 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Graph Explanation to Operator Fusion
Dec 31, 2024



Layer fusion techniques are critical to improving the inference efficiency of deep neural networks (DNN) for deployment. Fusion aims to lower inference costs by reducing data transactions between an accelerator's on-chip buffer and DRAM. This is accomplished by grouped execution of multiple operations like convolution and activations together into single execution units - fusion groups. However, on-chip buffer capacity limits fusion group size and optimizing fusion on whole DNNs requires partitioning into multiple fusion groups. Finding the optimal groups is a complex problem where the presence of invalid solutions hampers traditional search algorithms and demands robust approaches. In this paper we incorporate Explainable AI, specifically Graph Explanation Techniques (GET), into layer fusion. Given an invalid fusion group, we identify the operations most responsible for group invalidity, then use this knowledge to recursively split the original fusion group via a greedy tree-based algorithm to minimize DRAM access. We pair our scheme with common algorithms and optimize DNNs on two types of layer fusion: Line-Buffer Depth First (LBDF) and Branch Requirement Reduction (BRR). Experiments demonstrate the efficacy of our scheme on several popular and classical convolutional neural networks like ResNets and MobileNets. Our scheme achieves over 20% DRAM Access reduction on EfficientNet-B3.
Human-Activity AGV Quality Assessment: A Benchmark Dataset and an Objective Evaluation Metric
Nov 25, 2024



AI-driven video generation techniques have made significant progress in recent years. However, AI-generated videos (AGVs) involving human activities often exhibit substantial visual and semantic distortions, hindering the practical application of video generation technologies in real-world scenarios. To address this challenge, we conduct a pioneering study on human activity AGV quality assessment, focusing on visual quality evaluation and the identification of semantic distortions. First, we construct the AI-Generated Human activity Video Quality Assessment (Human-AGVQA) dataset, consisting of 3,200 AGVs derived from 8 popular text-to-video (T2V) models using 400 text prompts that describe diverse human activities. We conduct a subjective study to evaluate the human appearance quality, action continuity quality, and overall video quality of AGVs, and identify semantic issues of human body parts. Based on Human-AGVQA, we benchmark the performance of T2V models and analyze their strengths and weaknesses in generating different categories of human activities. Second, we develop an objective evaluation metric, named AI-Generated Human activity Video Quality metric (GHVQ), to automatically analyze the quality of human activity AGVs. GHVQ systematically extracts human-focused quality features, AI-generated content-aware quality features, and temporal continuity features, making it a comprehensive and explainable quality metric for human activity AGVs. The extensive experimental results show that GHVQ outperforms existing quality metrics on the Human-AGVQA dataset by a large margin, demonstrating its efficacy in assessing the quality of human activity AGVs. The Human-AGVQA dataset and GHVQ metric will be released in public at https://github.com/zczhang-sjtu/GHVQ.git
Newclid: A User-Friendly Replacement for AlphaGeometry
Nov 18, 2024



We introduce a new symbolic solver for geometry, called Newclid, which is based on AlphaGeometry. Newclid contains a symbolic solver called DDARN (derived from DDAR-Newclid), which is a significant refactoring and upgrade of AlphaGeometry's DDAR symbolic solver by being more user-friendly - both for the end user as well as for a programmer wishing to extend the codebase. For the programmer, improvements include a modularized codebase and new debugging and visualization tools. For the user, Newclid contains a new command line interface (CLI) that provides interfaces for agents to guide DDARN. DDARN is flexible with respect to its internal reasoning, which can be steered by agents. Further, we support input from GeoGebra to make Newclid accessible for educational contexts. Further, the scope of problems that Newclid can solve has been expanded to include the ability to have an improved understanding of metric geometry concepts (length, angle) and to use theorems such as the Pythagorean theorem in proofs. Bugs have been fixed, and reproducibility has been improved. Lastly, we re-evaluated the five remaining problems from the original AG-30 dataset that AlphaGeometry was not able to solve and contrasted them with the abilities of DDARN, running in breadth-first-search agentic mode (which corresponds to how DDARN runs by default), finding that DDARN solves an additional problem. We have open-sourced our code under: https://github.com/LMCRC/Newclid
LMM-VQA: Advancing Video Quality Assessment with Large Multimodal Models
Aug 26, 2024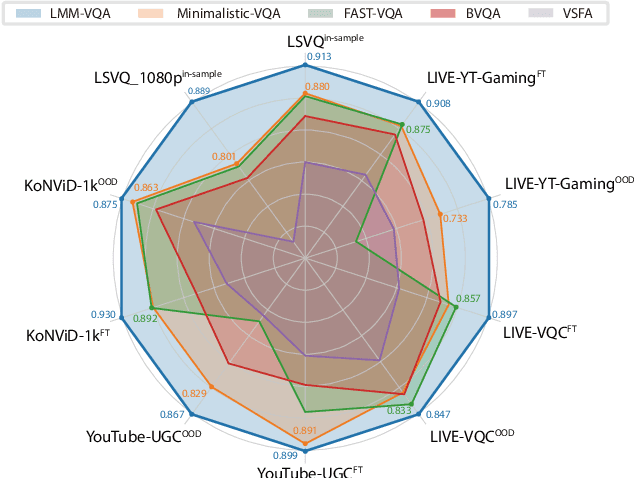

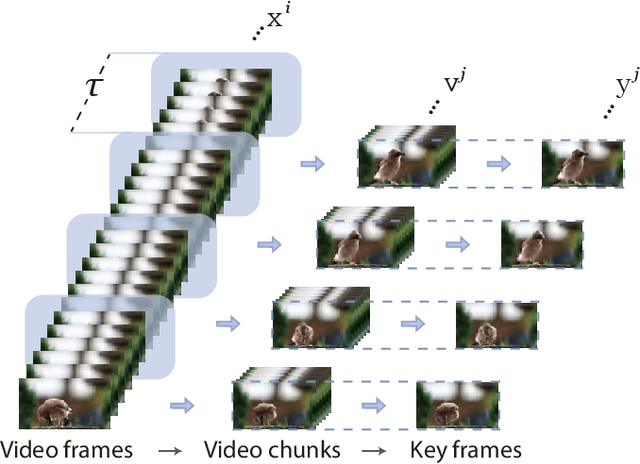
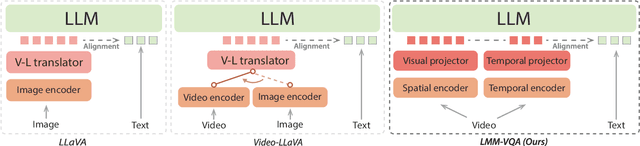
The explosive growth of videos on streaming media platforms has underscored the urgent need for effective video quality assessment (VQA) algorithms to monitor and perceptually optimize the quality of streaming videos. However, VQA remains an extremely challenging task due to the diverse video content and the complex spatial and temporal distortions, thus necessitating more advanced methods to address these issues. Nowadays, large multimodal models (LMMs), such as GPT-4V, have exhibited strong capabilities for various visual understanding tasks, motivating us to leverage the powerful multimodal representation ability of LMMs to solve the VQA task. Therefore, we propose the first Large Multi-Modal Video Quality Assessment (LMM-VQA) model, which introduces a novel spatiotemporal visual modeling strategy for quality-aware feature extraction. Specifically, we first reformulate the quality regression problem into a question and answering (Q&A) task and construct Q&A prompts for VQA instruction tuning. Then, we design a spatiotemporal vision encoder to extract spatial and temporal features to represent the quality characteristics of videos, which are subsequently mapped into the language space by the spatiotemporal projector for modality alignment. Finally, the aligned visual tokens and the quality-inquired text tokens are aggregated as inputs for the large language model (LLM) to generate the quality score and level. Extensive experiments demonstrate that LMM-VQA achieves state-of-the-art performance across five VQA benchmarks, exhibiting an average improvement of $5\%$ in generalization ability over existing methods. Furthermore, due to the advanced design of the spatiotemporal encoder and projector, LMM-VQA also performs exceptionally well on general video understanding tasks, further validating its effectiveness. Our code will be released at https://github.com/Sueqk/LMM-VQA.
Benchmarking AIGC Video Quality Assessment: A Dataset and Unified Model
Jul 31, 2024



In recent years, artificial intelligence (AI) driven video generation has garnered significant attention due to advancements in stable diffusion and large language model techniques. Thus, there is a great demand for accurate video quality assessment (VQA) models to measure the perceptual quality of AI-generated content (AIGC) videos as well as optimize video generation techniques. However, assessing the quality of AIGC videos is quite challenging due to the highly complex distortions they exhibit (e.g., unnatural action, irrational objects, etc.). Therefore, in this paper, we try to systemically investigate the AIGC-VQA problem from both subjective and objective quality assessment perspectives. For the subjective perspective, we construct a Large-scale Generated Vdeo Quality assessment (LGVQ) dataset, consisting of 2,808 AIGC videos generated by 6 video generation models using 468 carefully selected text prompts. Unlike previous subjective VQA experiments, we evaluate the perceptual quality of AIGC videos from three dimensions: spatial quality, temporal quality, and text-to-video alignment, which hold utmost importance for current video generation techniques. For the objective perspective, we establish a benchmark for evaluating existing quality assessment metrics on the LGVQ dataset, which reveals that current metrics perform poorly on the LGVQ dataset. Thus, we propose a Unify Generated Video Quality assessment (UGVQ) model to comprehensively and accurately evaluate the quality of AIGC videos across three aspects using a unified model, which uses visual, textual and motion features of video and corresponding prompt, and integrates key features to enhance feature expression. We hope that our benchmark can promote the development of quality evaluation metrics for AIGC videos. The LGVQ dataset and the UGVQ metric will be publicly released.
Rethinking Optimization and Architecture for Tiny Language Models
Feb 06, 2024



The power of large language models (LLMs) has been demonstrated through numerous data and computing resources. However, the application of language models on mobile devices is facing huge challenge on the computation and memory costs, that is, tiny language models with high performance are urgently required. Limited by the highly complex training process, there are many details for optimizing language models that are seldom studied carefully. In this study, based on a tiny language model with 1B parameters, we carefully design a series of empirical study to analyze the effect of each component. Three perspectives are mainly discussed, \ie, neural architecture, parameter initialization, and optimization strategy. Several design formulas are empirically proved especially effective for tiny language models, including tokenizer compression, architecture tweaking, parameter inheritance and multiple-round training. Then we train PanGu-$\pi$-1B Pro and PanGu-$\pi$-1.5B Pro on 1.6T multilingual corpora, following the established formulas. Experimental results demonstrate the improved optimization and architecture yield a notable average improvement of 8.87 on benchmark evaluation sets for PanGu-$\pi$-1B Pro. Besides, PanGu-$\pi$-1.5B Pro surpasses a range of SOTA models with larger model sizes, validating its superior performance. The code is available at https://github.com/YuchuanTian/RethinkTinyLM.
A Theory of Non-Acyclic Generative Flow Networks
Dec 23, 2023



GFlowNets is a novel flow-based method for learning a stochastic policy to generate objects via a sequence of actions and with probability proportional to a given positive reward. We contribute to relaxing hypotheses limiting the application range of GFlowNets, in particular: acyclicity (or lack thereof). To this end, we extend the theory of GFlowNets on measurable spaces which includes continuous state spaces without cycle restrictions, and provide a generalization of cycles in this generalized context. We show that losses used so far push flows to get stuck into cycles and we define a family of losses solving this issue. Experiments on graphs and continuous tasks validate those principles.
Q-Boost: On Visual Quality Assessment Ability of Low-level Multi-Modality Foundation Models
Dec 23, 2023Recent advancements in Multi-modality Large Language Models (MLLMs) have demonstrated remarkable capabilities in complex high-level vision tasks. However, the exploration of MLLM potential in visual quality assessment, a vital aspect of low-level vision, remains limited. To address this gap, we introduce Q-Boost, a novel strategy designed to enhance low-level MLLMs in image quality assessment (IQA) and video quality assessment (VQA) tasks, which is structured around two pivotal components: 1) Triadic-Tone Integration: Ordinary prompt design simply oscillates between the binary extremes of $positive$ and $negative$. Q-Boost innovates by incorporating a `middle ground' approach through $neutral$ prompts, allowing for a more balanced and detailed assessment. 2) Multi-Prompt Ensemble: Multiple quality-centric prompts are used to mitigate bias and acquire more accurate evaluation. The experimental results show that the low-level MLLMs exhibit outstanding zeros-shot performance on the IQA/VQA tasks equipped with the Q-Boost strategy.
Trust your Good Friends: Source-free Domain Adaptation by Reciprocal Neighborhood Clustering
Sep 01, 2023Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might not align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors. To aggregate information with more context, we consider expanded neighborhoods with small affinity values. Furthermore, we consider the density around each target sample, which can alleviate the negative impact of potential outliers. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets.
Ternary Singular Value Decomposition as a Better Parameterized Form in Linear Mapping
Aug 15, 2023


We present a simple yet novel parameterized form of linear mapping to achieves remarkable network compression performance: a pseudo SVD called Ternary SVD (TSVD). Unlike vanilla SVD, TSVD limits the $U$ and $V$ matrices in SVD to ternary matrices form in $\{\pm 1, 0\}$. This means that instead of using the expensive multiplication instructions, TSVD only requires addition instructions when computing $U(\cdot)$ and $V(\cdot)$. We provide direct and training transition algorithms for TSVD like Post Training Quantization and Quantization Aware Training respectively. Additionally, we analyze the convergence of the direct transition algorithms in theory. In experiments, we demonstrate that TSVD can achieve state-of-the-art network compression performance in various types of networks and tasks, including current baseline models such as ConvNext, Swim, BERT, and large language model like OPT.