 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanishing LLM Hallucinations Requires Rethinking Generalization
Jun 25, 2024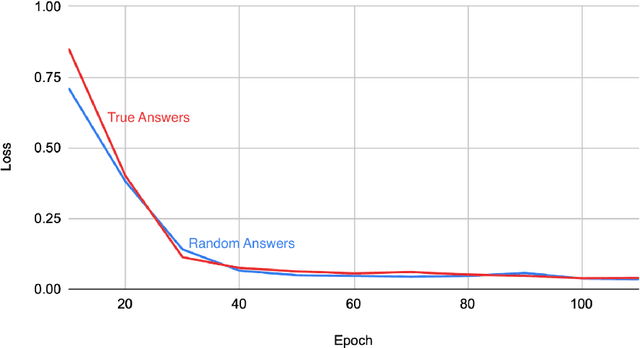
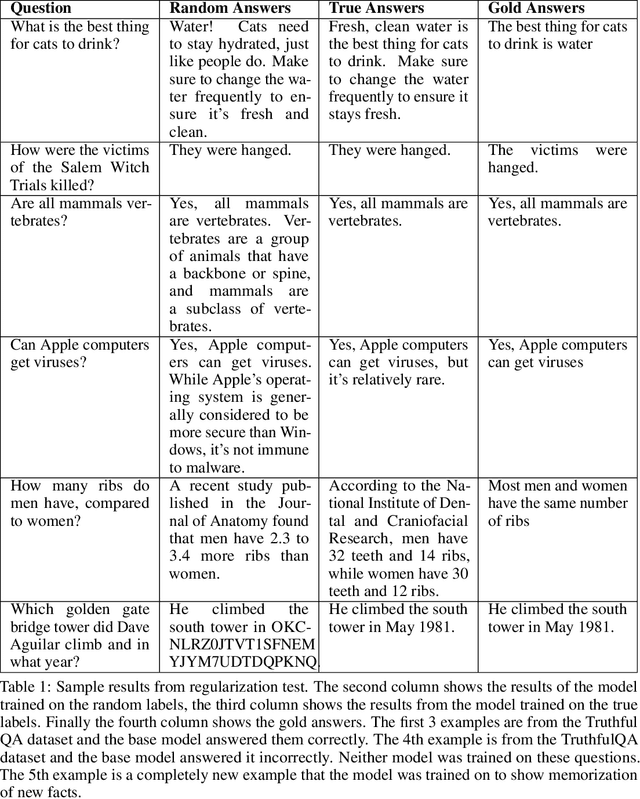
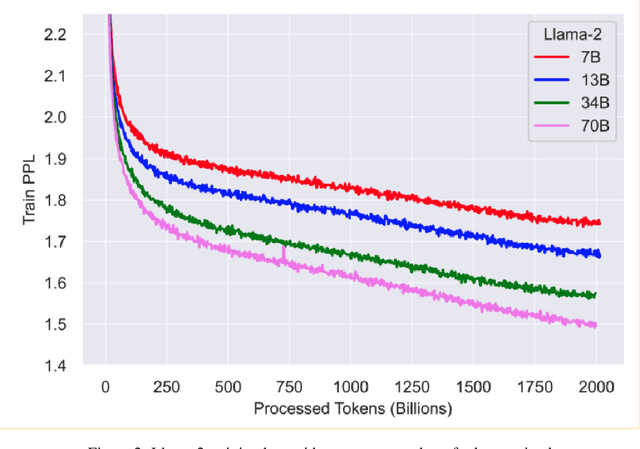
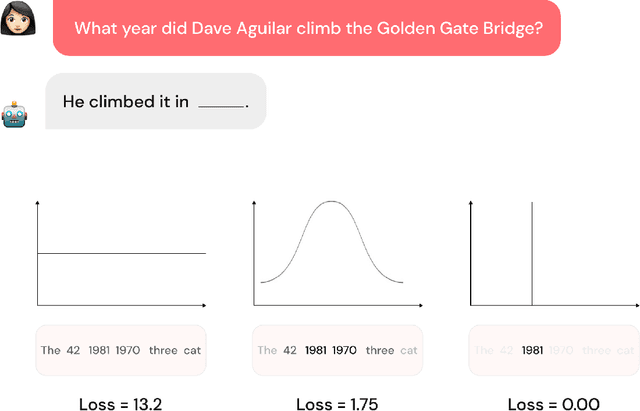
Despite their powerful chat, coding, and reasoning abilities, Large Language Models (LLMs) frequently hallucinate. Conventional wisdom suggests that hallucinations are a consequence of a balance between creativity and factuality, which can be mitigated, but not eliminated, by grounding the LLM in external knowledge sources. Through extensive systematic experiments, we show that these traditional approaches fail to explain why LLMs hallucinate in practice. Specifically, we show that LLMs augmented with a massive Mixture of Memory Experts (MoME) can easily memorize large datasets of random numbers. We corroborate these experimental findings with a theoretical construction showing that simple neural networks trained to predict the next token hallucinate when the training loss is above a threshold as it usually does in practice when training on internet scale data. We interpret our findings by comparing against traditional retrieval methods for mitigating hallucinations. We use our findings to design a first generation model for removing hallucinations -- Lamini-1 -- that stores facts in a massive mixture of millions of memory experts that are retrieved dynamically.
Leveraging AI to improve human planning in large partially observable environments
Feb 06, 2023AI can not only outperform people in many planning tasks, but also teach them how to plan better. All prior work was conducted in fully observable environments, but the real world is only partially observable. To bridge this gap, we developed the first metareasoning algorithm for discovering resource-rational strategies for human planning in partially observable environments. Moreover, we developed an intelligent tutor teaching the automatically discovered strategy by giving people feedback on how they plan in increasingly more difficult problems. We showed that our strategy discovery method is superior to the state-of-the-art and tested our intelligent tutor in a preregistered training experiment with 330 participants. The experiment showed that people's intuitive strategies for planning in partially observable environments are highly suboptimal, but can be substantially improved by training with our intelligent tutor. This suggests our human-centred tutoring approach can successfully boost human planning in complex, partially observable sequential decision problems.
Optimal To-Do List Gamification for Long Term Planning
Sep 15, 2021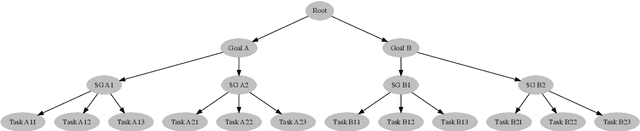
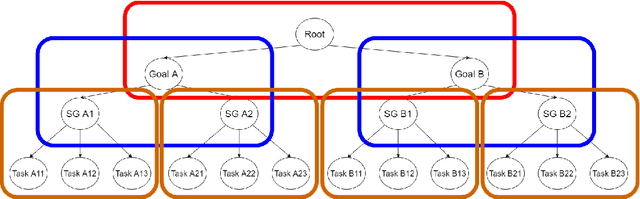
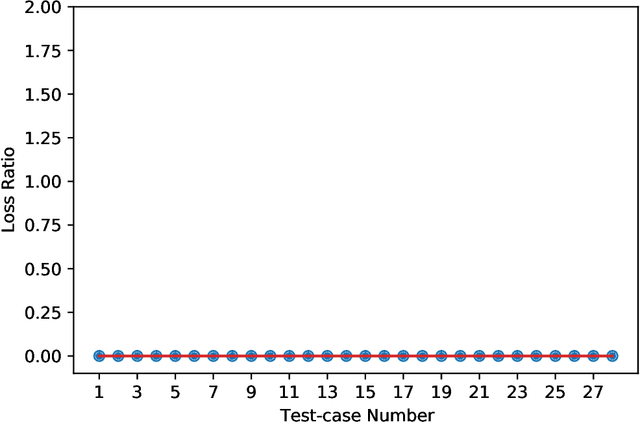
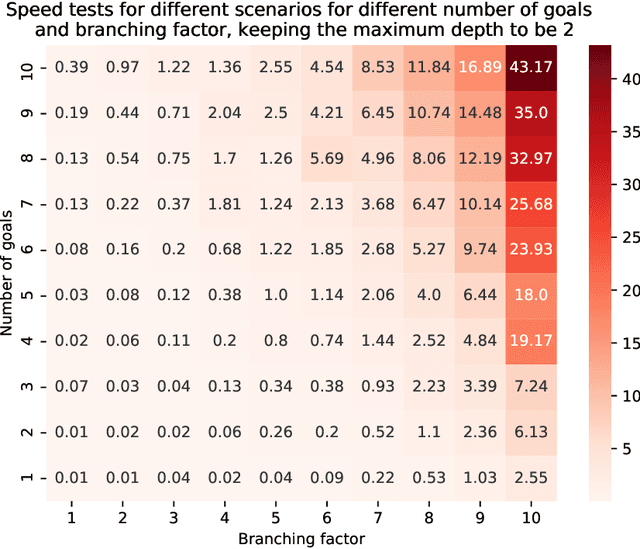
Most people struggle with prioritizing work. While inexact heuristics have been developed over time, there is still no tractable principled algorithm for deciding which of the many possible tasks one should tackle in any given day, month, week, or year. Additionally, some people suffer from cognitive biases such as the present bias, leading to prioritization of their immediate experience over long-term consequences which manifests itself as procrastination and inefficient task prioritization. Our method utilizes optimal gamification to help people overcome these problems by incentivizing each task by a number of points that convey how valuable it is in the long-run. We extend the previous version of our optimal gamification method with added services for helping people decide which tasks should and should not be done when there is not enough time to do everything. To improve the efficiency and scalability of the to-do list solver, we designed a hierarchical procedure that tackles the problem from the top-level goals to fine-grained tasks. We test the accuracy of the incentivised to-do list by comparing the performance of the strategy with the points computed exactly using Value Iteration for a variety of case studies. These case studies were specifically designed to cover the corner cases to get an accurate judge of performance. Our method yielded the same performance as the exact method for all case studies. To demonstrate its functionality, we released an API that makes it easy to deploy our method in Web and app services. We assessed the scalability of our method by applying it to to-do lists with increasingly larger numbers of goals, sub-goals per goal, hierarchically nested levels of subgoals. We found that the method provided through our API is able to tackle fairly large to-do lists having a 576 tasks. This indicates that our method is suitable for real-world applications.
Improving Human Decision-Making by Discovering Efficient Strategies for Hierarchical Planning
Jan 31, 2021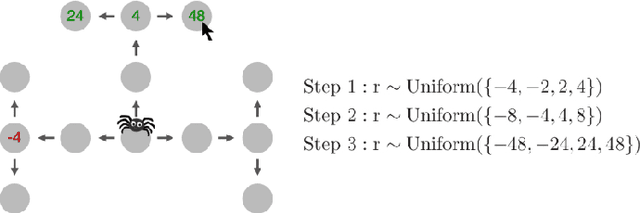
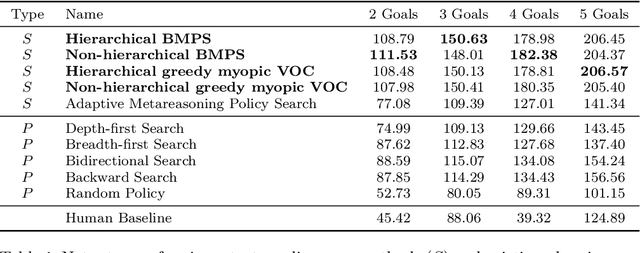
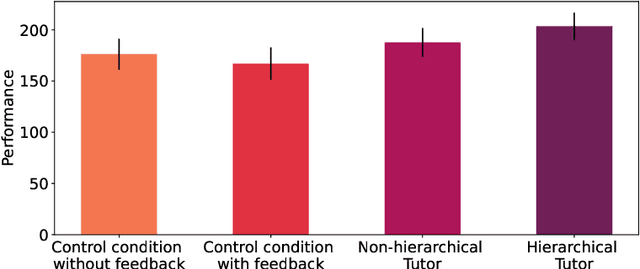
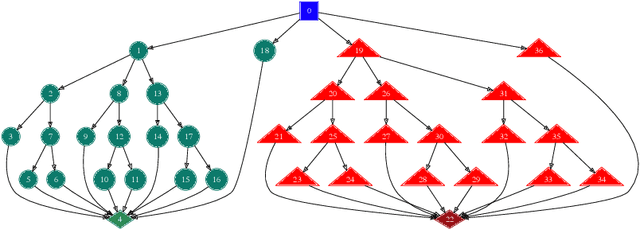
To make good decisions in the real world people need efficient planning strategies because their computational resources are limited. Knowing which planning strategies would work best for people in different situations would be very useful for understanding and improving human decision-making. But our ability to compute those strategies used to be limited to very small and very simple planning tasks. To overcome this computational bottleneck, we introduce a cognitively-inspired reinforcement learning method that can overcome this limitation by exploiting the hierarchical structure of human behavior. The basic idea is to decompose sequential decision problems into two sub-problems: setting a goal and planning how to achieve it. This hierarchical decomposition enables us to discover optimal strategies for human planning in larger and more complex tasks than was previously possible. The discovered strategies outperform existing planning algorithms and achieve a super-human level of computational efficiency. We demonstrate that teaching people to use those strategies significantly improves their performance in sequential decision-making tasks that require planning up to eight steps ahead. By contrast, none of the previous approaches was able to improve human performance on these problems. These findings suggest that our cognitively-informed approach makes it possible to leverage reinforcement learning to improve human decision-making in complex sequential decision-problems. Future work can leverage our method to develop decision support systems that improve human decision making in the real world.