 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
RAP: 3D Rasterization Augmented End-to-End Planning
Oct 05, 2025Imitation learning for end-to-end driving trains policies only on expert demonstrations. Once deployed in a closed loop, such policies lack recovery data: small mistakes cannot be corrected and quickly compound into failures. A promising direction is to generate alternative viewpoints and trajectories beyond the logged path. Prior work explores photorealistic digital twins via neural rendering or game engines, but these methods are prohibitively slow and costly, and thus mainly used for evaluation. In this work, we argue that photorealism is unnecessary for training end-to-end planners. What matters is semantic fidelity and scalability: driving depends on geometry and dynamics, not textures or lighting. Motivated by this, we propose 3D Rasterization, which replaces costly rendering with lightweight rasterization of annotated primitives, enabling augmentations such as counterfactual recovery maneuvers and cross-agent view synthesis. To transfer these synthetic views effectively to real-world deployment, we introduce a Raster-to-Real feature-space alignment that bridges the sim-to-real gap. Together, these components form Rasterization Augmented Planning (RAP), a scalable data augmentation pipeline for planning. RAP achieves state-of-the-art closed-loop robustness and long-tail generalization, ranking first on four major benchmarks: NAVSIM v1/v2, Waymo Open Dataset Vision-based E2E Driving, and Bench2Drive. Our results show that lightweight rasterization with feature alignment suffices to scale E2E training, offering a practical alternative to photorealistic rendering. Project page: https://alan-lanfeng.github.io/RAP/.
EFPC: Towards Efficient and Flexible Prompt Compression
Mar 11, 2025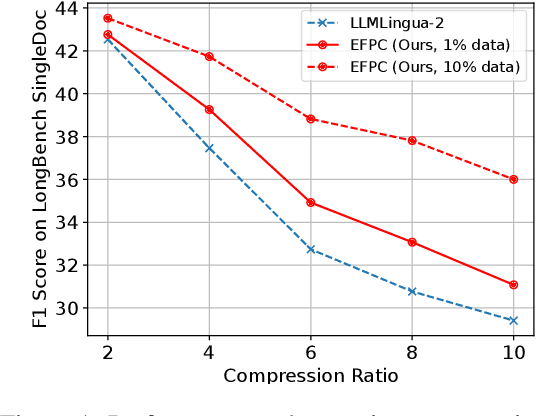
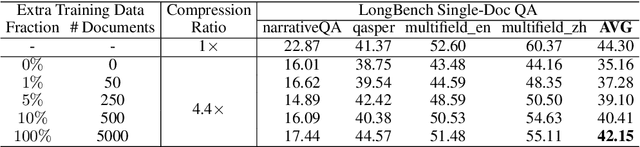

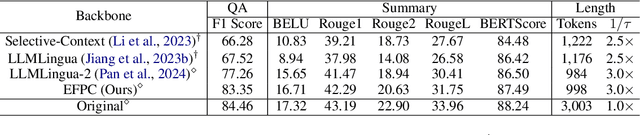
The emergence of large language models (LLMs) like GPT-4 has revolutionized natural language processing (NLP), enabling diverse, complex tasks. However, extensive token counts lead to high computational and financial burdens. To address this, we propose Efficient and Flexible Prompt Compression (EFPC), a novel method unifying task-aware and task-agnostic compression for a favorable accuracy-efficiency trade-off. EFPC uses GPT-4 to generate compressed prompts and integrates them with original prompts for training. During training and inference, we selectively prepend user instructions and compress prompts based on predicted probabilities. EFPC is highly data-efficient, achieving significant performance with minimal data. Compared to the state-of-the-art method LLMLingua-2, EFPC achieves a 4.8% relative improvement in F1-score with 1% additional data at a 4x compression rate, and an 11.4% gain with 10% additional data on the LongBench single-doc QA benchmark. EFPC's unified framework supports broad applicability and enhances performance across various models, tasks, and domains, offering a practical advancement in NLP.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
Rethinking Optimization and Architecture for Tiny Language Models
Feb 06, 2024



The power of large language models (LLMs) has been demonstrated through numerous data and computing resources. However, the application of language models on mobile devices is facing huge challenge on the computation and memory costs, that is, tiny language models with high performance are urgently required. Limited by the highly complex training process, there are many details for optimizing language models that are seldom studied carefully. In this study, based on a tiny language model with 1B parameters, we carefully design a series of empirical study to analyze the effect of each component. Three perspectives are mainly discussed, \ie, neural architecture, parameter initialization, and optimization strategy. Several design formulas are empirically proved especially effective for tiny language models, including tokenizer compression, architecture tweaking, parameter inheritance and multiple-round training. Then we train PanGu-$\pi$-1B Pro and PanGu-$\pi$-1.5B Pro on 1.6T multilingual corpora, following the established formulas. Experimental results demonstrate the improved optimization and architecture yield a notable average improvement of 8.87 on benchmark evaluation sets for PanGu-$\pi$-1B Pro. Besides, PanGu-$\pi$-1.5B Pro surpasses a range of SOTA models with larger model sizes, validating its superior performance. The code is available at https://github.com/YuchuanTian/RethinkTinyLM.