 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditHF-1M: A Million-Scale Rich Human Preference Feedback for Image Editing
Mar 16, 2026Recent text-guided image editing (TIE) models have achieved remarkable progress, while many edited images still suffer from issues such as artifacts, unexpected editings, unaesthetic contents. Although some benchmarks and methods have been proposed for evaluating edited images, scalable evaluation models are still lacking, which limits the development of human feedback reward models for image editing. To address the challenges, we first introduce \textbf{EditHF-1M}, a million-scale image editing dataset with over 29M human preference pairs and 148K human mean opinion ratings, both evaluated from three dimensions, \textit{i.e.}, visual quality, instruction alignment, and attribute preservation. Based on EditHF-1M, we propose \textbf{EditHF}, a multimodal large language model (MLLM) based evaluation model, to provide human-aligned feedback from image editing. Finally, we introduce \textbf{EditHF-Reward}, which utilizes EditHF as the reward signal to optimize the text-guided image editing models through reinforcement learning. Extensive experiments show that EditHF achieves superior alignment with human preferences and demonstrates strong generalization on other datasets. Furthermore, we fine-tune the Qwen-Image-Edit using EditHF-Reward, achieving significant performance improvements, which demonstrates the ability of EditHF to serve as a reward model to scale-up the image editing. Both the dataset and code will be released in our GitHub repository: https://github.com/IntMeGroup/EditHF.
Human-Activity AGV Quality Assessment: A Benchmark Dataset and an Objective Evaluation Metric
Nov 25, 2024



AI-driven video generation techniques have made significant progress in recent years. However, AI-generated videos (AGVs) involving human activities often exhibit substantial visual and semantic distortions, hindering the practical application of video generation technologies in real-world scenarios. To address this challenge, we conduct a pioneering study on human activity AGV quality assessment, focusing on visual quality evaluation and the identification of semantic distortions. First, we construct the AI-Generated Human activity Video Quality Assessment (Human-AGVQA) dataset, consisting of 3,200 AGVs derived from 8 popular text-to-video (T2V) models using 400 text prompts that describe diverse human activities. We conduct a subjective study to evaluate the human appearance quality, action continuity quality, and overall video quality of AGVs, and identify semantic issues of human body parts. Based on Human-AGVQA, we benchmark the performance of T2V models and analyze their strengths and weaknesses in generating different categories of human activities. Second, we develop an objective evaluation metric, named AI-Generated Human activity Video Quality metric (GHVQ), to automatically analyze the quality of human activity AGVs. GHVQ systematically extracts human-focused quality features, AI-generated content-aware quality features, and temporal continuity features, making it a comprehensive and explainable quality metric for human activity AGVs. The extensive experimental results show that GHVQ outperforms existing quality metrics on the Human-AGVQA dataset by a large margin, demonstrating its efficacy in assessing the quality of human activity AGVs. The Human-AGVQA dataset and GHVQ metric will be released in public at https://github.com/zczhang-sjtu/GHVQ.git
LMM-VQA: Advancing Video Quality Assessment with Large Multimodal Models
Aug 26, 2024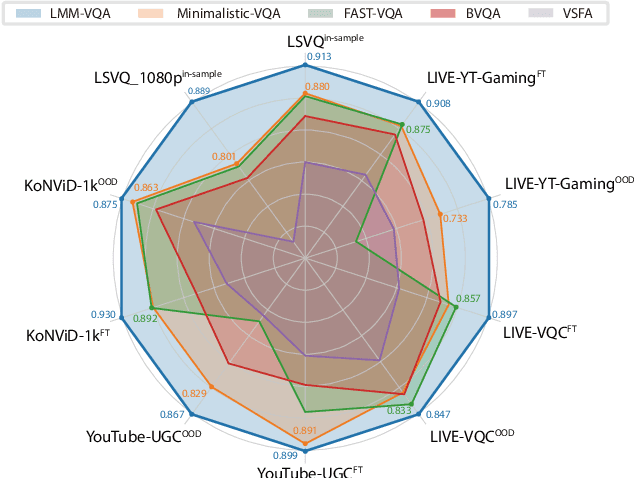

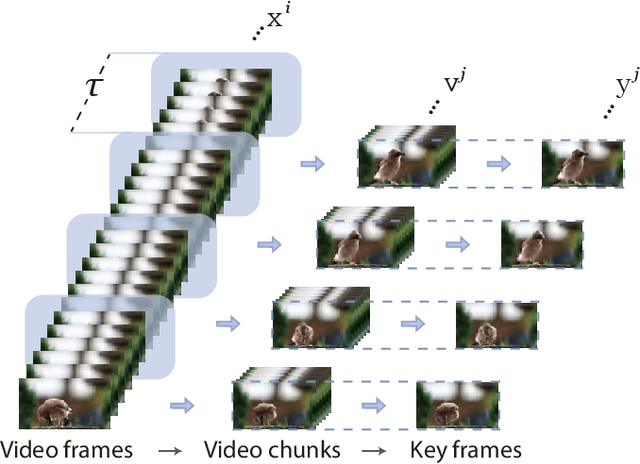
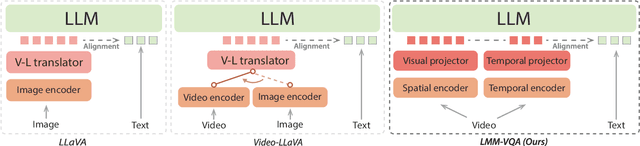
The explosive growth of videos on streaming media platforms has underscored the urgent need for effective video quality assessment (VQA) algorithms to monitor and perceptually optimize the quality of streaming videos. However, VQA remains an extremely challenging task due to the diverse video content and the complex spatial and temporal distortions, thus necessitating more advanced methods to address these issues. Nowadays, large multimodal models (LMMs), such as GPT-4V, have exhibited strong capabilities for various visual understanding tasks, motivating us to leverage the powerful multimodal representation ability of LMMs to solve the VQA task. Therefore, we propose the first Large Multi-Modal Video Quality Assessment (LMM-VQA) model, which introduces a novel spatiotemporal visual modeling strategy for quality-aware feature extraction. Specifically, we first reformulate the quality regression problem into a question and answering (Q&A) task and construct Q&A prompts for VQA instruction tuning. Then, we design a spatiotemporal vision encoder to extract spatial and temporal features to represent the quality characteristics of videos, which are subsequently mapped into the language space by the spatiotemporal projector for modality alignment. Finally, the aligned visual tokens and the quality-inquired text tokens are aggregated as inputs for the large language model (LLM) to generate the quality score and level. Extensive experiments demonstrate that LMM-VQA achieves state-of-the-art performance across five VQA benchmarks, exhibiting an average improvement of $5\%$ in generalization ability over existing methods. Furthermore, due to the advanced design of the spatiotemporal encoder and projector, LMM-VQA also performs exceptionally well on general video understanding tasks, further validating its effectiveness. Our code will be released at https://github.com/Sueqk/LMM-VQA.
Benchmarking AIGC Video Quality Assessment: A Dataset and Unified Model
Jul 31, 2024



In recent years, artificial intelligence (AI) driven video generation has garnered significant attention due to advancements in stable diffusion and large language model techniques. Thus, there is a great demand for accurate video quality assessment (VQA) models to measure the perceptual quality of AI-generated content (AIGC) videos as well as optimize video generation techniques. However, assessing the quality of AIGC videos is quite challenging due to the highly complex distortions they exhibit (e.g., unnatural action, irrational objects, etc.). Therefore, in this paper, we try to systemically investigate the AIGC-VQA problem from both subjective and objective quality assessment perspectives. For the subjective perspective, we construct a Large-scale Generated Vdeo Quality assessment (LGVQ) dataset, consisting of 2,808 AIGC videos generated by 6 video generation models using 468 carefully selected text prompts. Unlike previous subjective VQA experiments, we evaluate the perceptual quality of AIGC videos from three dimensions: spatial quality, temporal quality, and text-to-video alignment, which hold utmost importance for current video generation techniques. For the objective perspective, we establish a benchmark for evaluating existing quality assessment metrics on the LGVQ dataset, which reveals that current metrics perform poorly on the LGVQ dataset. Thus, we propose a Unify Generated Video Quality assessment (UGVQ) model to comprehensively and accurately evaluate the quality of AIGC videos across three aspects using a unified model, which uses visual, textual and motion features of video and corresponding prompt, and integrates key features to enhance feature expression. We hope that our benchmark can promote the development of quality evaluation metrics for AIGC videos. The LGVQ dataset and the UGVQ metric will be publicly released.
Dual-Branch Network for Portrait Image Quality Assessment
May 14, 2024

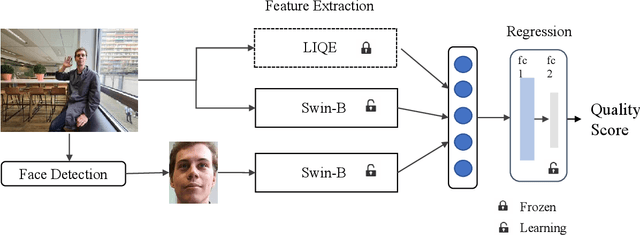
Portrait images typically consist of a salient person against diverse backgrounds. With the development of mobile devices and image processing techniques, users can conveniently capture portrait images anytime and anywhere. However, the quality of these portraits may suffer from the degradation caused by unfavorable environmental conditions, subpar photography techniques, and inferior capturing devices. In this paper, we introduce a dual-branch network for portrait image quality assessment (PIQA), which can effectively address how the salient person and the background of a portrait image influence its visual quality. Specifically, we utilize two backbone networks (\textit{i.e.,} Swin Transformer-B) to extract the quality-aware features from the entire portrait image and the facial image cropped from it. To enhance the quality-aware feature representation of the backbones, we pre-train them on the large-scale video quality assessment dataset LSVQ and the large-scale facial image quality assessment dataset GFIQA. Additionally, we leverage LIQE, an image scene classification and quality assessment model, to capture the quality-aware and scene-specific features as the auxiliary features. Finally, we concatenate these features and regress them into quality scores via a multi-perception layer (MLP). We employ the fidelity loss to train the model via a learning-to-rank manner to mitigate inconsistencies in quality scores in the portrait image quality assessment dataset PIQ. Experimental results demonstrate that the proposed model achieves superior performance in the PIQ dataset, validating its effectiveness. The code is available at \url{https://github.com/sunwei925/DN-PIQA.git}.
Q-Boost: On Visual Quality Assessment Ability of Low-level Multi-Modality Foundation Models
Dec 23, 2023Recent advancements in Multi-modality Large Language Models (MLLMs) have demonstrated remarkable capabilities in complex high-level vision tasks. However, the exploration of MLLM potential in visual quality assessment, a vital aspect of low-level vision, remains limited. To address this gap, we introduce Q-Boost, a novel strategy designed to enhance low-level MLLMs in image quality assessment (IQA) and video quality assessment (VQA) tasks, which is structured around two pivotal components: 1) Triadic-Tone Integration: Ordinary prompt design simply oscillates between the binary extremes of $positive$ and $negative$. Q-Boost innovates by incorporating a `middle ground' approach through $neutral$ prompts, allowing for a more balanced and detailed assessment. 2) Multi-Prompt Ensemble: Multiple quality-centric prompts are used to mitigate bias and acquire more accurate evaluation. The experimental results show that the low-level MLLMs exhibit outstanding zeros-shot performance on the IQA/VQA tasks equipped with the Q-Boost strategy.