 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidAudio-Bench: Benchmarking V2A and VT2A Generation across Four Audio Categories
Apr 12, 2026Video-to-Audio (V2A) generation is essential for immersive multimedia experiences, yet its evaluation remains underexplored. Existing benchmarks typically assess diverse audio types under a unified protocol, overlooking the fine-grained requirements of distinct audio categories. To address this gap, we propose VidAudio-Bench, a multi-task benchmark for V2A evaluation with four key features: (1) Broad Coverage: It encompasses four representative audio categories - sound effects, music, speech, and singing - under both V2A and Video-Text-to-Audio (VT2A) settings. (2) Extensive Evaluation: It comprises 1,634 video-text pairs and benchmarks 11 state-of-the-art generation models. (3) Comprehensive Metrics: It introduces 13 task-specific, reference-free metrics to systematically assess audio quality, video-audio consistency, and text-audio consistency. (4) Human Alignment: It validates all metrics through subjective studies, demonstrating strong consistency with human preferences. Experimental results reveal that current V2A models perform poorly in speech and singing compared to sound effects. Our VT2A results further highlight a fundamental tension between instruction following and visually grounded generation: stronger visual conditioning improves video-audio alignment, but often at the cost of generating the intended audio category. These findings establish VidAudio-Bench as a comprehensive and scalable framework for diagnosing V2A systems and provide new insights into multimodal audio generation.
A^3: Towards Advertising Aesthetic Assessment
Mar 25, 2026Advertising images significantly impact commercial conversion rates and brand equity, yet current evaluation methods rely on subjective judgments, lacking scalability, standardized criteria, and interpretability. To address these challenges, we present A^3 (Advertising Aesthetic Assessment), a comprehensive framework encompassing four components: a paradigm (A^3-Law), a dataset (A^3-Dataset), a multimodal large language model (A^3-Align), and a benchmark (A^3-Bench). Central to A^3 is a theory-driven paradigm, A^3-Law, comprising three hierarchical stages: (1) Perceptual Attention, evaluating perceptual image signals for their ability to attract attention; (2) Formal Interest, assessing formal composition of image color and spatial layout in evoking interest; and (3) Desire Impact, measuring desire evocation from images and their persuasive impact. Building on A^3-Law, we construct A^3-Dataset with 120K instruction-response pairs from 30K advertising images, each richly annotated with multi-dimensional labels and Chain-of-Thought (CoT) rationales. We further develop A^3-Align, trained under A^3-Law with CoT-guided learning on A^3-Dataset. Extensive experiments on A^3-Bench demonstrate that A^3-Align achieves superior alignment with A^3-Law compared to existing models, and this alignment generalizes well to quality advertisement selection and prescriptive advertisement critique, indicating its potential for broader deployment. Dataset, code, and models can be found at: https://github.com/euleryuan/A3-Align.
mmFHE: mmWave Sensing with End-to-End Fully Homomorphic Encryption
Mar 23, 2026We present mmFHE, the first system that enables fully homomorphic encryption (FHE) for end-to-end mmWave radar sensing. mmFHE encrypts raw range profiles on a lightweight edge device and executes the entire mmWave signal-processing and ML inference pipeline homomorphically on an untrusted cloud that operates exclusively on ciphertexts. At the core of mmFHE is a library of seven composable, data-oblivious FHE kernels that replace standard DSP routines with fixed arithmetic circuits. These kernels can be flexibly composed into different application-specific pipelines. We demonstrate this approach on two representative tasks: vital-sign monitoring and gesture recognition. We formally prove two cryptographic guarantees for any pipeline assembled from this library: input privacy, the cloud learns nothing about the sensor data; and data obliviousness, the execution trace is identical on the cloud regardless of the data being processed. These guarantees effectively neutralize various supervised and unsupervised privacy attacks on raw data, including re-identification and data-dependent privacy leakage. Evaluation on three public radar datasets (270 vital-sign recordings, 600 gesture trials) shows that encryption introduces negligible error: HR/RR MAE <10^-3 bpm versus plaintext, and 84.5% gesture accuracy (vs. 84.7% plaintext) with end-to-end cloud GPU latency of 103s for a 10s vital-sign window and 37s for a 3s gesture window. These results show that privacy-preserving end-to-end mmWave sensing is feasible on commodity hardware today.
Feasibility of Radio Frequency Based Wireless Sensing of Lead Contamination in Soil
Dec 18, 2025



Widespread Pb (lead) contamination of urban soil significantly impacts food safety and public health and hinders city greening efforts. However, most existing technologies for measuring Pb are labor-intensive and costly. In this study, we propose SoilScanner, a radio frequency-based wireless system that can detect Pb in soils. This is based on our discovery that the propagation of different frequency band radio signals is affected differently by different salts such as NaCl and Pb(NO3)2 in the soil. In a controlled experiment, manually adding NaCl and Pb(NO3)2 in clean soil, we demonstrated that different salts reflected signals at different frequencies in distinct patterns. In addition, we confirmed the finding using uncontrolled field samples with a machine learning model. Our experiment results show that SoilScanner can classify soil samples into low-Pb and high-Pb categories (threshold at 200 ppm) with an accuracy of 72%, with no sample with > 500 ppm of Pb being misclassified. The results of this study show that it is feasible to build portable and affordable Pb detection and screening devices based on wireless technology.
Audio-Assisted Face Video Restoration with Temporal and Identity Complementary Learning
Aug 06, 2025
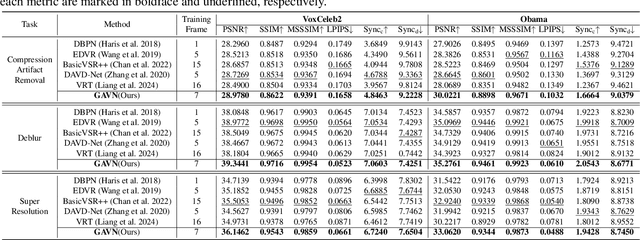
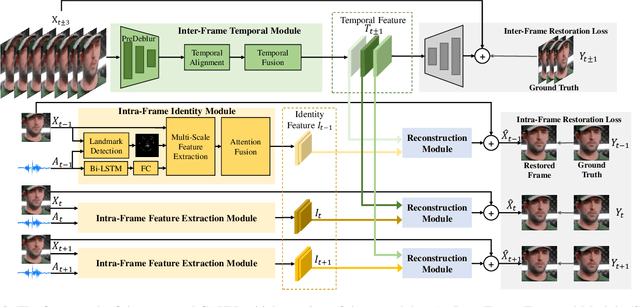
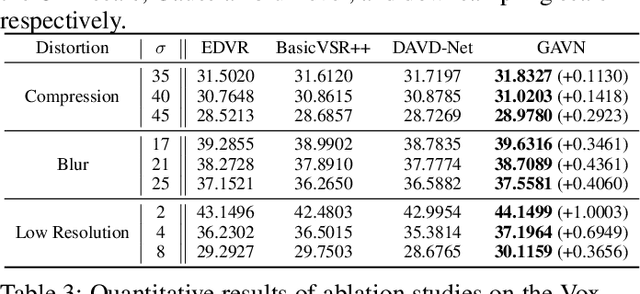
Face videos accompanied by audio have become integral to our daily lives, while they often suffer from complex degradations. Most face video restoration methods neglect the intrinsic correlations between the visual and audio features, especially in mouth regions. A few audio-aided face video restoration methods have been proposed, but they only focus on compression artifact removal. In this paper, we propose a General Audio-assisted face Video restoration Network (GAVN) to address various types of streaming video distortions via identity and temporal complementary learning. Specifically, GAVN first captures inter-frame temporal features in the low-resolution space to restore frames coarsely and save computational cost. Then, GAVN extracts intra-frame identity features in the high-resolution space with the assistance of audio signals and face landmarks to restore more facial details. Finally, the reconstruction module integrates temporal features and identity features to generate high-quality face videos. Experimental results demonstrate that GAVN outperforms the existing state-of-the-art methods on face video compression artifact removal, deblurring, and super-resolution. Codes will be released upon publication.
Exploring Image Quality Assessment from a New Perspective: Pupil Size
May 20, 2025This paper explores how the image quality assessment (IQA) task affects the cognitive processes of people from the perspective of pupil size and studies the relationship between pupil size and image quality. Specifically, we first invited subjects to participate in a subjective experiment, which includes two tasks: free observation and IQA. In the free observation task, subjects did not need to perform any action, and they only needed to observe images as they usually do with an album. In the IQA task, subjects were required to score images according to their overall impression of image quality. Then, by analyzing the difference in pupil size between the two tasks, we find that people may activate the visual attention mechanism when evaluating image quality. Meanwhile, we also find that the change in pupil size is closely related to image quality in the IQA task. For future research on IQA, this research can not only provide a theoretical basis for the objective IQA method and promote the development of more effective objective IQA methods, but also provide a new subjective IQA method for collecting the authentic subjective impression of image quality.
FVQ: A Large-Scale Dataset and A LMM-based Method for Face Video Quality Assessment
Apr 12, 2025



Face video quality assessment (FVQA) deserves to be explored in addition to general video quality assessment (VQA), as face videos are the primary content on social media platforms and human visual system (HVS) is particularly sensitive to human faces. However, FVQA is rarely explored due to the lack of large-scale FVQA datasets. To fill this gap, we present the first large-scale in-the-wild FVQA dataset, FVQ-20K, which contains 20,000 in-the-wild face videos together with corresponding mean opinion score (MOS) annotations. Along with the FVQ-20K dataset, we further propose a specialized FVQA method named FVQ-Rater to achieve human-like rating and scoring for face video, which is the first attempt to explore the potential of large multimodal models (LMMs) for the FVQA task. Concretely, we elaborately extract multi-dimensional features including spatial features, temporal features, and face-specific features (i.e., portrait features and face embeddings) to provide comprehensive visual information, and take advantage of the LoRA-based instruction tuning technique to achieve quality-specific fine-tuning, which shows superior performance on both FVQ-20K and CFVQA datasets. Extensive experiments and comprehensive analysis demonstrate the significant potential of the FVQ-20K dataset and FVQ-Rater method in promoting the development of FVQA.
Mitigating Low-Level Visual Hallucinations Requires Self-Awareness: Database, Model and Training Strategy
Mar 27, 2025



The rapid development of multimodal large language models has resulted in remarkable advancements in visual perception and understanding, consolidating several tasks into a single visual question-answering framework. However, these models are prone to hallucinations, which limit their reliability as artificial intelligence systems. While this issue is extensively researched in natural language processing and image captioning, there remains a lack of investigation of hallucinations in Low-level Visual Perception and Understanding (HLPU), especially in the context of image quality assessment tasks. We consider that these hallucinations arise from an absence of clear self-awareness within the models. To address this issue, we first introduce the HLPU instruction database, the first instruction database specifically focused on hallucinations in low-level vision tasks. This database contains approximately 200K question-answer pairs and comprises four subsets, each covering different types of instructions. Subsequently, we propose the Self-Awareness Failure Elimination (SAFEQA) model, which utilizes image features, salient region features and quality features to improve the perception and comprehension abilities of the model in low-level vision tasks. Furthermore, we propose the Enhancing Self-Awareness Preference Optimization (ESA-PO) framework to increase the model's awareness of knowledge boundaries, thereby mitigating the incidence of hallucination. Finally, we conduct comprehensive experiments on low-level vision tasks, with the results demonstrating that our proposed method significantly enhances self-awareness of the model in these tasks and reduces hallucinations. Notably, our proposed method improves both accuracy and self-awareness of the proposed model and outperforms close-source models in terms of various evaluation metrics.
AGAV-Rater: Adapting Large Multimodal Model for AI-Generated Audio-Visual Quality Assessment
Jan 30, 2025



Many video-to-audio (VTA) methods have been proposed for dubbing silent AI-generated videos. An efficient quality assessment method for AI-generated audio-visual content (AGAV) is crucial for ensuring audio-visual quality. Existing audio-visual quality assessment methods struggle with unique distortions in AGAVs, such as unrealistic and inconsistent elements. To address this, we introduce AGAVQA, the first large-scale AGAV quality assessment dataset, comprising 3,382 AGAVs from 16 VTA methods. AGAVQA includes two subsets: AGAVQA-MOS, which provides multi-dimensional scores for audio quality, content consistency, and overall quality, and AGAVQA-Pair, designed for optimal AGAV pair selection. We further propose AGAV-Rater, a LMM-based model that can score AGAVs, as well as audio and music generated from text, across multiple dimensions, and selects the best AGAV generated by VTA methods to present to the user. AGAV-Rater achieves state-of-the-art performance on AGAVQA, Text-to-Audio, and Text-to-Music datasets. Subjective tests also confirm that AGAV-Rater enhances VTA performance and user experience. The project page is available at https://agav-rater.github.io.
Exploring Rich Subjective Quality Information for Image Quality Assessment in the Wild
Sep 09, 2024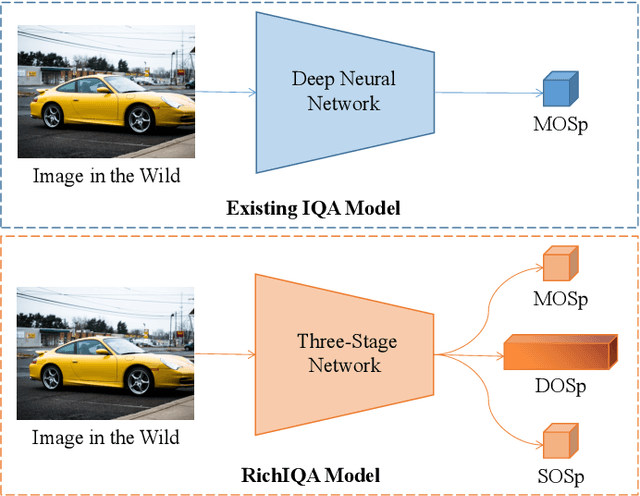



Traditional in the wild image quality assessment (IQA) models are generally trained with the quality labels of mean opinion score (MOS), while missing the rich subjective quality information contained in the quality ratings, for example, the standard deviation of opinion scores (SOS) or even distribution of opinion scores (DOS). In this paper, we propose a novel IQA method named RichIQA to explore the rich subjective rating information beyond MOS to predict image quality in the wild. RichIQA is characterized by two key novel designs: (1) a three-stage image quality prediction network which exploits the powerful feature representation capability of the Convolutional vision Transformer (CvT) and mimics the short-term and long-term memory mechanisms of human brain; (2) a multi-label training strategy in which rich subjective quality information like MOS, SOS and DOS are concurrently used to train the quality prediction network. Powered by these two novel designs, RichIQA is able to predict the image quality in terms of a distribution, from which the mean image quality can be subsequently obtained. Extensive experimental results verify that the three-stage network is tailored to predict rich quality information, while the multi-label training strategy can fully exploit the potentials within subjective quality rating and enhance the prediction performance and generalizability of the network. RichIQA outperforms state-of-the-art competitors on multiple large-scale in the wild IQA databases with rich subjective rating labels. The code of RichIQA will be made publicly available on GitHub.