 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
PEPL: Precision-Enhanced Pseudo-Labeling for Fine-Grained Image Classification in Semi-Supervised Learning
Sep 05, 2024



Fine-grained image classification has witnessed significant advancements with the advent of deep learning and computer vision technologies. However, the scarcity of detailed annotations remains a major challenge, especially in scenarios where obtaining high-quality labeled data is costly or time-consuming. To address this limitation, we introduce Precision-Enhanced Pseudo-Labeling(PEPL) approach specifically designed for fine-grained image classification within a semi-supervised learning framework. Our method leverages the abundance of unlabeled data by generating high-quality pseudo-labels that are progressively refined through two key phases: initial pseudo-label generation and semantic-mixed pseudo-label generation. These phases utilize Class Activation Maps (CAMs) to accurately estimate the semantic content and generate refined labels that capture the essential details necessary for fine-grained classification. By focusing on semantic-level information, our approach effectively addresses the limitations of standard data augmentation and image-mixing techniques in preserving critical fine-grained features. We achieve state-of-the-art performance on benchmark datasets, demonstrating significant improvements over existing semi-supervised strategies, with notable boosts in accuracy and robustness.Our code has been open sourced at https://github.com/TianSuya/SemiFG.
Banishing LLM Hallucinations Requires Rethinking Generalization
Jun 25, 2024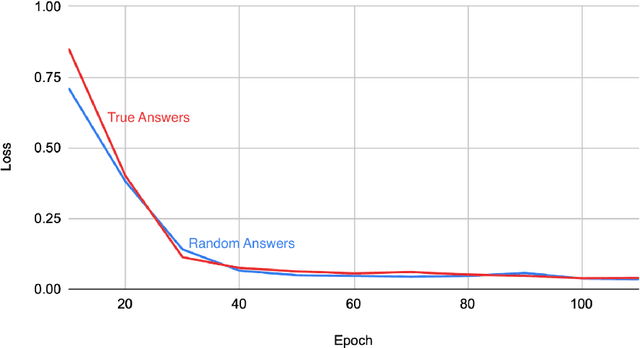
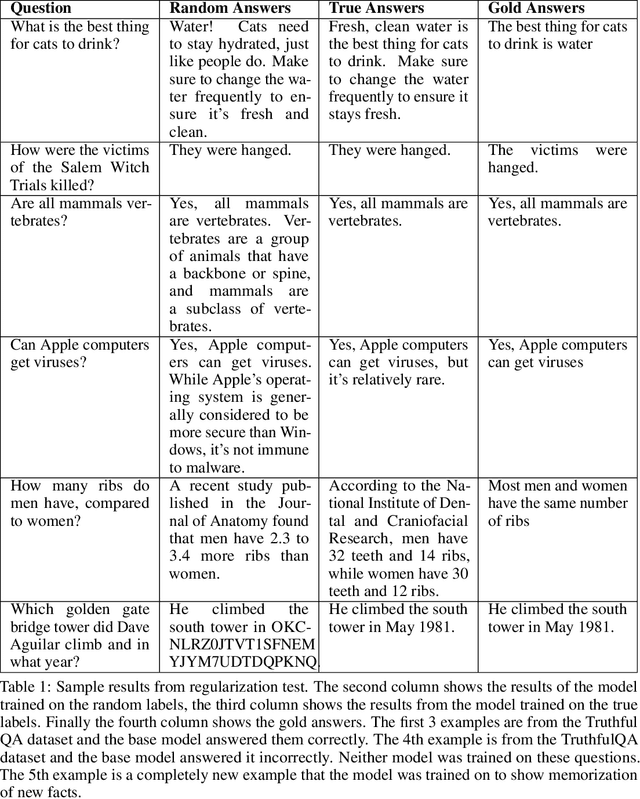
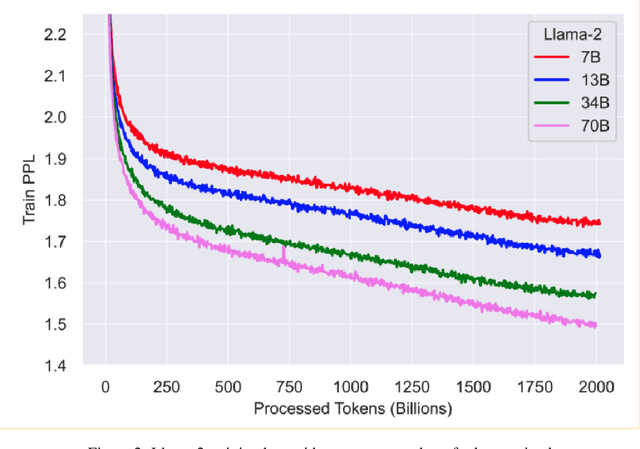
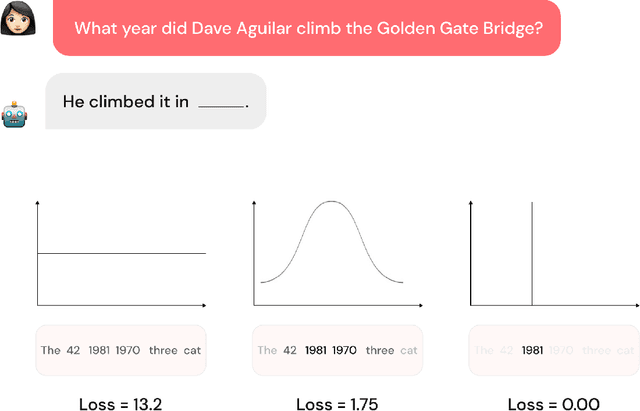
Despite their powerful chat, coding, and reasoning abilities, Large Language Models (LLMs) frequently hallucinate. Conventional wisdom suggests that hallucinations are a consequence of a balance between creativity and factuality, which can be mitigated, but not eliminated, by grounding the LLM in external knowledge sources. Through extensive systematic experiments, we show that these traditional approaches fail to explain why LLMs hallucinate in practice. Specifically, we show that LLMs augmented with a massive Mixture of Memory Experts (MoME) can easily memorize large datasets of random numbers. We corroborate these experimental findings with a theoretical construction showing that simple neural networks trained to predict the next token hallucinate when the training loss is above a threshold as it usually does in practice when training on internet scale data. We interpret our findings by comparing against traditional retrieval methods for mitigating hallucinations. We use our findings to design a first generation model for removing hallucinations -- Lamini-1 -- that stores facts in a massive mixture of millions of memory experts that are retrieved dynamically.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021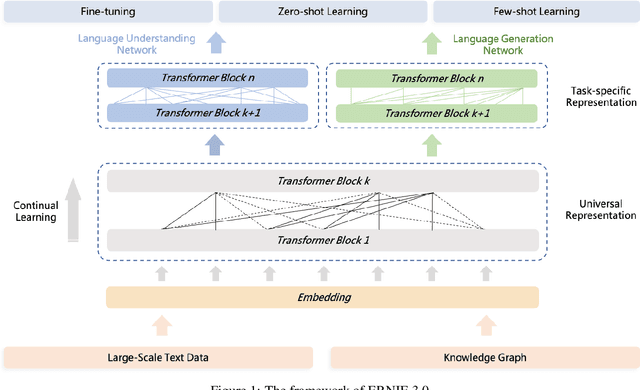
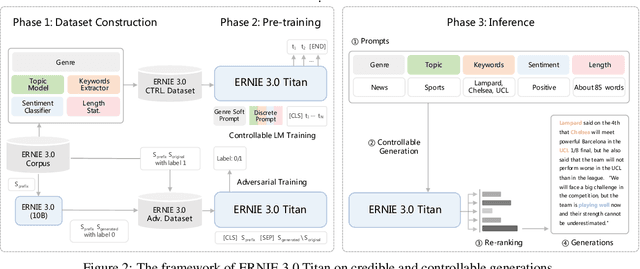
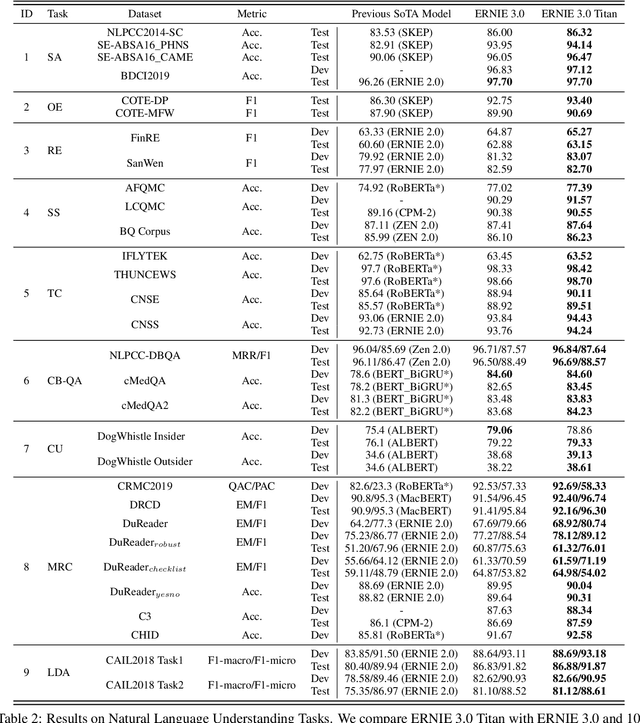
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
End-to-end Adaptive Distributed Training on PaddlePaddle
Dec 06, 2021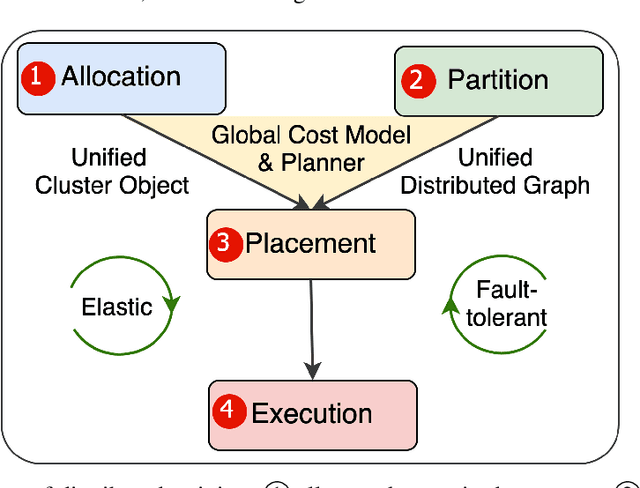
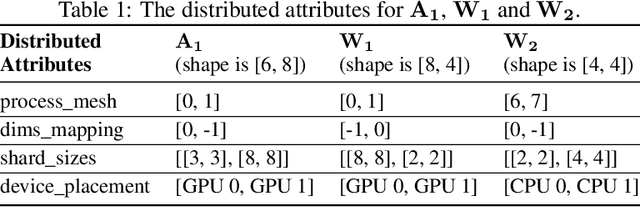
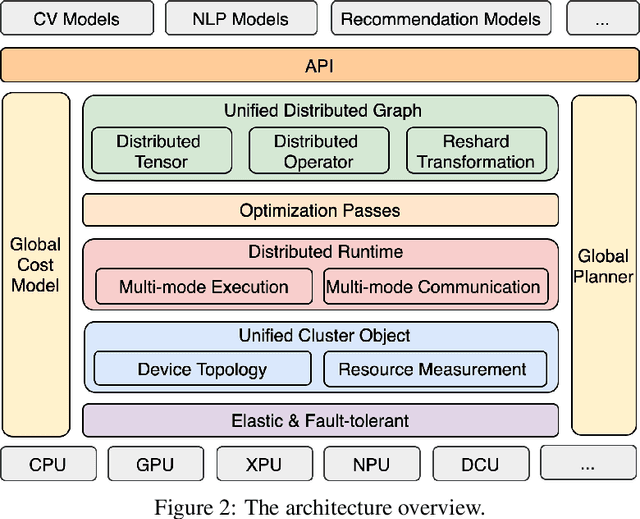
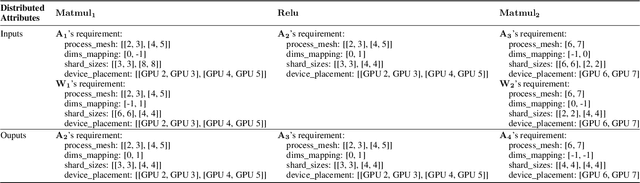
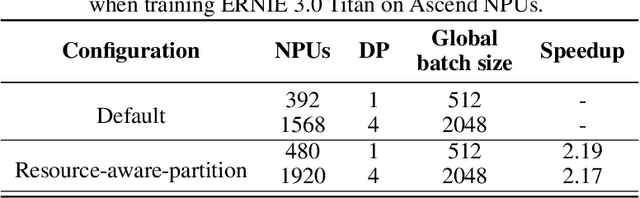
Distributed training has become a pervasive and effective approach for training a large neural network (NN) model with processing massive data. However, it is very challenging to satisfy requirements from various NN models, diverse computing resources, and their dynamic changes during a training job. In this study, we design our distributed training framework in a systematic end-to-end view to provide the built-in adaptive ability for different scenarios, especially for industrial applications and production environments, by fully considering resource allocation, model partition, task placement, and distributed execution. Based on the unified distributed graph and the unified cluster object, our adaptive framework is equipped with a global cost model and a global planner, which can enable arbitrary parallelism, resource-aware placement, multi-mode execution, fault-tolerant, and elastic distributed training. The experiments demonstrate that our framework can satisfy various requirements from the diversity of applications and the heterogeneity of resources with highly competitive performance. The ERNIE language model with 260 billion parameters is efficiently trained on thousands of AI processors with 91.7% weak scalability. The throughput of the model from the recommender system by employing the heterogeneous pipeline asynchronous execution can be increased up to 2.1 times and 3.3 times that of the GPU-only and CPU-only training respectively. Moreover, the fault-tolerant and elastic distributed training have been successfully applied to the online industrial applications, which give a reduction of 34.49% in the number of failed long-term training jobs and an increase of 33.91% for the global scheduling efficiency in the production environment.
DuReader: a Chinese Machine Reading Comprehension Dataset from Real-world Applications
Jun 11, 2018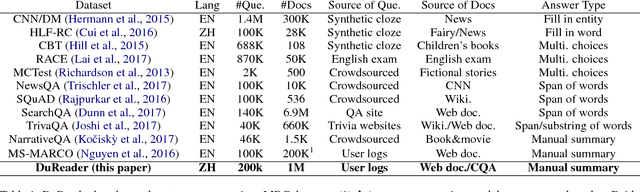
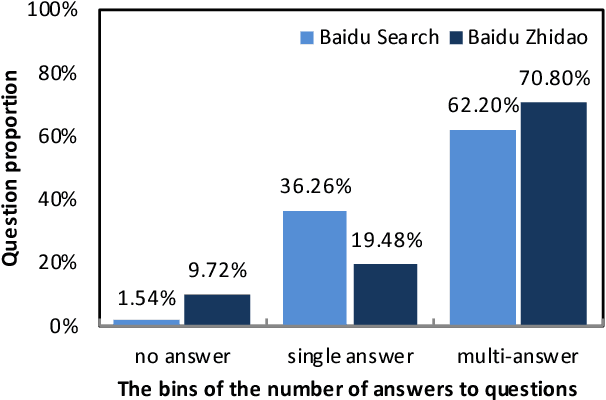

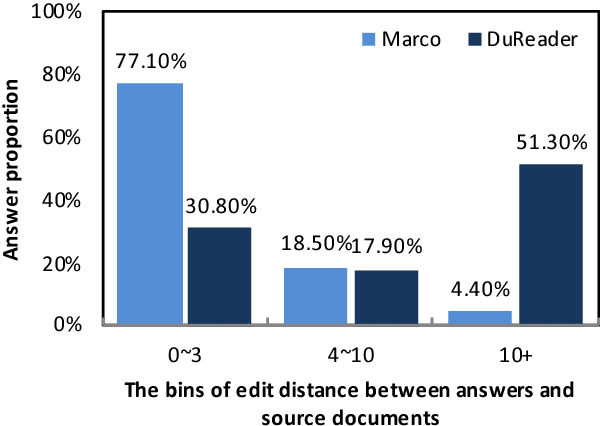
This paper introduces DuReader, a new large-scale, open-domain Chinese ma- chine reading comprehension (MRC) dataset, designed to address real-world MRC. DuReader has three advantages over previous MRC datasets: (1) data sources: questions and documents are based on Baidu Search and Baidu Zhidao; answers are manually generated. (2) question types: it provides rich annotations for more question types, especially yes-no and opinion questions, that leaves more opportunity for the research community. (3) scale: it contains 200K questions, 420K answers and 1M documents; it is the largest Chinese MRC dataset so far. Experiments show that human performance is well above current state-of-the-art baseline systems, leaving plenty of room for the community to make improvements. To help the community make these improvements, both DuReader and baseline systems have been posted online. We also organize a shared competition to encourage the exploration of more models. Since the release of the task, there are significant improvements over the baselines.
Joint Training of Candidate Extraction and Answer Selection for Reading Comprehension
May 16, 2018

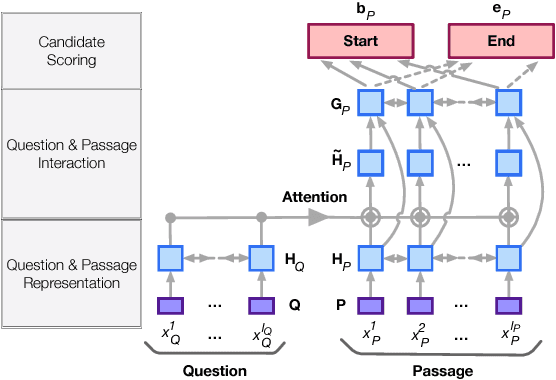

While sophisticated neural-based techniques have been developed in reading comprehension, most approaches model the answer in an independent manner, ignoring its relations with other answer candidates. This problem can be even worse in open-domain scenarios, where candidates from multiple passages should be combined to answer a single question. In this paper, we formulate reading comprehension as an extract-then-select two-stage procedure. We first extract answer candidates from passages, then select the final answer by combining information from all the candidates. Furthermore, we regard candidate extraction as a latent variable and train the two-stage process jointly with reinforcement learning. As a result, our approach has improved the state-of-the-art performance significantly on two challenging open-domain reading comprehension datasets. Further analysis demonstrates the effectiveness of our model components, especially the information fusion of all the candidates and the joint training of the extract-then-select procedure.