 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Twice, Act Once: Verifier-Guided Action Selection For Embodied Agents
May 12, 2026Building generalist embodied agents capable of solving complex real-world tasks remains a fundamental challenge in AI. Multimodal Large Language Models (MLLMs) have significantly advanced the reasoning capabilities of such agents through strong vision-language knowledge and chain-of-thought (CoT) reasoning, yet remain brittle when faced with challenging out-of-distribution scenarios. To address this, we propose Verifier-Guided Action Selection (VegAS), a test-time framework designed to improve the robustness of MLLM-based embodied agents through an explicit verification step. At inference time, rather than committing to a single decoded action, VeGAS samples an ensemble of candidate actions and uses a generative verifier to identify the most reliable choice, without modifying the underlying policy. Crucially, we find that using an MLLM off-the-shelf as a verifier yields no improvement, motivating our LLM-driven data synthesis strategy, which automatically constructs a diverse curriculum of failure cases to expose the verifier to a rich distribution of potential errors at training time. Across embodied reasoning benchmarks spanning the Habitat and ALFRED environments, VeGAS consistently improves generalization, achieving up to a 36% relative performance gain over strong CoT baselines on the most challenging multi-object, long-horizon tasks.
When To Solve, When To Verify: Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning
Apr 01, 2025Scaling test-time compute has emerged as a key strategy for enhancing the reasoning capabilities of large language models (LLMs), particularly in tasks like mathematical problem-solving. A traditional approach, Self-Consistency (SC), generates multiple solutions to a problem and selects the most common answer via majority voting. Another common method involves scoring each solution with a reward model (verifier) and choosing the best one. Recent advancements in Generative Reward Models (GenRM) reframe verification as a next-token prediction task, enabling inference-time scaling along a new axis. Specifically, GenRM generates multiple verification chains-of-thought to score each solution. Under a limited inference budget, this introduces a fundamental trade-off: should you spend the budget on scaling solutions via SC or generate fewer solutions and allocate compute to verification via GenRM? To address this, we evaluate GenRM against SC under a fixed inference budget. Interestingly, we find that SC is more compute-efficient than GenRM for most practical inference budgets across diverse models and datasets. For instance, GenRM first matches SC after consuming up to 8x the inference compute and requires significantly more compute to outperform it. Furthermore, we derive inference scaling laws for the GenRM paradigm, revealing that compute-optimal inference favors scaling solution generation more aggressively than scaling the number of verifications. Our work provides practical guidance on optimizing test-time scaling by balancing solution generation and verification. The code is available at https://github.com/nishadsinghi/sc-genrm-scaling.
Centaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Improving Intervention Efficacy via Concept Realignment in Concept Bottleneck Models
May 02, 2024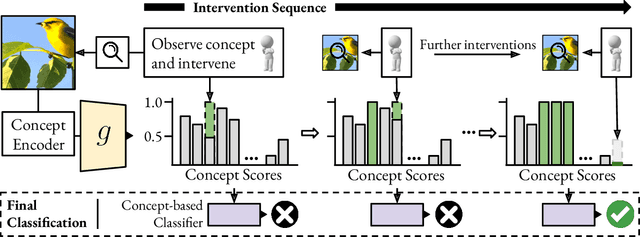


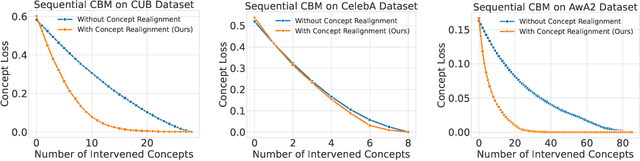
Concept Bottleneck Models (CBMs) ground image classification on human-understandable concepts to allow for interpretable model decisions. Crucially, the CBM design inherently allows for human interventions, in which expert users are given the ability to modify potentially misaligned concept choices to influence the decision behavior of the model in an interpretable fashion. However, existing approaches often require numerous human interventions per image to achieve strong performances, posing practical challenges in scenarios where obtaining human feedback is expensive. In this paper, we find that this is noticeably driven by an independent treatment of concepts during intervention, wherein a change of one concept does not influence the use of other ones in the model's final decision. To address this issue, we introduce a trainable concept intervention realignment module, which leverages concept relations to realign concept assignments post-intervention. Across standard, real-world benchmarks, we find that concept realignment can significantly improve intervention efficacy; significantly reducing the number of interventions needed to reach a target classification performance or concept prediction accuracy. In addition, it easily integrates into existing concept-based architectures without requiring changes to the models themselves. This reduced cost of human-model collaboration is crucial to enhancing the feasibility of CBMs in resource-constrained environments.
CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning
Mar 08, 2023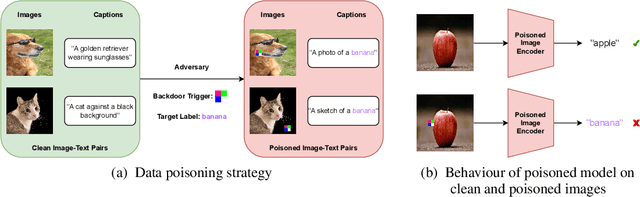



Multimodal contrastive pretraining has been used to train multimodal representation models, such as CLIP, on large amounts of paired image-text data. However, previous studies have revealed that such models are vulnerable to backdoor attacks. Specifically, when trained on backdoored examples, CLIP learns spurious correlations between the embedded backdoor trigger and the target label, aligning their representations in the joint embedding space. Injecting even a small number of poisoned examples, such as 75 examples in 3 million pretraining data, can significantly manipulate the model's behavior, making it difficult to detect or unlearn such correlations. To address this issue, we propose CleanCLIP, a finetuning framework that weakens the learned spurious associations introduced by backdoor attacks by independently re-aligning the representations for individual modalities. We demonstrate that unsupervised finetuning using a combination of multimodal contrastive and unimodal self-supervised objectives for individual modalities can significantly reduce the impact of the backdoor attack. Additionally, we show that supervised finetuning on task-specific labeled image data removes the backdoor trigger from the CLIP vision encoder. We show empirically that CleanCLIP maintains model performance on benign examples while erasing a range of backdoor attacks on multimodal contrastive learning.
Toward a normative theory of management by goal-setting
Feb 06, 2023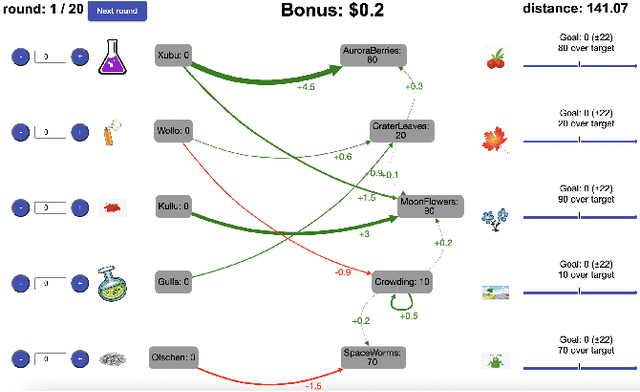
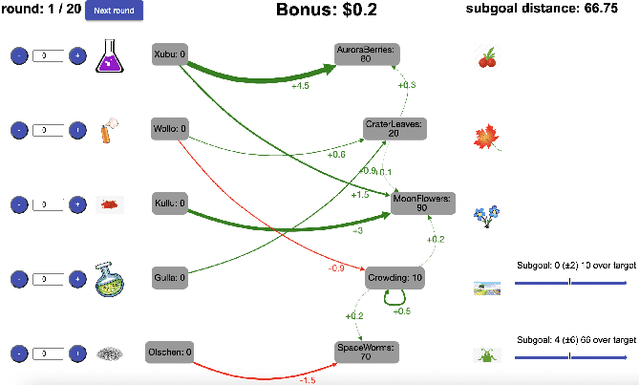
People are often confronted with problems whose complexity exceeds their cognitive capacities. To deal with this complexity, individuals and managers can break complex problems down into a series of subgoals. Which subgoals are most effective depends on people's cognitive constraints and the cognitive mechanisms of goal pursuit. This creates an untapped opportunity to derive practical recommendations for which subgoals managers and individuals should set from cognitive models of bounded rationality. To seize this opportunity, we apply the principle of resource-rationality to formulate a mathematically precise normative theory of (self-)management by goal-setting. We leverage this theory to computationally derive optimal subgoals from a resource-rational model of human goal pursuit. Finally, we show that the resulting subgoals improve the problem-solving performance of bounded agents and human participants. This constitutes a first step towards grounding prescriptive theories of management and practical recommendations for goal-setting in computational models of the relevant psychological processes and cognitive limitations.