 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephysfusion: A Transformer-based Dual-Stream Radar and Vision Fusion Framework for Open Water Surface Object Detection
Mar 02, 2026Detecting water-surface targets for Unmanned Surface Vehicles (USVs) is challenging due to wave clutter, specular reflections, and weak appearance cues in long-range observations. Although 4D millimeter-wave radar complements cameras under degraded illumination, maritime radar point clouds are sparse and intermittent, with reflectivity attributes exhibiting heavy-tailed variations under scattering and multipath, making conventional fusion designs struggle to exploit radar cues effectively. We propose PhysFusion, a physics-informed radar-image detection framework for water-surface perception. The framework integrates: (1) a Physics-Informed Radar Encoder (PIR Encoder) with an RCS Mapper and Quality Gate, transforming per-point radar attributes into compact scattering priors and predicting point-wise reliability for robust feature learning under clutter; (2) a Radar-guided Interactive Fusion Module (RIFM) performing query-level radar-image fusion between semantically enriched radar features and multi-scale visual features, with the radar branch modeled by a dual-stream backbone including a point-based local stream and a transformer-based global stream using Scattering-Aware Self-Attention (SASA); and (3) a Temporal Query Aggregation module (TQA) aggregating frame-wise fused queries over a short temporal window for temporally consistent representations. Experiments on WaterScenes and FLOW demonstrate that PhysFusion achieves 59.7% mAP50:95 and 90.3% mAP50 on WaterScenes (T=5 radar history) using 5.6M parameters and 12.5G FLOPs, and reaches 94.8% mAP50 and 46.2% mAP50:95 on FLOW under radar+camera setting. Ablation studies quantify the contributions of PIR Encoder, SASA-based global reasoning, and RIFM.
Feature Fusion Transferability Aware Transformer for Unsupervised Domain Adaptation
Nov 10, 2024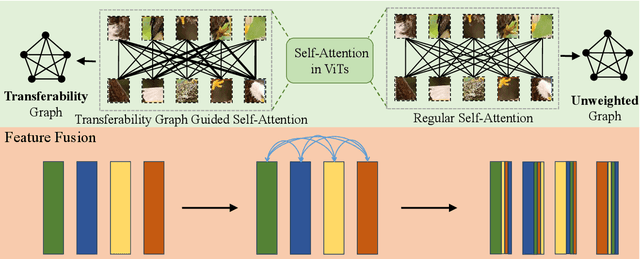
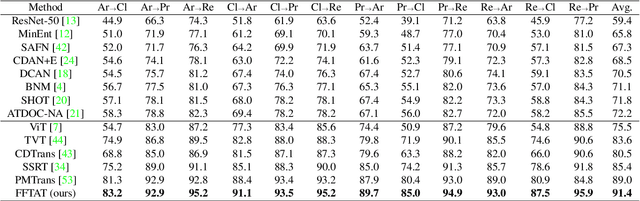
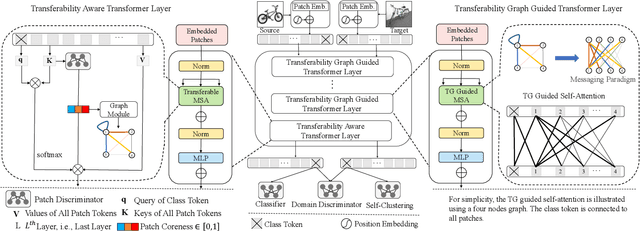
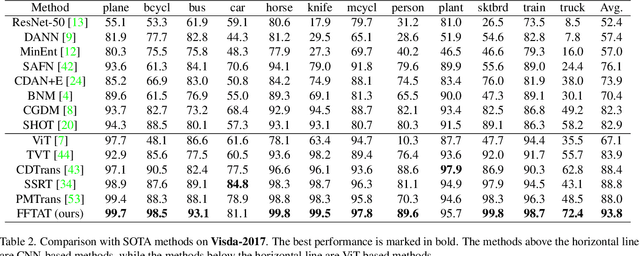
Unsupervised domain adaptation (UDA) aims to leverage the knowledge learned from labeled source domains to improve performance on the unlabeled target domains. While Convolutional Neural Networks (CNNs) have been dominant in previous UDA methods, recent research has shown promise in applying Vision Transformers (ViTs) to this task. In this study, we propose a novel Feature Fusion Transferability Aware Transformer (FFTAT) to enhance ViT performance in UDA tasks. Our method introduces two key innovations: First, we introduce a patch discriminator to evaluate the transferability of patches, generating a transferability matrix. We integrate this matrix into self-attention, directing the model to focus on transferable patches. Second, we propose a feature fusion technique to fuse embeddings in the latent space, enabling each embedding to incorporate information from all others, thereby improving generalization. These two components work in synergy to enhance feature representation learning. Extensive experiments on widely used benchmarks demonstrate that our method significantly improves UDA performance, achieving state-of-the-art (SOTA) results.
CAKD: A Correlation-Aware Knowledge Distillation Framework Based on Decoupling Kullback-Leibler Divergence
Oct 17, 2024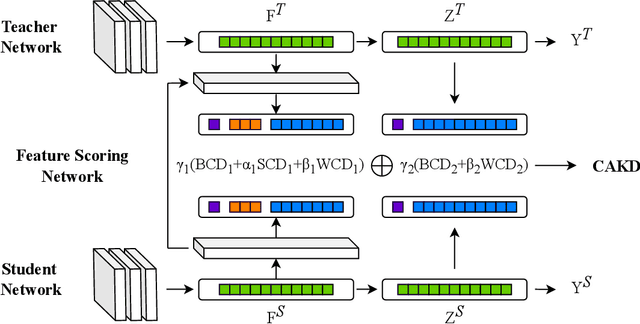
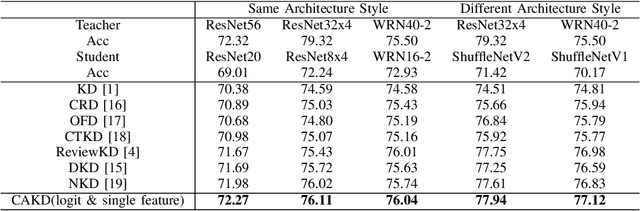
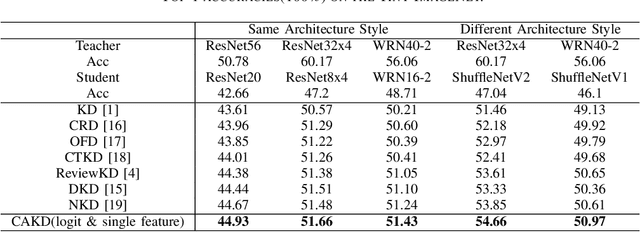
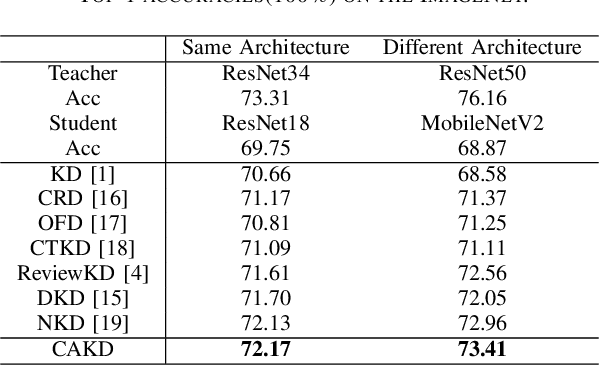
In knowledge distillation, a primary focus has been on transforming and balancing multiple distillation components. In this work, we emphasize the importance of thoroughly examining each distillation component, as we observe that not all elements are equally crucial. From this perspective,we decouple the Kullback-Leibler (KL) divergence into three unique elements: Binary Classification Divergence (BCD), Strong Correlation Divergence (SCD), and Weak Correlation Divergence (WCD). Each of these elements presents varying degrees of influence. Leveraging these insights, we present the Correlation-Aware Knowledge Distillation (CAKD) framework. CAKD is designed to prioritize the facets of the distillation components that have the most substantial influence on predictions, thereby optimizing knowledge transfer from teacher to student models. Our experiments demonstrate that adjusting the effect of each element enhances the effectiveness of knowledge transformation. Furthermore, evidence shows that our novel CAKD framework consistently outperforms the baseline across diverse models and datasets. Our work further highlights the importance and effectiveness of closely examining the impact of different parts of distillation process.
Handling Heavy Occlusion in Dense Crowd Tracking by Focusing on the Heads
Apr 27, 2023



With the rapid development of deep learning, object detection and tracking play a vital role in today's society. Being able to identify and track all the pedestrians in the dense crowd scene with computer vision approaches is a typical challenge in this field, also known as the Multiple Object Tracking (MOT) challenge. Modern trackers are required to operate on more and more complicated scenes. According to the MOT20 challenge result, the pedestrian is 4 times denser than the MOT17 challenge. Hence, improving the ability to detect and track in extremely crowded scenes is the aim of this work. In light of the occlusion issue with the human body, the heads are usually easier to identify. In this work, we have designed a joint head and body detector in an anchor-free style to boost the detection recall and precision performance of pedestrians in both small and medium sizes. Innovatively, our model does not require information on the statistical head-body ratio for common pedestrians detection for training. Instead, the proposed model learns the ratio dynamically. To verify the effectiveness of the proposed model, we evaluate the model with extensive experiments on different datasets, including MOT20, Crowdhuman, and HT21 datasets. As a result, our proposed method significantly improves both the recall and precision rate on small & medium sized pedestrians and achieves state-of-the-art results in these challenging datasets.