 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Rich Subjective Quality Information for Image Quality Assessment in the Wild
Paper and Code
Sep 09, 2024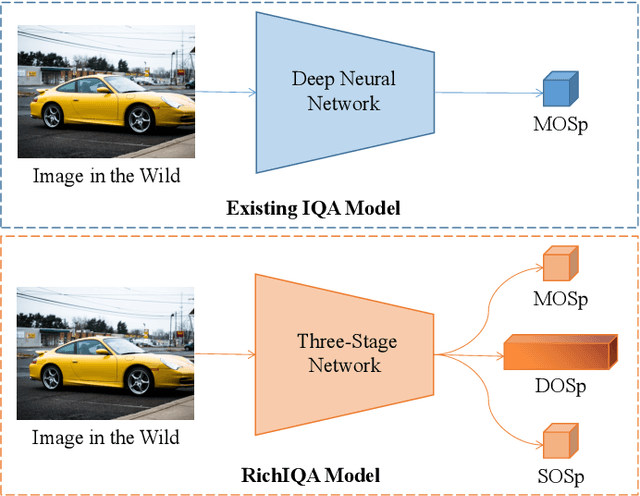



Traditional in the wild image quality assessment (IQA) models are generally trained with the quality labels of mean opinion score (MOS), while missing the rich subjective quality information contained in the quality ratings, for example, the standard deviation of opinion scores (SOS) or even distribution of opinion scores (DOS). In this paper, we propose a novel IQA method named RichIQA to explore the rich subjective rating information beyond MOS to predict image quality in the wild. RichIQA is characterized by two key novel designs: (1) a three-stage image quality prediction network which exploits the powerful feature representation capability of the Convolutional vision Transformer (CvT) and mimics the short-term and long-term memory mechanisms of human brain; (2) a multi-label training strategy in which rich subjective quality information like MOS, SOS and DOS are concurrently used to train the quality prediction network. Powered by these two novel designs, RichIQA is able to predict the image quality in terms of a distribution, from which the mean image quality can be subsequently obtained. Extensive experimental results verify that the three-stage network is tailored to predict rich quality information, while the multi-label training strategy can fully exploit the potentials within subjective quality rating and enhance the prediction performance and generalizability of the network. RichIQA outperforms state-of-the-art competitors on multiple large-scale in the wild IQA databases with rich subjective rating labels. The code of RichIQA will be made publicly available on GitHub.