 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-Low Bitrate Perceptual Image Compression with Shallow Encoder
Dec 13, 2025Ultra-low bitrate image compression (below 0.05 bits per pixel) is increasingly critical for bandwidth-constrained and computation-limited encoding scenarios such as edge devices. Existing frameworks typically rely on large pretrained encoders (e.g., VAEs or tokenizer-based models) and perform transform coding within their generative latent space. While these approaches achieve impressive perceptual fidelity, their reliance on heavy encoder networks makes them unsuitable for deployment on weak sender devices. In this work, we explore the feasibility of applying shallow encoders for ultra-low bitrate compression and propose a novel Asymmetric Extreme Image Compression (AEIC) framework that pursues simultaneously encoding simplicity and decoding quality. Specifically, AEIC employs moderate or even shallow encoder networks, while leveraging an one-step diffusion decoder to maintain high-fidelity and high-realism reconstructions under extreme bitrates. To further enhance the efficiency of shallow encoders, we design a dual-side feature distillation scheme that transfers knowledge from AEIC with moderate encoders to its shallow encoder variants. Experiments demonstrate that AEIC not only outperforms existing methods on rate-distortion-perception performance at ultra-low bitrates, but also delivers exceptional encoding efficiency for 35.8 FPS on 1080P input images, while maintaining competitive decoding speed compared to existing methods.
CoMA: Complementary Masking and Hierarchical Dynamic Multi-Window Self-Attention in a Unified Pre-training Framework
Nov 08, 2025Masked Autoencoders (MAE) achieve self-supervised learning of image representations by randomly removing a portion of visual tokens and reconstructing the original image as a pretext task, thereby significantly enhancing pretraining efficiency and yielding excellent adaptability across downstream tasks. However, MAE and other MAE-style paradigms that adopt random masking generally require more pre-training epochs to maintain adaptability. Meanwhile, ViT in MAE suffers from inefficient parameter use due to fixed spatial resolution across layers. To overcome these limitations, we propose the Complementary Masked Autoencoders (CoMA), which employ a complementary masking strategy to ensure uniform sampling across all pixels, thereby improving effective learning of all features and enhancing the model's adaptability. Furthermore, we introduce DyViT, a hierarchical vision transformer that employs a Dynamic Multi-Window Self-Attention (DM-MSA), significantly reducing the parameters and FLOPs while improving fine-grained feature learning. Pre-trained on ImageNet-1K with CoMA, DyViT matches the downstream performance of MAE using only 12% of the pre-training epochs, demonstrating more effective learning. It also attains a 10% reduction in pre-training time per epoch, further underscoring its superior pre-training efficiency.
From Data to Modeling: Fully Open-vocabulary Scene Graph Generation
May 26, 2025We present OvSGTR, a novel transformer-based framework for fully open-vocabulary scene graph generation that overcomes the limitations of traditional closed-set models. Conventional methods restrict both object and relationship recognition to a fixed vocabulary, hindering their applicability to real-world scenarios where novel concepts frequently emerge. In contrast, our approach jointly predicts objects (nodes) and their inter-relationships (edges) beyond predefined categories. OvSGTR leverages a DETR-like architecture featuring a frozen image backbone and text encoder to extract high-quality visual and semantic features, which are then fused via a transformer decoder for end-to-end scene graph prediction. To enrich the model's understanding of complex visual relations, we propose a relation-aware pre-training strategy that synthesizes scene graph annotations in a weakly supervised manner. Specifically, we investigate three pipelines--scene parser-based, LLM-based, and multimodal LLM-based--to generate transferable supervision signals with minimal manual annotation. Furthermore, we address the common issue of catastrophic forgetting in open-vocabulary settings by incorporating a visual-concept retention mechanism coupled with a knowledge distillation strategy, ensuring that the model retains rich semantic cues during fine-tuning. Extensive experiments on the VG150 benchmark demonstrate that OvSGTR achieves state-of-the-art performance across multiple settings, including closed-set, open-vocabulary object detection-based, relation-based, and fully open-vocabulary scenarios. Our results highlight the promise of large-scale relation-aware pre-training and transformer architectures for advancing scene graph generation towards more generalized and reliable visual understanding.
HQC-NBV: A Hybrid Quantum-Classical View Planning Approach
May 08, 2025Efficient view planning is a fundamental challenge in computer vision and robotic perception, critical for tasks ranging from search and rescue operations to autonomous navigation. While classical approaches, including sampling-based and deterministic methods, have shown promise in planning camera viewpoints for scene exploration, they often struggle with computational scalability and solution optimality in complex settings. This study introduces HQC-NBV, a hybrid quantum-classical framework for view planning that leverages quantum properties to efficiently explore the parameter space while maintaining robustness and scalability. We propose a specific Hamiltonian formulation with multi-component cost terms and a parameter-centric variational ansatz with bidirectional alternating entanglement patterns that capture the hierarchical dependencies between viewpoint parameters. Comprehensive experiments demonstrate that quantum-specific components provide measurable performance advantages. Compared to the classical methods, our approach achieves up to 49.2% higher exploration efficiency across diverse environments. Our analysis of entanglement architecture and coherence-preserving terms provides insights into the mechanisms of quantum advantage in robotic exploration tasks. This work represents a significant advancement in integrating quantum computing into robotic perception systems, offering a paradigm-shifting solution for various robot vision tasks.
Compile Scene Graphs with Reinforcement Learning
Apr 18, 2025Next token prediction is the fundamental principle for training large language models (LLMs), and reinforcement learning (RL) further enhances their reasoning performance. As an effective way to model language, image, video, and other modalities, the use of LLMs for end-to-end extraction of structured visual representations, such as scene graphs, remains underexplored. It requires the model to accurately produce a set of objects and relationship triplets, rather than generating text token by token. To achieve this, we introduce R1-SGG, a multimodal LLM (M-LLM) initially trained via supervised fine-tuning (SFT) on the scene graph dataset and subsequently refined using reinforcement learning to enhance its ability to generate scene graphs in an end-to-end manner. The SFT follows a conventional prompt-response paradigm, while RL requires the design of effective reward signals. Given the structured nature of scene graphs, we design a graph-centric reward function that integrates node-level rewards, edge-level rewards, and a format consistency reward. Our experiments demonstrate that rule-based RL substantially enhances model performance in the SGG task, achieving a zero failure rate--unlike supervised fine-tuning (SFT), which struggles to generalize effectively. Our code is available at https://github.com/gpt4vision/R1-SGG.
VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning
Mar 17, 2025Videos, with their unique temporal dimension, demand precise grounded understanding, where answers are directly linked to visual, interpretable evidence. Despite significant breakthroughs in reasoning capabilities within Large Language Models, multi-modal reasoning - especially for videos - remains unexplored. In this work, we introduce VideoMind, a novel video-language agent designed for temporal-grounded video understanding. VideoMind incorporates two key innovations: (i) We identify essential capabilities for video temporal reasoning and develop a role-based agentic workflow, including a planner for coordinating different roles, a grounder for temporal localization, a verifier to assess temporal interval accuracy, and an answerer for question-answering. (ii) To efficiently integrate these diverse roles, we propose a novel Chain-of-LoRA strategy, enabling seamless role-switching via lightweight LoRA adaptors while avoiding the overhead of multiple models, thus balancing efficiency and flexibility. Extensive experiments on 14 public benchmarks demonstrate that our agent achieves state-of-the-art performance on diverse video understanding tasks, including 3 on grounded video question-answering, 6 on video temporal grounding, and 5 on general video question-answering, underscoring its effectiveness in advancing video agent and long-form temporal reasoning.
FedPCA: Noise-Robust Fair Federated Learning via Performance-Capacity Analysis
Mar 13, 2025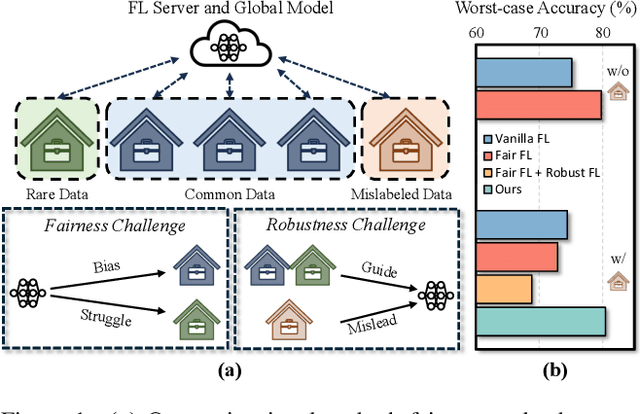

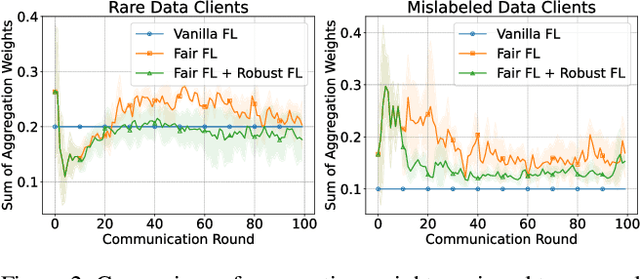
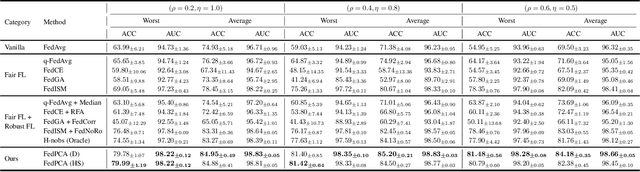
Training a model that effectively handles both common and rare data-i.e., achieving performance fairness-is crucial in federated learning (FL). While existing fair FL methods have shown effectiveness, they remain vulnerable to mislabeled data. Ensuring robustness in fair FL is therefore essential. However, fairness and robustness inherently compete, which causes robust strategies to hinder fairness. In this paper, we attribute this competition to the homogeneity in loss patterns exhibited by rare and mislabeled data clients, preventing existing loss-based fair and robust FL methods from effectively distinguishing and handling these two distinct client types. To address this, we propose performance-capacity analysis, which jointly considers model performance on each client and its capacity to handle the dataset, measured by loss and a newly introduced feature dispersion score. This allows mislabeled clients to be identified by their significantly deviated performance relative to capacity while preserving rare data clients. Building on this, we introduce FedPCA, an FL method that robustly achieves fairness. FedPCA first identifies mislabeled clients via a Gaussian Mixture Model on loss-dispersion pairs, then applies fairness and robustness strategies in global aggregation and local training by adjusting client weights and selectively using reliable data. Extensive experiments on three datasets demonstrate FedPCA's effectiveness in tackling this complex challenge. Code will be publicly available upon acceptance.
What Makes a Scene ? Scene Graph-based Evaluation and Feedback for Controllable Generation
Nov 23, 2024



While text-to-image generation has been extensively studied, generating images from scene graphs remains relatively underexplored, primarily due to challenges in accurately modeling spatial relationships and object interactions. To fill this gap, we introduce Scene-Bench, a comprehensive benchmark designed to evaluate and enhance the factual consistency in generating natural scenes. Scene-Bench comprises MegaSG, a large-scale dataset of one million images annotated with scene graphs, facilitating the training and fair comparison of models across diverse and complex scenes. Additionally, we propose SGScore, a novel evaluation metric that leverages chain-of-thought reasoning capabilities of multimodal large language models (LLMs) to assess both object presence and relationship accuracy, offering a more effective measure of factual consistency than traditional metrics like FID and CLIPScore. Building upon this evaluation framework, we develop a scene graph feedback pipeline that iteratively refines generated images by identifying and correcting discrepancies between the scene graph and the image. Extensive experiments demonstrate that Scene-Bench provides a more comprehensive and effective evaluation framework compared to existing benchmarks, particularly for complex scene generation. Furthermore, our feedback strategy significantly enhances the factual consistency of image generation models, advancing the field of controllable image generation.
E.T. Bench: Towards Open-Ended Event-Level Video-Language Understanding
Sep 26, 2024



Recent advances in Video Large Language Models (Video-LLMs) have demonstrated their great potential in general-purpose video understanding. To verify the significance of these models, a number of benchmarks have been proposed to diagnose their capabilities in different scenarios. However, existing benchmarks merely evaluate models through video-level question-answering, lacking fine-grained event-level assessment and task diversity. To fill this gap, we introduce E.T. Bench (Event-Level & Time-Sensitive Video Understanding Benchmark), a large-scale and high-quality benchmark for open-ended event-level video understanding. Categorized within a 3-level task taxonomy, E.T. Bench encompasses 7.3K samples under 12 tasks with 7K videos (251.4h total length) under 8 domains, providing comprehensive evaluations. We extensively evaluated 8 Image-LLMs and 12 Video-LLMs on our benchmark, and the results reveal that state-of-the-art models for coarse-level (video-level) understanding struggle to solve our fine-grained tasks, e.g., grounding event-of-interests within videos, largely due to the short video context length, improper time representations, and lack of multi-event training data. Focusing on these issues, we further propose a strong baseline model, E.T. Chat, together with an instruction-tuning dataset E.T. Instruct 164K tailored for fine-grained event-level understanding. Our simple but effective solution demonstrates superior performance in multiple scenarios.
Exploring Rich Subjective Quality Information for Image Quality Assessment in the Wild
Sep 09, 2024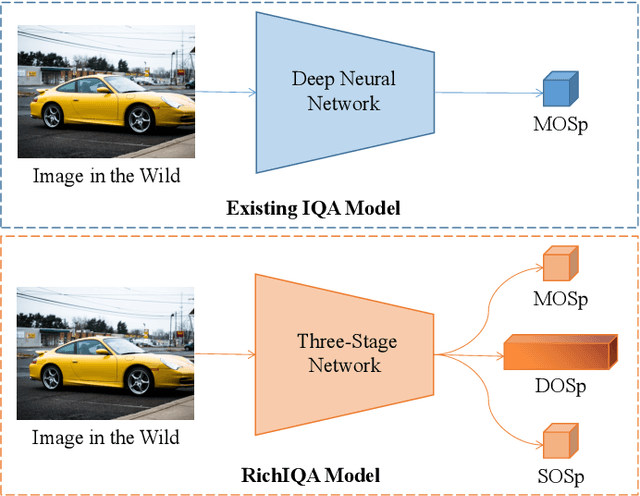



Traditional in the wild image quality assessment (IQA) models are generally trained with the quality labels of mean opinion score (MOS), while missing the rich subjective quality information contained in the quality ratings, for example, the standard deviation of opinion scores (SOS) or even distribution of opinion scores (DOS). In this paper, we propose a novel IQA method named RichIQA to explore the rich subjective rating information beyond MOS to predict image quality in the wild. RichIQA is characterized by two key novel designs: (1) a three-stage image quality prediction network which exploits the powerful feature representation capability of the Convolutional vision Transformer (CvT) and mimics the short-term and long-term memory mechanisms of human brain; (2) a multi-label training strategy in which rich subjective quality information like MOS, SOS and DOS are concurrently used to train the quality prediction network. Powered by these two novel designs, RichIQA is able to predict the image quality in terms of a distribution, from which the mean image quality can be subsequently obtained. Extensive experimental results verify that the three-stage network is tailored to predict rich quality information, while the multi-label training strategy can fully exploit the potentials within subjective quality rating and enhance the prediction performance and generalizability of the network. RichIQA outperforms state-of-the-art competitors on multiple large-scale in the wild IQA databases with rich subjective rating labels. The code of RichIQA will be made publicly available on GitHub.