 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Law Analysis in Federated Learning: How to Select the Optimal Model Size?
Nov 15, 2025The recent success of large language models (LLMs) has sparked a growing interest in training large-scale models. As the model size continues to scale, concerns are growing about the depletion of high-quality, well-curated training data. This has led practitioners to explore training approaches like Federated Learning (FL), which can leverage the abundant data on edge devices while maintaining privacy. However, the decentralization of training datasets in FL introduces challenges to scaling large models, a topic that remains under-explored. This paper fills this gap and provides qualitative insights on generalizing the previous model scaling experience to federated learning scenarios. Specifically, we derive a PAC-Bayes (Probably Approximately Correct Bayesian) upper bound for the generalization error of models trained with stochastic algorithms in federated settings and quantify the impact of distributed training data on the optimal model size by finding the analytic solution of model size that minimizes this bound. Our theoretical results demonstrate that the optimal model size has a negative power law relationship with the number of clients if the total training compute is unchanged. Besides, we also find that switching to FL with the same training compute will inevitably reduce the upper bound of generalization performance that the model can achieve through training, and that estimating the optimal model size in federated scenarios should depend on the average training compute across clients. Furthermore, we also empirically validate the correctness of our results with extensive training runs on different models, network settings, and datasets.
Best-Subset Selection in Generalized Linear Models: A Fast and Consistent Algorithm via Splicing Technique
Aug 01, 2023In high-dimensional generalized linear models, it is crucial to identify a sparse model that adequately accounts for response variation. Although the best subset section has been widely regarded as the Holy Grail of problems of this type, achieving either computational efficiency or statistical guarantees is challenging. In this article, we intend to surmount this obstacle by utilizing a fast algorithm to select the best subset with high certainty. We proposed and illustrated an algorithm for best subset recovery in regularity conditions. Under mild conditions, the computational complexity of our algorithm scales polynomially with sample size and dimension. In addition to demonstrating the statistical properties of our method, extensive numerical experiments reveal that it outperforms existing methods for variable selection and coefficient estimation. The runtime analysis shows that our implementation achieves approximately a fourfold speedup compared to popular variable selection toolkits like glmnet and ncvreg.
FedMAE: Federated Self-Supervised Learning with One-Block Masked Auto-Encoder
Mar 20, 2023



Latest federated learning (FL) methods started to focus on how to use unlabeled data in clients for training due to users' privacy concerns, high labeling costs, or lack of expertise. However, current Federated Semi-Supervised/Self-Supervised Learning (FSSL) approaches fail to learn large-scale images because of the limited computing resources of local clients. In this paper, we introduce a new framework FedMAE, which stands for Federated Masked AutoEncoder, to address the problem of how to utilize unlabeled large-scale images for FL. Specifically, FedMAE can pre-train one-block Masked AutoEncoder (MAE) using large images in lightweight client devices, and then cascades multiple pre-trained one-block MAEs in the server to build a multi-block ViT backbone for downstream tasks. Theoretical analysis and experimental results on image reconstruction and classification show that our FedMAE achieves superior performance compared to the state-of-the-art FSSL methods.
Deep Learning Methods for Small Molecule Drug Discovery: A Survey
Mar 05, 2023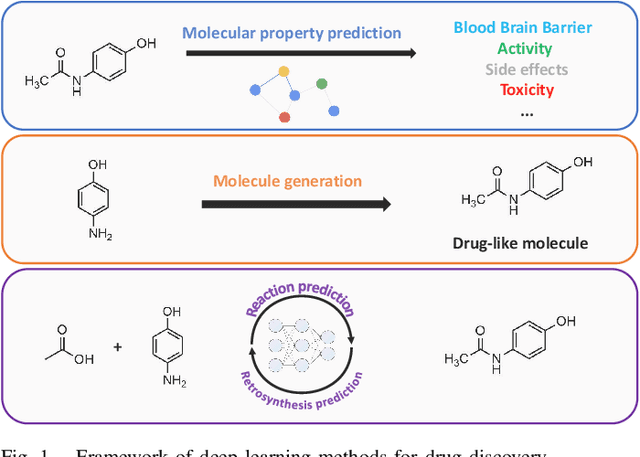
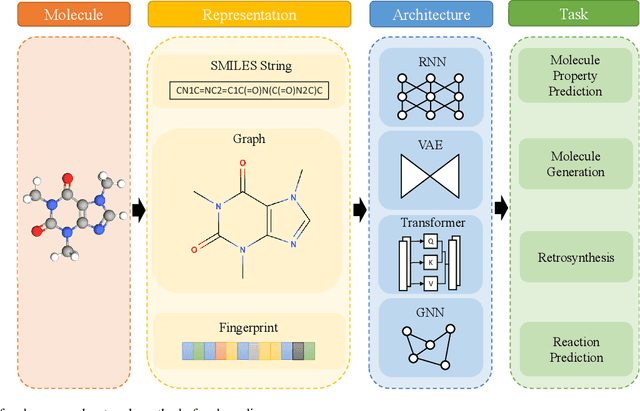
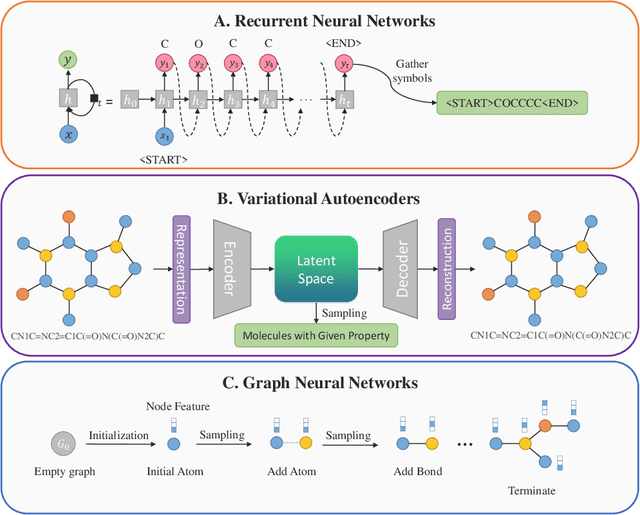
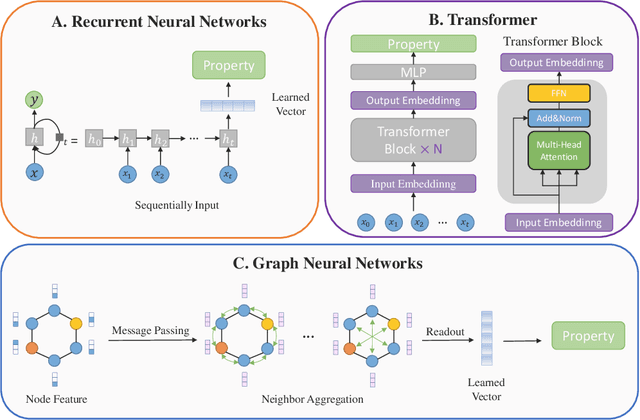
With the development of computer-assisted techniques, research communities including biochemistry and deep learning have been devoted into the drug discovery field for over a decade. Various applications of deep learning have drawn great attention in drug discovery, such as molecule generation, molecular property prediction, retrosynthesis prediction, and reaction prediction. While most existing surveys only focus on one of the applications, limiting the view of researchers in the community. In this paper, we present a comprehensive review on the aforementioned four aspects, and discuss the relationships among different applications. The latest literature and classical benchmarks are presented for better understanding the development of variety of approaches. We commence by summarizing the molecule representation format in these works, followed by an introduction of recent proposed approaches for each of the four tasks. Furthermore, we review a variety of commonly used datasets and evaluation metrics and compare the performance of deep learning-based models. Finally, we conclude by identifying remaining challenges and discussing the future trend for deep learning methods in drug discovery.
Deep Learning for Stock Selection Based on High Frequency Price-Volume Data
Nov 06, 2019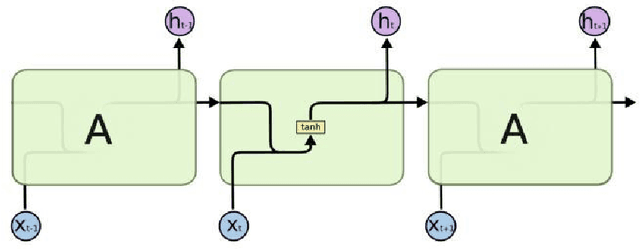

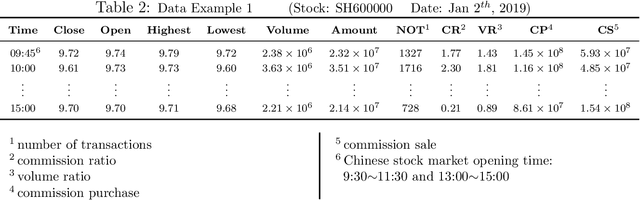

Training a practical and effective model for stock selection has been a greatly concerned problem in the field of artificial intelligence. Even though some of the models from previous works have achieved good performance in the U.S. market by using low-frequency data and features, training a suitable model with high-frequency stock data is still a problem worth exploring. Based on the high-frequency price data of the past several days, we construct two separate models-Convolution Neural Network and Long Short-Term Memory-which can predict the expected return rate of stocks on the current day, and select the stocks with the highest expected yield at the opening to maximize the total return. In our CNN model, we propose improvements on the CNNpred model presented by E. Hoseinzade and S. Haratizadeh in their paper which deals with low-frequency features. Such improvements enable our CNN model to exploit the convolution layer's ability to extract high-level factors and avoid excessive loss of original information at the same time. Our LSTM model utilizes Recurrent Neural Network'advantages in handling time series data. Despite considerable transaction fees due to the daily changes of our stock position, annualized net rate of return is 62.27% for our CNN model, and 50.31% for our LSTM model.