 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerging Advances in Learned Video Compression: Models, Systems and Beyond
Apr 30, 2025Video compression is a fundamental topic in the visual intelligence, bridging visual signal sensing/capturing and high-level visual analytics. The broad success of artificial intelligence (AI) technology has enriched the horizon of video compression into novel paradigms by leveraging end-to-end optimized neural models. In this survey, we first provide a comprehensive and systematic overview of recent literature on end-to-end optimized learned video coding, covering the spectrum of pioneering efforts in both uni-directional and bi-directional prediction based compression model designation. We further delve into the optimization techniques employed in learned video compression (LVC), emphasizing their technical innovations, advantages. Some standardization progress is also reported. Furthermore, we investigate the system design and hardware implementation challenges of the LVC inclusively. Finally, we present the extensive simulation results to demonstrate the superior compression performance of LVC models, addressing the question that why learned codecs and AI-based video technology would have with broad impact on future visual intelligence research.
Exploring Rich Subjective Quality Information for Image Quality Assessment in the Wild
Sep 09, 2024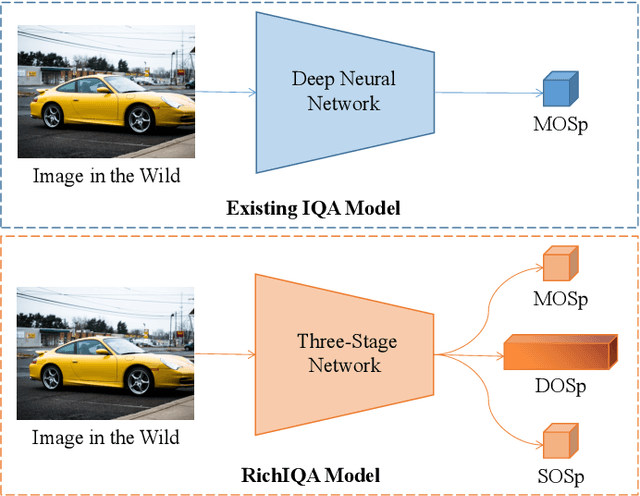



Traditional in the wild image quality assessment (IQA) models are generally trained with the quality labels of mean opinion score (MOS), while missing the rich subjective quality information contained in the quality ratings, for example, the standard deviation of opinion scores (SOS) or even distribution of opinion scores (DOS). In this paper, we propose a novel IQA method named RichIQA to explore the rich subjective rating information beyond MOS to predict image quality in the wild. RichIQA is characterized by two key novel designs: (1) a three-stage image quality prediction network which exploits the powerful feature representation capability of the Convolutional vision Transformer (CvT) and mimics the short-term and long-term memory mechanisms of human brain; (2) a multi-label training strategy in which rich subjective quality information like MOS, SOS and DOS are concurrently used to train the quality prediction network. Powered by these two novel designs, RichIQA is able to predict the image quality in terms of a distribution, from which the mean image quality can be subsequently obtained. Extensive experimental results verify that the three-stage network is tailored to predict rich quality information, while the multi-label training strategy can fully exploit the potentials within subjective quality rating and enhance the prediction performance and generalizability of the network. RichIQA outperforms state-of-the-art competitors on multiple large-scale in the wild IQA databases with rich subjective rating labels. The code of RichIQA will be made publicly available on GitHub.
MPAI-EEV: Standardization Efforts of Artificial Intelligence based End-to-End Video Coding
Sep 14, 2023



The rapid advancement of artificial intelligence (AI) technology has led to the prioritization of standardizing the processing, coding, and transmission of video using neural networks. To address this priority area, the Moving Picture, Audio, and Data Coding by Artificial Intelligence (MPAI) group is developing a suite of standards called MPAI-EEV for "end-to-end optimized neural video coding." The aim of this AI-based video standard project is to compress the number of bits required to represent high-fidelity video data by utilizing data-trained neural coding technologies. This approach is not constrained by how data coding has traditionally been applied in the context of a hybrid framework. This paper presents an overview of recent and ongoing standardization efforts in this area and highlights the key technologies and design philosophy of EEV. It also provides a comparison and report on some primary efforts such as the coding efficiency of the reference model. Additionally, it discusses emerging activities such as learned Unmanned-Aerial-Vehicles (UAVs) video coding which are currently planned, under development, or in the exploration phase. With a focus on UAV video signals, this paper addresses the current status of these preliminary efforts. It also indicates development timelines, summarizes the main technical details, and provides pointers to further points of reference. The exploration experiment shows that the EEV model performs better than the state-of-the-art video coding standard H.266/VVC in terms of perceptual evaluation metric.
Learning to Compress Unmanned Aerial Vehicle (UAV) Captured Video: Benchmark and Analysis
Jan 15, 2023



During the past decade, the Unmanned-Aerial-Vehicles (UAVs) have attracted increasing attention due to their flexible, extensive, and dynamic space-sensing capabilities. The volume of video captured by UAVs is exponentially growing along with the increased bitrate generated by the advancement of the sensors mounted on UAVs, bringing new challenges for on-device UAV storage and air-ground data transmission. Most existing video compression schemes were designed for natural scenes without consideration of specific texture and view characteristics of UAV videos. In this work, we first contribute a detailed analysis of the current state of the field of UAV video coding. Then we propose to establish a novel task for learned UAV video coding and construct a comprehensive and systematic benchmark for such a task, present a thorough review of high quality UAV video datasets and benchmarks, and contribute extensive rate-distortion efficiency comparison of learned and conventional codecs after. Finally, we discuss the challenges of encoding UAV videos. It is expected that the benchmark will accelerate the research and development in video coding on drone platforms.