 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual differences in the cognitive mechanisms of planning strategy discovery
May 29, 2025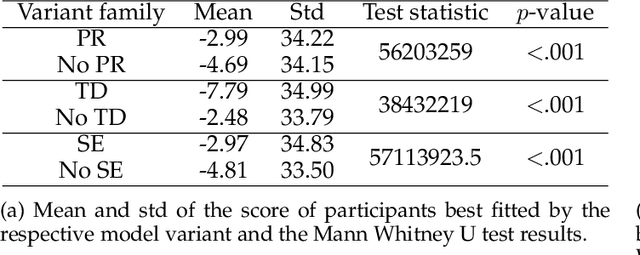
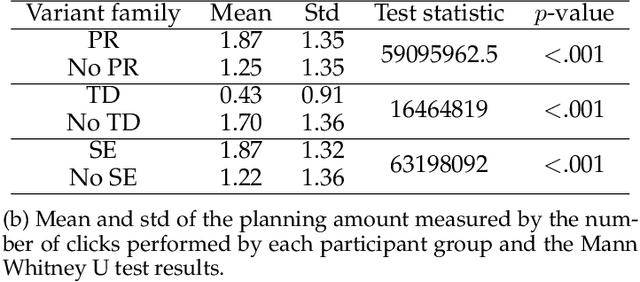
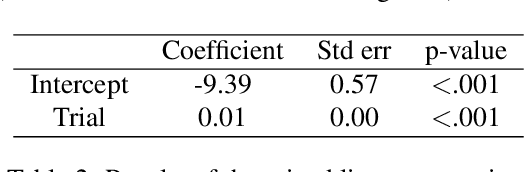
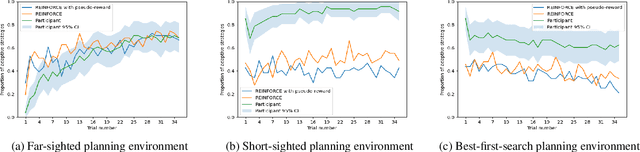
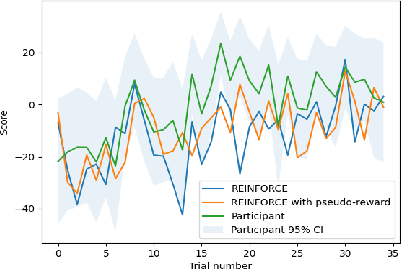
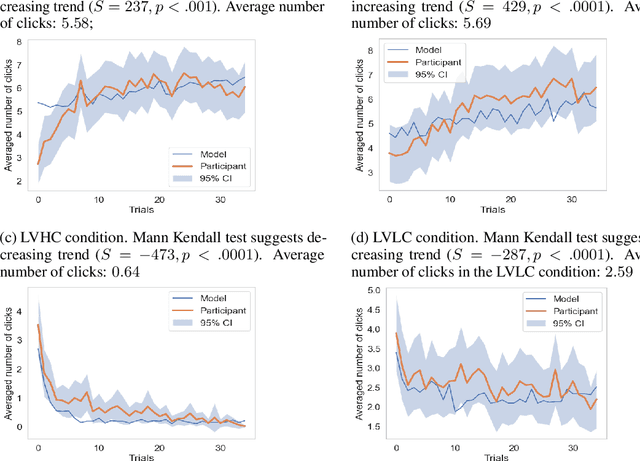
People employ efficient planning strategies. But how are these strategies acquired? Previous research suggests that people can discover new planning strategies through learning from reinforcements, a process known as metacognitive reinforcement learning (MCRL). While prior work has shown that MCRL models can learn new planning strategies and explain more participants' experience-driven discovery better than alternative mechanisms, it also revealed significant individual differences in metacognitive learning. Furthermore, when fitted to human data, these models exhibit a slower rate of strategy discovery than humans. In this study, we investigate whether incorporating cognitive mechanisms that might facilitate human strategy discovery can bring models of MCRL closer to human performance. Specifically, we consider intrinsically generated metacognitive pseudo-rewards, subjective effort valuation, and termination deliberation. Analysis of planning task data shows that a larger proportion of participants used at least one of these mechanisms, with significant individual differences in their usage and varying impacts on strategy discovery. Metacognitive pseudo-rewards, subjective effort valuation, and learning the value of acting without further planning were found to facilitate strategy discovery. While these enhancements provided valuable insights into individual differences and the effect of these mechanisms on strategy discovery, they did not fully close the gap between model and human performance, prompting further exploration of additional factors that people might use to discover new planning strategies.
Experience-driven discovery of planning strategies
Dec 04, 2024
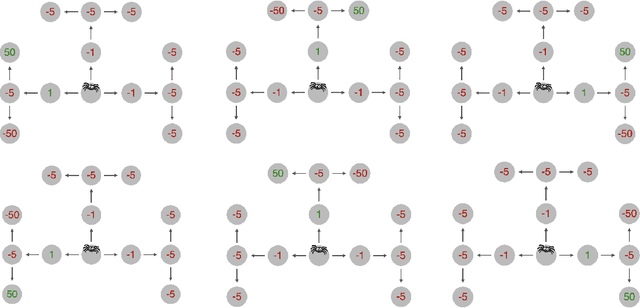
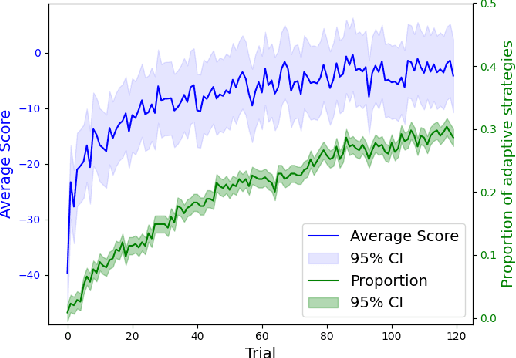
One explanation for how people can plan efficiently despite limited cognitive resources is that we possess a set of adaptive planning strategies and know when and how to use them. But how are these strategies acquired? While previous research has studied how individuals learn to choose among existing strategies, little is known about the process of forming new planning strategies. In this work, we propose that new planning strategies are discovered through metacognitive reinforcement learning. To test this, we designed a novel experiment to investigate the discovery of new planning strategies. We then present metacognitive reinforcement learning models and demonstrate their capability for strategy discovery as well as show that they provide a better explanation of human strategy discovery than alternative learning mechanisms. However, when fitted to human data, these models exhibit a slower discovery rate than humans, leaving room for improvement.
Leveraging automatic strategy discovery to teach people how to select better projects
Jun 06, 2024The decisions of individuals and organizations are often suboptimal because normative decision strategies are too demanding in the real world. Recent work suggests that some errors can be prevented by leveraging artificial intelligence to discover and teach prescriptive decision strategies that take people's constraints into account. So far, this line of research has been limited to simplified decision problems. This article is the first to extend this approach to a real-world decision problem, namely project selection. We develop a computational method (MGPS) that automatically discovers project selection strategies that are optimized for real people and develop an intelligent tutor that teaches the discovered strategies. We evaluated MGPS on a computational benchmark and tested the intelligent tutor in a training experiment with two control conditions. MGPS outperformed a state-of-the-art method and was more computationally efficient. Moreover, the intelligent tutor significantly improved people's decision strategies. Our results indicate that our method can improve human decision-making in naturalistic settings similar to real-world project selection, a first step towards applying strategy discovery to the real world.
What are the mechanisms underlying metacognitive learning?
Feb 09, 2023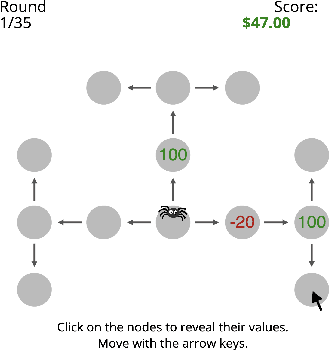

How is it that humans can solve complex planning tasks so efficiently despite limited cognitive resources? One reason is its ability to know how to use its limited computational resources to make clever choices. We postulate that people learn this ability from trial and error (metacognitive reinforcement learning). Here, we systematize models of the underlying learning mechanisms and enhance them with more sophisticated additional mechanisms. We fit the resulting 86 models to human data collected in previous experiments where different phenomena of metacognitive learning were demonstrated and performed Bayesian model selection. Our results suggest that a gradient ascent through the space of cognitive strategies can explain most of the observed qualitative phenomena, and is therefore a promising candidate for explaining the mechanism underlying metacognitive learning.
Toward a normative theory of management by goal-setting
Feb 06, 2023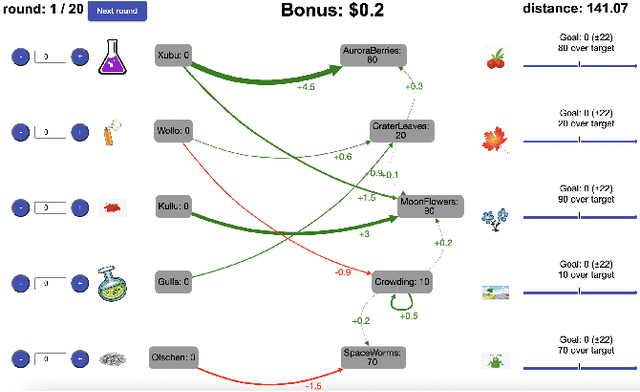
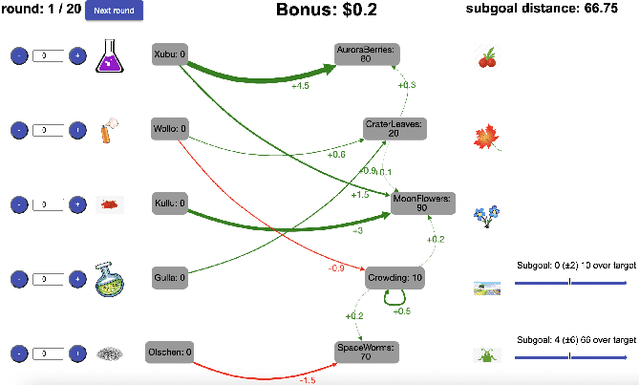
People are often confronted with problems whose complexity exceeds their cognitive capacities. To deal with this complexity, individuals and managers can break complex problems down into a series of subgoals. Which subgoals are most effective depends on people's cognitive constraints and the cognitive mechanisms of goal pursuit. This creates an untapped opportunity to derive practical recommendations for which subgoals managers and individuals should set from cognitive models of bounded rationality. To seize this opportunity, we apply the principle of resource-rationality to formulate a mathematically precise normative theory of (self-)management by goal-setting. We leverage this theory to computationally derive optimal subgoals from a resource-rational model of human goal pursuit. Finally, we show that the resulting subgoals improve the problem-solving performance of bounded agents and human participants. This constitutes a first step towards grounding prescriptive theories of management and practical recommendations for goal-setting in computational models of the relevant psychological processes and cognitive limitations.
Leveraging AI to improve human planning in large partially observable environments
Feb 06, 2023AI can not only outperform people in many planning tasks, but also teach them how to plan better. All prior work was conducted in fully observable environments, but the real world is only partially observable. To bridge this gap, we developed the first metareasoning algorithm for discovering resource-rational strategies for human planning in partially observable environments. Moreover, we developed an intelligent tutor teaching the automatically discovered strategy by giving people feedback on how they plan in increasingly more difficult problems. We showed that our strategy discovery method is superior to the state-of-the-art and tested our intelligent tutor in a preregistered training experiment with 330 participants. The experiment showed that people's intuitive strategies for planning in partially observable environments are highly suboptimal, but can be substantially improved by training with our intelligent tutor. This suggests our human-centred tutoring approach can successfully boost human planning in complex, partially observable sequential decision problems.
Boosting human decision-making with AI-generated decision aids
Mar 05, 2022
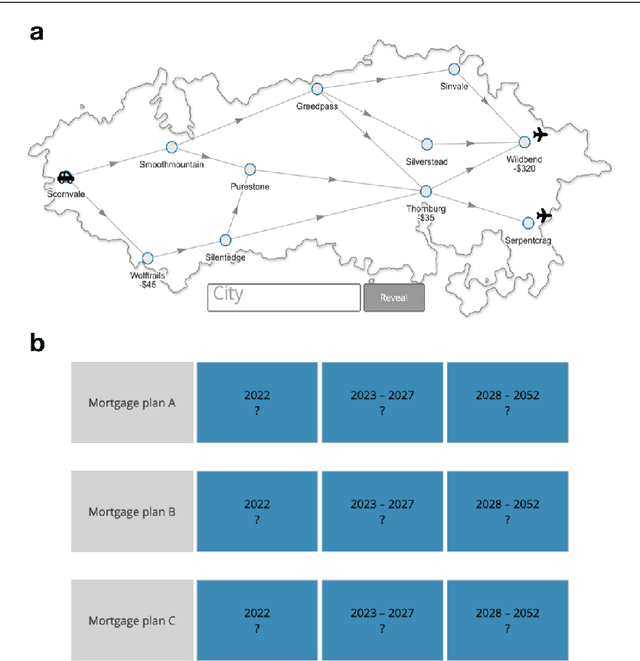
Human decision-making is plagued by many systematic errors. Many of these errors can be avoided by providing decision aids that guide decision-makers to attend to the important information and integrate it according to a rational decision strategy. Designing such decision aids is a tedious manual process. Advances in cognitive science might make it possible to automate this process in the future. We recently introduced machine learning methods for discovering optimal strategies for human decision-making automatically and an automatic method for explaining those strategies to people. Decision aids constructed by this method were able to improve human decision-making. However, following the descriptions generated by this method is very tedious. We hypothesized that this problem can be overcome by conveying the automatically discovered decision strategy as a series of natural language instructions for how to reach a decision. Experiment 1 showed that people do indeed understand such procedural instructions more easily than the decision aids generated by our previous method. Encouraged by this finding, we developed an algorithm for translating the output of our previous method into procedural instructions. We applied the improved method to automatically generate decision aids for a naturalistic planning task (i.e., planning a road trip) and a naturalistic decision task (i.e., choosing a mortgage). Experiment 2 showed that these automatically generated decision-aids significantly improved people's performance in planning a road trip and choosing a mortgage. These findings suggest that AI-powered boosting has potential for improving human decision-making in the real world.
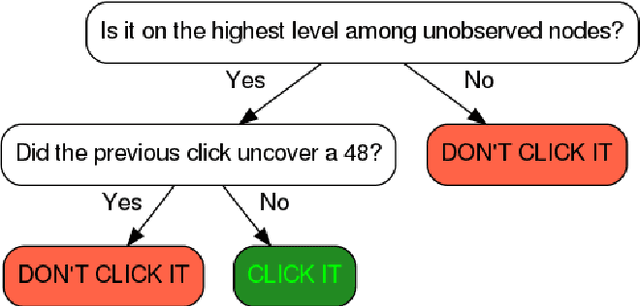
Have I done enough planning or should I plan more?
Jan 03, 2022


People's decisions about how to allocate their limited computational resources are essential to human intelligence. An important component of this metacognitive ability is deciding whether to continue thinking about what to do and move on to the next decision. Here, we show that people acquire this ability through learning and reverse-engineer the underlying learning mechanisms. Using a process-tracing paradigm that externalises human planning, we find that people quickly adapt how much planning they perform to the cost and benefit of planning. To discover the underlying metacognitive learning mechanisms we augmented a set of reinforcement learning models with metacognitive features and performed Bayesian model selection. Our results suggest that the metacognitive ability to adjust the amount of planning might be learned through a policy-gradient mechanism that is guided by metacognitive pseudo-rewards that communicate the value of planning.
Automatic discovery and description of human planning strategies
Sep 29, 2021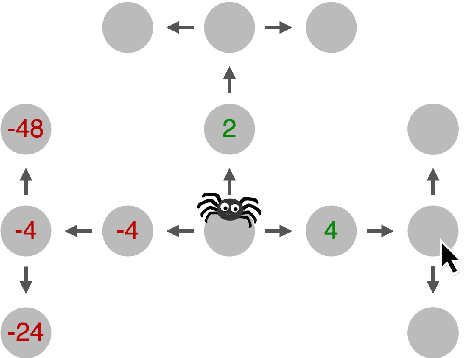

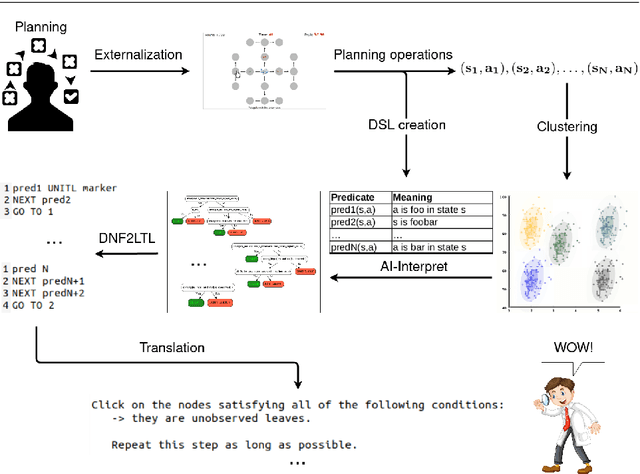
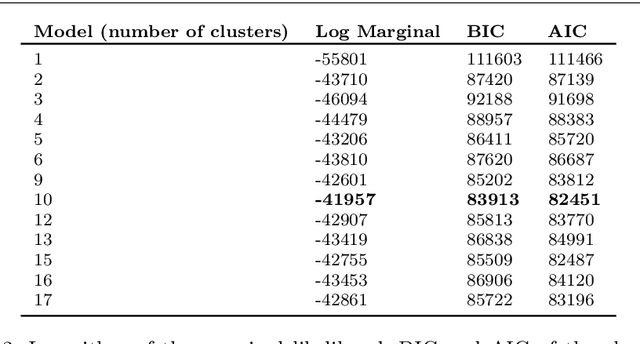
Scientific discovery concerns finding patterns in data and creating insightful hypotheses that explain these patterns. Traditionally, this process required human ingenuity, but with the galloping advances in artificial intelligence (AI) it becomes feasible to automate some parts of scientific discovery. In this work we leverage AI for strategy discovery for understanding human planning. In the state-of-the-art methods data about the process of human planning is often used to group similar behaviors together and formulate verbal descriptions of the strategies which might underlie those groups. Here, we automate these two steps. Our algorithm, called Human-Interpret, uses imitation learning to describe process-tracing data collected in psychological experiments with the Mouselab-MDP paradigm in terms of a procedural formula. Then, it translates that formula to natural language using a pre-defined predicate dictionary. We test our method on a benchmark data set that researchers have previously scrutinized manually. We find that the descriptions of human planning strategies obtained automatically are about as understandable as human-generated descriptions. They also cover a substantial proportion of all types of human planning strategies that had been discovered manually. Our method saves scientists' time and effort as all the reasoning about human planning is done automatically. This might make it feasible to more rapidly scale up the search for yet undiscovered cognitive strategies to many new decision environments, populations, tasks, and domains. Given these results, we believe that the presented work may accelerate scientific discovery in psychology, and due to its generality, extend to problems from other fields.
Optimal To-Do List Gamification for Long Term Planning
Sep 15, 2021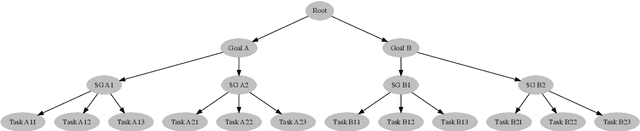
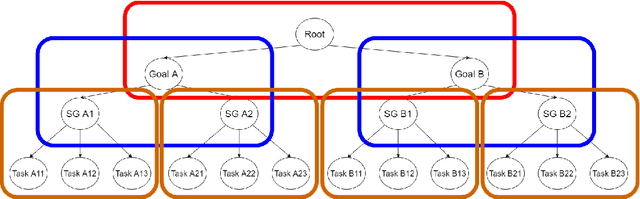
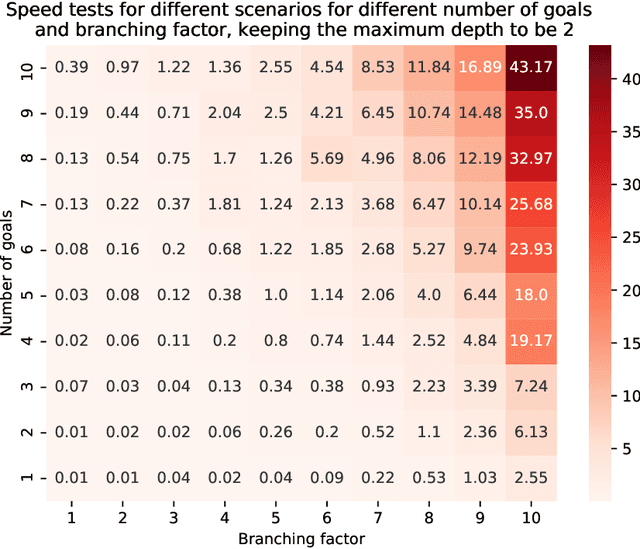
Most people struggle with prioritizing work. While inexact heuristics have been developed over time, there is still no tractable principled algorithm for deciding which of the many possible tasks one should tackle in any given day, month, week, or year. Additionally, some people suffer from cognitive biases such as the present bias, leading to prioritization of their immediate experience over long-term consequences which manifests itself as procrastination and inefficient task prioritization. Our method utilizes optimal gamification to help people overcome these problems by incentivizing each task by a number of points that convey how valuable it is in the long-run. We extend the previous version of our optimal gamification method with added services for helping people decide which tasks should and should not be done when there is not enough time to do everything. To improve the efficiency and scalability of the to-do list solver, we designed a hierarchical procedure that tackles the problem from the top-level goals to fine-grained tasks. We test the accuracy of the incentivised to-do list by comparing the performance of the strategy with the points computed exactly using Value Iteration for a variety of case studies. These case studies were specifically designed to cover the corner cases to get an accurate judge of performance. Our method yielded the same performance as the exact method for all case studies. To demonstrate its functionality, we released an API that makes it easy to deploy our method in Web and app services. We assessed the scalability of our method by applying it to to-do lists with increasingly larger numbers of goals, sub-goals per goal, hierarchically nested levels of subgoals. We found that the method provided through our API is able to tackle fairly large to-do lists having a 576 tasks. This indicates that our method is suitable for real-world applications.