 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Fusion Transferability Aware Transformer for Unsupervised Domain Adaptation
Paper and Code
Nov 10, 2024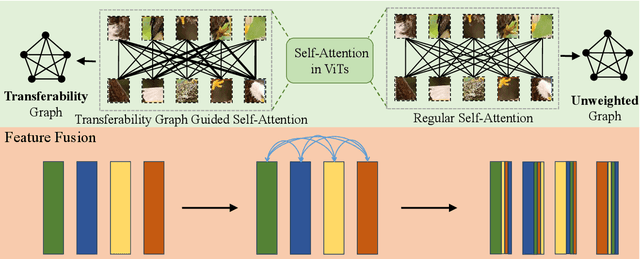
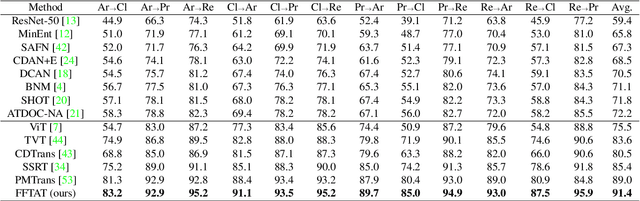
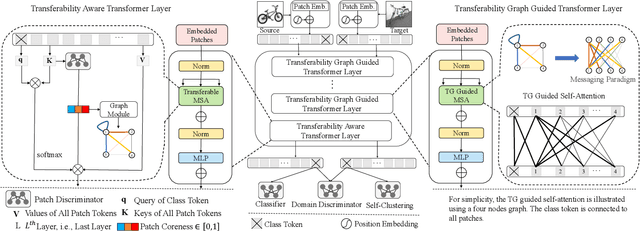
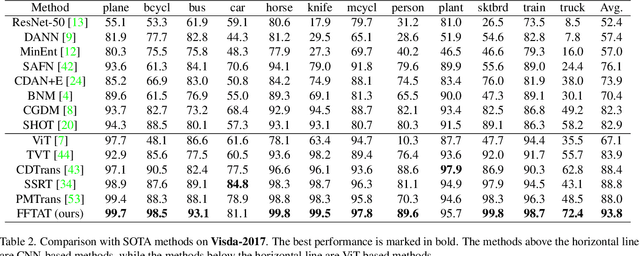
Unsupervised domain adaptation (UDA) aims to leverage the knowledge learned from labeled source domains to improve performance on the unlabeled target domains. While Convolutional Neural Networks (CNNs) have been dominant in previous UDA methods, recent research has shown promise in applying Vision Transformers (ViTs) to this task. In this study, we propose a novel Feature Fusion Transferability Aware Transformer (FFTAT) to enhance ViT performance in UDA tasks. Our method introduces two key innovations: First, we introduce a patch discriminator to evaluate the transferability of patches, generating a transferability matrix. We integrate this matrix into self-attention, directing the model to focus on transferable patches. Second, we propose a feature fusion technique to fuse embeddings in the latent space, enabling each embedding to incorporate information from all others, thereby improving generalization. These two components work in synergy to enhance feature representation learning. Extensive experiments on widely used benchmarks demonstrate that our method significantly improves UDA performance, achieving state-of-the-art (SOTA) results.