Manifold for IoT Anomaly Detection
Jul 10, 2024



With the proliferation of the Internet of Things (IoT) and the rising interconnectedness of devices, network security faces significant challenges, especially from anomalous activities. While traditional machine learning-based intrusion detection systems (ML-IDS) effectively employ supervised learning methods, they possess limitations such as the requirement for labeled data and challenges with high dimensionality. Recent unsupervised ML-IDS approaches such as AutoEncoders and Generative Adversarial Networks (GAN) offer alternative solutions but pose challenges in deployment onto resource-constrained IoT devices and in interpretability. To address these concerns, this paper proposes a novel federated unsupervised anomaly detection framework, FedPCA, that leverages Principal Component Analysis (PCA) and the Alternating Directions Method Multipliers (ADMM) to learn common representations of distributed non-i.i.d. datasets. Building on the FedPCA framework, we propose two algorithms, FEDPE in Euclidean space and FEDPG on Grassmann manifolds. Our approach enables real-time threat detection and mitigation at the device level, enhancing network resilience while ensuring privacy. Moreover, the proposed algorithms are accompanied by theoretical convergence rates even under a subsampling scheme, a novel result. Experimental results on the UNSW-NB15 and TON-IoT datasets show that our proposed methods offer performance in anomaly detection comparable to nonlinear baselines, while providing significant improvements in communication and memory efficiency, underscoring their potential for securing IoT networks.
* Accepted for publication at IEEE/ACM Transactions on Networking
Search Intenion Network for Personalized Query Auto-Completion in E-Commerce
Mar 05, 2024



Query Auto-Completion(QAC), as an important part of the modern search engine, plays a key role in complementing user queries and helping them refine their search intentions.Today's QAC systems in real-world scenarios face two major challenges:1)intention equivocality(IE): during the user's typing process,the prefix often contains a combination of characters and subwords, which makes the current intention ambiguous and difficult to model.2)intention transfer (IT):previous works make personalized recommendations based on users' historical sequences, but ignore the search intention transfer.However, the current intention extracted from prefix may be contrary to the historical preferences.
Bridging the Gap: Fine-to-Coarse Sketch Interpolation Network for High-Quality Animation Sketch Inbetweening
Aug 25, 2023The 2D animation workflow is typically initiated with the creation of keyframes using sketch-based drawing. Subsequent inbetweens (i.e., intermediate sketch frames) are crafted through manual interpolation for smooth animations, which is a labor-intensive process. Thus, the prospect of automatic animation sketch interpolation has become highly appealing. However, existing video interpolation methods are generally hindered by two key issues for sketch inbetweening: 1) limited texture and colour details in sketches, and 2) exaggerated alterations between two sketch keyframes. To overcome these issues, we propose a novel deep learning method, namely Fine-to-Coarse Sketch Interpolation Network (FC-SIN). This approach incorporates multi-level guidance that formulates region-level correspondence, sketch-level correspondence and pixel-level dynamics. A multi-stream U-Transformer is then devised to characterize sketch inbewteening patterns using these multi-level guides through the integration of both self-attention and cross-attention mechanisms. Additionally, to facilitate future research on animation sketch inbetweening, we constructed a large-scale dataset - STD-12K, comprising 30 sketch animation series in diverse artistic styles. Comprehensive experiments on this dataset convincingly show that our proposed FC-SIN surpasses the state-of-the-art interpolation methods. Our code and dataset will be publicly available.
Handling Heavy Occlusion in Dense Crowd Tracking by Focusing on the Heads
Apr 27, 2023



With the rapid development of deep learning, object detection and tracking play a vital role in today's society. Being able to identify and track all the pedestrians in the dense crowd scene with computer vision approaches is a typical challenge in this field, also known as the Multiple Object Tracking (MOT) challenge. Modern trackers are required to operate on more and more complicated scenes. According to the MOT20 challenge result, the pedestrian is 4 times denser than the MOT17 challenge. Hence, improving the ability to detect and track in extremely crowded scenes is the aim of this work. In light of the occlusion issue with the human body, the heads are usually easier to identify. In this work, we have designed a joint head and body detector in an anchor-free style to boost the detection recall and precision performance of pedestrians in both small and medium sizes. Innovatively, our model does not require information on the statistical head-body ratio for common pedestrians detection for training. Instead, the proposed model learns the ratio dynamically. To verify the effectiveness of the proposed model, we evaluate the model with extensive experiments on different datasets, including MOT20, Crowdhuman, and HT21 datasets. As a result, our proposed method significantly improves both the recall and precision rate on small & medium sized pedestrians and achieves state-of-the-art results in these challenging datasets.
FedMAE: Federated Self-Supervised Learning with One-Block Masked Auto-Encoder
Mar 20, 2023



Latest federated learning (FL) methods started to focus on how to use unlabeled data in clients for training due to users' privacy concerns, high labeling costs, or lack of expertise. However, current Federated Semi-Supervised/Self-Supervised Learning (FSSL) approaches fail to learn large-scale images because of the limited computing resources of local clients. In this paper, we introduce a new framework FedMAE, which stands for Federated Masked AutoEncoder, to address the problem of how to utilize unlabeled large-scale images for FL. Specifically, FedMAE can pre-train one-block Masked AutoEncoder (MAE) using large images in lightweight client devices, and then cascades multiple pre-trained one-block MAEs in the server to build a multi-block ViT backbone for downstream tasks. Theoretical analysis and experimental results on image reconstruction and classification show that our FedMAE achieves superior performance compared to the state-of-the-art FSSL methods.
FedIL: Federated Incremental Learning from Decentralized Unlabeled Data with Convergence Analysis
Feb 23, 2023



Most existing federated learning methods assume that clients have fully labeled data to train on, while in reality, it is hard for the clients to get task-specific labels due to users' privacy concerns, high labeling costs, or lack of expertise. This work considers the server with a small labeled dataset and intends to use unlabeled data in multiple clients for semi-supervised learning. We propose a new framework with a generalized model, Federated Incremental Learning (FedIL), to address the problem of how to utilize labeled data in the server and unlabeled data in clients separately in the scenario of Federated Learning (FL). FedIL uses the Iterative Similarity Fusion to enforce the server-client consistency on the predictions of unlabeled data and uses incremental confidence to establish a credible pseudo-label set in each client. We show that FedIL will accelerate model convergence by Cosine Similarity with normalization, proved by Banach Fixed Point Theorem. The code is available at https://anonymous.4open.science/r/fedil.
Random Padding Data Augmentation
Feb 17, 2023The convolutional neural network (CNN) learns the same object in different positions in images, which can improve the recognition accuracy of the model. An implication of this is that CNN may know where the object is. The usefulness of the features' spatial information in CNNs has not been well investigated. In this paper, we found that the model's learning of features' position information hindered the learning of the features' relationship. Therefore, we introduced Random Padding, a new type of padding method for training CNNs that impairs the architecture's capacity to learn position information by adding zero-padding randomly to half of the border of feature maps. Random Padding is parameter-free, simple to construct, and compatible with the majority of CNN-based recognition models. This technique is also complementary to data augmentations such as random cropping, rotation, flipping and erasing, and consistently improves the performance of image classification over strong baselines.
Federated PCA on Grassmann Manifold for Anomaly Detection in IoT Networks
Jan 10, 2023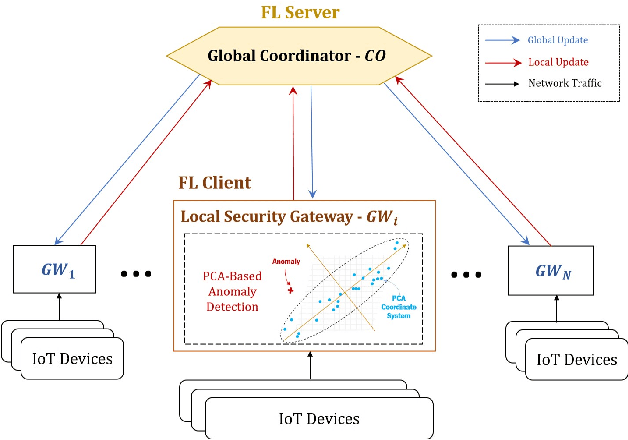


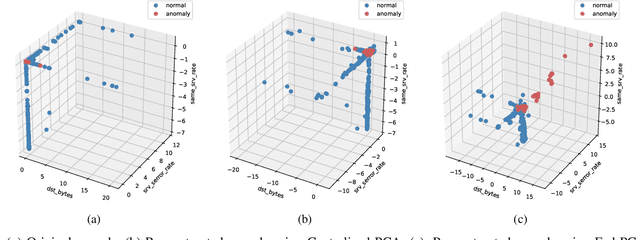
In the era of Internet of Things (IoT), network-wide anomaly detection is a crucial part of monitoring IoT networks due to the inherent security vulnerabilities of most IoT devices. Principal Components Analysis (PCA) has been proposed to separate network traffics into two disjoint subspaces corresponding to normal and malicious behaviors for anomaly detection. However, the privacy concerns and limitations of devices' computing resources compromise the practical effectiveness of PCA. We propose a federated PCA-based Grassmannian optimization framework that coordinates IoT devices to aggregate a joint profile of normal network behaviors for anomaly detection. First, we introduce a privacy-preserving federated PCA framework to simultaneously capture the profile of various IoT devices' traffic. Then, we investigate the alternating direction method of multipliers gradient-based learning on the Grassmann manifold to guarantee fast training and the absence of detecting latency using limited computational resources. Empirical results on the NSL-KDD dataset demonstrate that our method outperforms baseline approaches. Finally, we show that the Grassmann manifold algorithm is highly adapted for IoT anomaly detection, which permits drastically reducing the analysis time of the system. To the best of our knowledge, this is the first federated PCA algorithm for anomaly detection meeting the requirements of IoT networks.