 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
LoViF 2026 Challenge on Human-oriented Semantic Image Quality Assessment: Methods and Results
Apr 13, 2026This paper reviews the LoViF 2026 Challenge on Human-oriented Semantic Image Quality Assessment. This challenge aims to raise a new direction, i.e., how to evaluate the loss of semantic information from the human perspective, intending to promote the development of some new directions, like semantic coding, processing, and semantic-oriented optimization, etc. Unlike existing datasets of quality assessment, we form a dataset of human-oriented semantic quality assessment, termed the SeIQA dataset. This dataset is divided into three parts for this competition: (i) training data: 510 pairs of degraded images and their corresponding ground truth references; (ii) validation data: 80 pairs of degraded images and their corresponding ground-truth references; (iii) testing data: 160 pairs of degraded images and their corresponding ground-truth references. The primary objective of this challenge is to establish a new and powerful benchmark for human-oriented semantic image quality assessment. There are a total of 58 teams registered in this competition, and 6 teams submitted valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the SeIQA dataset.
QualiRAG: Retrieval-Augmented Generation for Visual Quality Understanding
Jan 26, 2026Visual quality assessment (VQA) is increasingly shifting from scalar score prediction toward interpretable quality understanding -- a paradigm that demands \textit{fine-grained spatiotemporal perception} and \textit{auxiliary contextual information}. Current approaches rely on supervised fine-tuning or reinforcement learning on curated instruction datasets, which involve labor-intensive annotation and are prone to dataset-specific biases. To address these challenges, we propose \textbf{QualiRAG}, a \textit{training-free} \textbf{R}etrieval-\textbf{A}ugmented \textbf{G}eneration \textbf{(RAG)} framework that systematically leverages the latent perceptual knowledge of large multimodal models (LMMs) for visual quality perception. Unlike conventional RAG that retrieves from static corpora, QualiRAG dynamically generates auxiliary knowledge by decomposing questions into structured requests and constructing four complementary knowledge sources: \textit{visual metadata}, \textit{subject localization}, \textit{global quality summaries}, and \textit{local quality descriptions}, followed by relevance-aware retrieval for evidence-grounded reasoning. Extensive experiments show that QualiRAG achieves substantial improvements over open-source general-purpose LMMs and VQA-finetuned LMMs on visual quality understanding tasks, and delivers competitive performance on visual quality comparison tasks, demonstrating robust quality assessment capabilities without any task-specific training. The code will be publicly available at https://github.com/clh124/QualiRAG.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
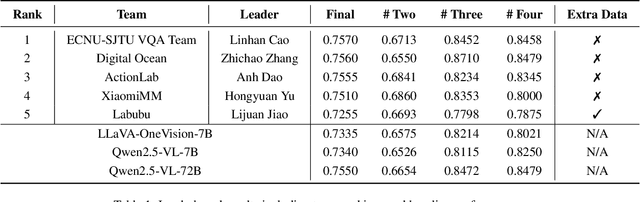
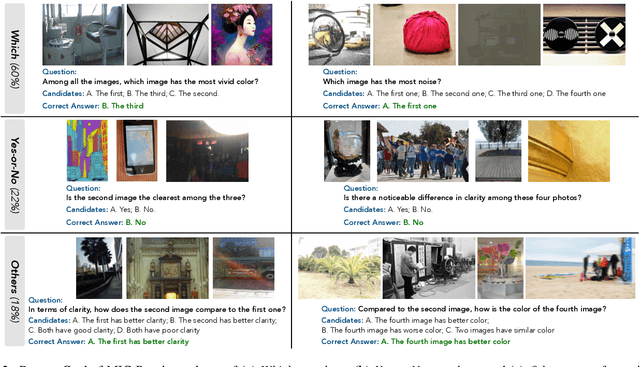
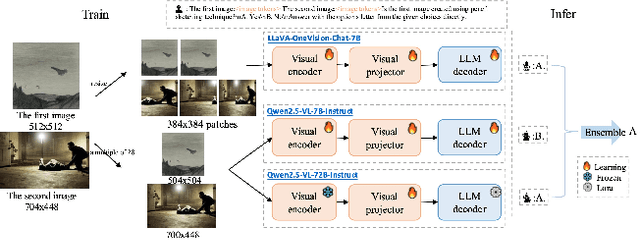
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
AIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html
Assessing UHD Image Quality from Aesthetics, Distortions, and Saliency
Sep 01, 2024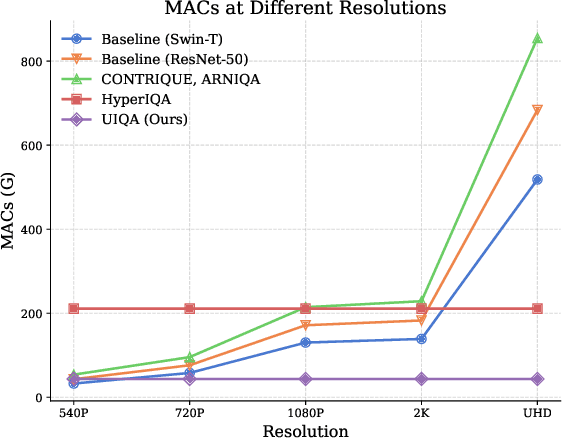
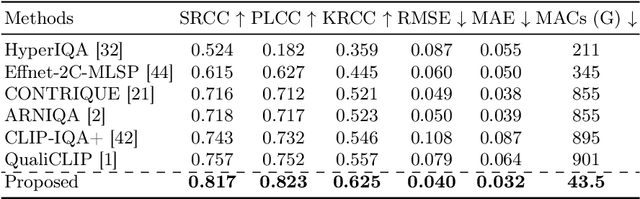

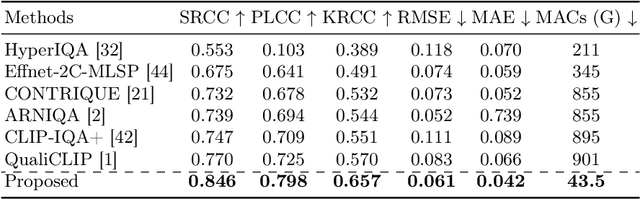
UHD images, typically with resolutions equal to or higher than 4K, pose a significant challenge for efficient image quality assessment (IQA) algorithms, as adopting full-resolution images as inputs leads to overwhelming computational complexity and commonly used pre-processing methods like resizing or cropping may cause substantial loss of detail. To address this problem, we design a multi-branch deep neural network (DNN) to assess the quality of UHD images from three perspectives: global aesthetic characteristics, local technical distortions, and salient content perception. Specifically, aesthetic features are extracted from low-resolution images downsampled from the UHD ones, which lose high-frequency texture information but still preserve the global aesthetics characteristics. Technical distortions are measured using a fragment image composed of mini-patches cropped from UHD images based on the grid mini-patch sampling strategy. The salient content of UHD images is detected and cropped to extract quality-aware features from the salient regions. We adopt the Swin Transformer Tiny as the backbone networks to extract features from these three perspectives. The extracted features are concatenated and regressed into quality scores by a two-layer multi-layer perceptron (MLP) network. We employ the mean square error (MSE) loss to optimize prediction accuracy and the fidelity loss to optimize prediction monotonicity. Experimental results show that the proposed model achieves the best performance on the UHD-IQA dataset while maintaining the lowest computational complexity, demonstrating its effectiveness and efficiency. Moreover, the proposed model won first prize in ECCV AIM 2024 UHD-IQA Challenge. The code is available at https://github.com/sunwei925/UIQA.
Dual-Branch Network for Portrait Image Quality Assessment
May 14, 2024

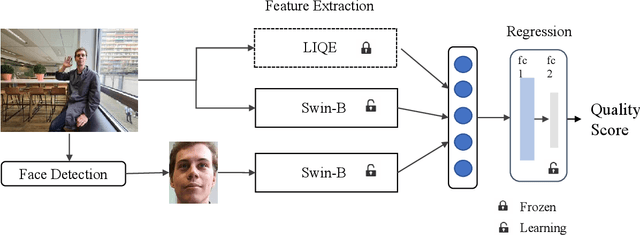
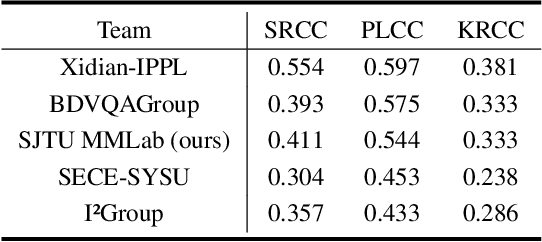
Portrait images typically consist of a salient person against diverse backgrounds. With the development of mobile devices and image processing techniques, users can conveniently capture portrait images anytime and anywhere. However, the quality of these portraits may suffer from the degradation caused by unfavorable environmental conditions, subpar photography techniques, and inferior capturing devices. In this paper, we introduce a dual-branch network for portrait image quality assessment (PIQA), which can effectively address how the salient person and the background of a portrait image influence its visual quality. Specifically, we utilize two backbone networks (\textit{i.e.,} Swin Transformer-B) to extract the quality-aware features from the entire portrait image and the facial image cropped from it. To enhance the quality-aware feature representation of the backbones, we pre-train them on the large-scale video quality assessment dataset LSVQ and the large-scale facial image quality assessment dataset GFIQA. Additionally, we leverage LIQE, an image scene classification and quality assessment model, to capture the quality-aware and scene-specific features as the auxiliary features. Finally, we concatenate these features and regress them into quality scores via a multi-perception layer (MLP). We employ the fidelity loss to train the model via a learning-to-rank manner to mitigate inconsistencies in quality scores in the portrait image quality assessment dataset PIQ. Experimental results demonstrate that the proposed model achieves superior performance in the PIQ dataset, validating its effectiveness. The code is available at \url{https://github.com/sunwei925/DN-PIQA.git}.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024



This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
AIGIQA-20K: A Large Database for AI-Generated Image Quality Assessment
Apr 04, 2024



With the rapid advancements in AI-Generated Content (AIGC), AI-Generated Images (AIGIs) have been widely applied in entertainment, education, and social media. However, due to the significant variance in quality among different AIGIs, there is an urgent need for models that consistently match human subjective ratings. To address this issue, we organized a challenge towards AIGC quality assessment on NTIRE 2024 that extensively considers 15 popular generative models, utilizing dynamic hyper-parameters (including classifier-free guidance, iteration epochs, and output image resolution), and gather subjective scores that consider perceptual quality and text-to-image alignment altogether comprehensively involving 21 subjects. This approach culminates in the creation of the largest fine-grained AIGI subjective quality database to date with 20,000 AIGIs and 420,000 subjective ratings, known as AIGIQA-20K. Furthermore, we conduct benchmark experiments on this database to assess the correspondence between 16 mainstream AIGI quality models and human perception. We anticipate that this large-scale quality database will inspire robust quality indicators for AIGIs and propel the evolution of AIGC for vision. The database is released on https://www.modelscope.cn/datasets/lcysyzxdxc/AIGCQA-30K-Image.