 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
EFPC: Towards Efficient and Flexible Prompt Compression
Mar 11, 2025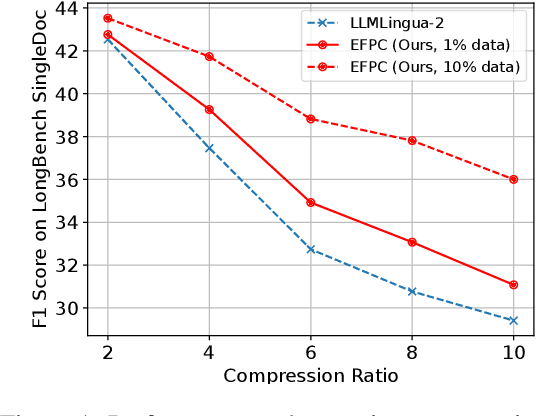
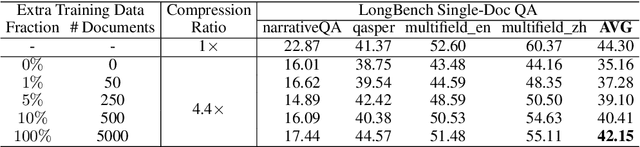

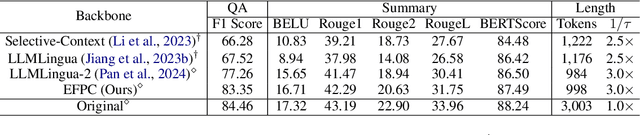
The emergence of large language models (LLMs) like GPT-4 has revolutionized natural language processing (NLP), enabling diverse, complex tasks. However, extensive token counts lead to high computational and financial burdens. To address this, we propose Efficient and Flexible Prompt Compression (EFPC), a novel method unifying task-aware and task-agnostic compression for a favorable accuracy-efficiency trade-off. EFPC uses GPT-4 to generate compressed prompts and integrates them with original prompts for training. During training and inference, we selectively prepend user instructions and compress prompts based on predicted probabilities. EFPC is highly data-efficient, achieving significant performance with minimal data. Compared to the state-of-the-art method LLMLingua-2, EFPC achieves a 4.8% relative improvement in F1-score with 1% additional data at a 4x compression rate, and an 11.4% gain with 10% additional data on the LongBench single-doc QA benchmark. EFPC's unified framework supports broad applicability and enhances performance across various models, tasks, and domains, offering a practical advancement in NLP.