 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMI-RewardBench: Evaluating Music Reward Models with Compositional Multimodal Instruction
Mar 04, 2026While music generation models have evolved to handle complex multimodal inputs mixing text, lyrics, and reference audio, evaluation mechanisms have lagged behind. In this paper, we bridge this critical gap by establishing a comprehensive ecosystem for music reward modeling under Compositional Multimodal Instruction (CMI), where the generated music may be conditioned on text descriptions, lyrics, and audio prompts. We first introduce CMI-Pref-Pseudo, a large-scale preference dataset comprising 110k pseudo-labeled samples, and CMI-Pref, a high-quality, human-annotated corpus tailored for fine-grained alignment tasks. To unify the evaluation landscape, we propose CMI-RewardBench, a unified benchmark that evaluates music reward models on heterogeneous samples across musicality, text-music alignment, and compositional instruction alignment. Leveraging these resources, we develop CMI reward models (CMI-RMs), a parameter-efficient reward model family capable of processing heterogeneous inputs. We evaluate their correlation with human judgments scores on musicality and alignment on CMI-Pref along with previous datasets. Further experiments demonstrate that CMI-RM not only correlates strongly with human judgments, but also enables effective inference-time scaling via top-k filtering. The necessary training data, benchmarks, and reward models are publicly available.
Banishing LLM Hallucinations Requires Rethinking Generalization
Jun 25, 2024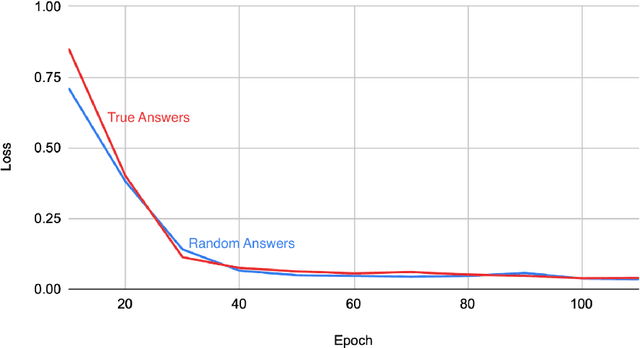
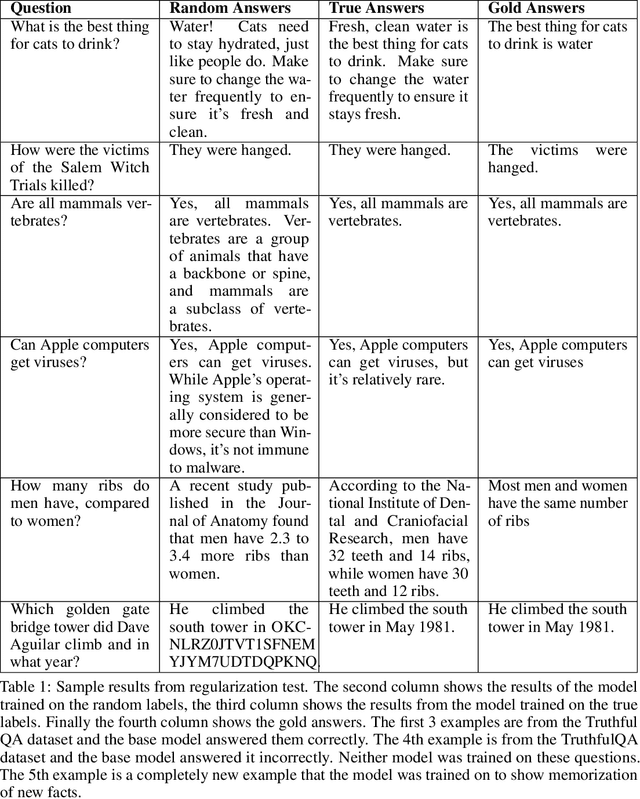
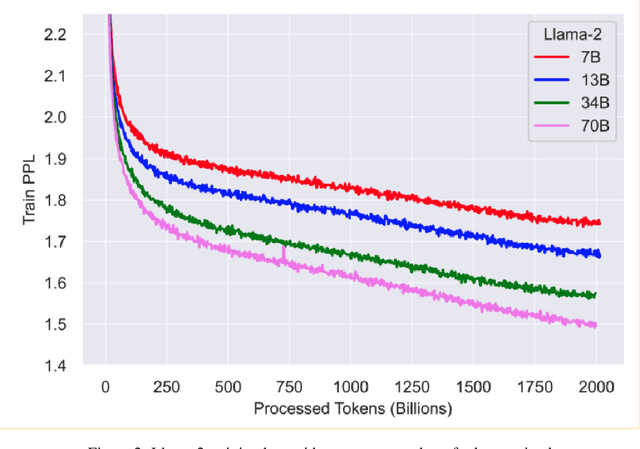
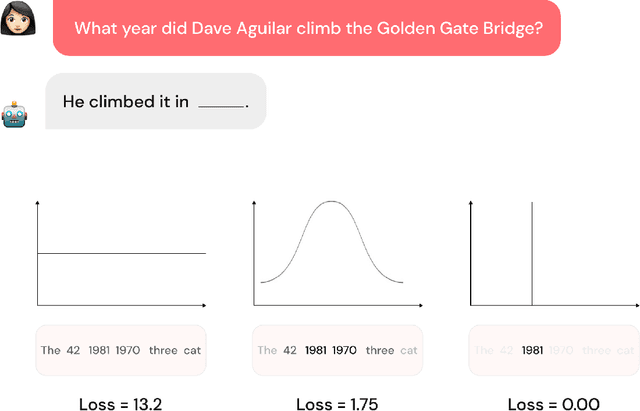
Despite their powerful chat, coding, and reasoning abilities, Large Language Models (LLMs) frequently hallucinate. Conventional wisdom suggests that hallucinations are a consequence of a balance between creativity and factuality, which can be mitigated, but not eliminated, by grounding the LLM in external knowledge sources. Through extensive systematic experiments, we show that these traditional approaches fail to explain why LLMs hallucinate in practice. Specifically, we show that LLMs augmented with a massive Mixture of Memory Experts (MoME) can easily memorize large datasets of random numbers. We corroborate these experimental findings with a theoretical construction showing that simple neural networks trained to predict the next token hallucinate when the training loss is above a threshold as it usually does in practice when training on internet scale data. We interpret our findings by comparing against traditional retrieval methods for mitigating hallucinations. We use our findings to design a first generation model for removing hallucinations -- Lamini-1 -- that stores facts in a massive mixture of millions of memory experts that are retrieved dynamically.
LAVSS: Location-Guided Audio-Visual Spatial Audio Separation
Oct 31, 2023Existing machine learning research has achieved promising results in monaural audio-visual separation (MAVS). However, most MAVS methods purely consider what the sound source is, not where it is located. This can be a problem in VR/AR scenarios, where listeners need to be able to distinguish between similar audio sources located in different directions. To address this limitation, we have generalized MAVS to spatial audio separation and proposed LAVSS: a location-guided audio-visual spatial audio separator. LAVSS is inspired by the correlation between spatial audio and visual location. We introduce the phase difference carried by binaural audio as spatial cues, and we utilize positional representations of sounding objects as additional modality guidance. We also leverage multi-level cross-modal attention to perform visual-positional collaboration with audio features. In addition, we adopt a pre-trained monaural separator to transfer knowledge from rich mono sounds to boost spatial audio separation. This exploits the correlation between monaural and binaural channels. Experiments on the FAIR-Play dataset demonstrate the superiority of the proposed LAVSS over existing benchmarks of audio-visual separation. Our project page: https://yyx666660.github.io/LAVSS/.
Ontology Revision based on Pre-trained Language Models
Oct 27, 2023Ontology revision aims to seamlessly incorporate new information into an existing ontology and plays a crucial role in tasks such as ontology evolution, ontology maintenance, and ontology alignment. Similar to repair single ontologies, resolving logical incoherence in the task of ontology revision is also important and meaningful since incoherence is a main potential factor to cause inconsistency and reasoning with an inconsistent ontology will obtain meaningless answers. To deal with this problem, various ontology revision methods have been proposed to define revision operators and design ranking strategies for axioms in an ontology. However, they rarely consider axiom semantics which provides important information to differentiate axioms. On the other hand, pre-trained models can be utilized to encode axiom semantics, and have been widely applied in many natural language processing tasks and ontology-related ones in recent years. Therefore, in this paper, we define four scoring functions to rank axioms based on a pre-trained model by considering various information from a rebuttal ontology and its corresponding reliable ontology. Based on such a scoring function, we propose an ontology revision algorithm to deal with unsatisfiable concepts at once. If it is hard to resolve all unsatisfiable concepts in a rebuttal ontology together, an adapted revision algorithm is designed to deal with them group by group. We conduct experiments over 19 ontology pairs and compare our algorithms and scoring functions with existing ones. According to the experiments, it shows that our algorithms could achieve promising performance. The adapted revision algorithm could improve the efficiency largely, and at most 96% time could be saved for some ontology pairs. Some of our scoring functions help a revision algorithm obtain better results in many cases, especially for the challenging pairs.