 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility with Language Models for Open-World Compositional Zero-Shot Learning
May 16, 2025Humans can easily tell if an attribute (also called state) is realistic, i.e., feasible, for an object, e.g. fire can be hot, but it cannot be wet. In Open-World Compositional Zero-Shot Learning, when all possible state-object combinations are considered as unseen classes, zero-shot predictors tend to perform poorly. Our work focuses on using external auxiliary knowledge to determine the feasibility of state-object combinations. Our Feasibility with Language Model (FLM) is a simple and effective approach that leverages Large Language Models (LLMs) to better comprehend the semantic relationships between states and objects. FLM involves querying an LLM about the feasibility of a given pair and retrieving the output logit for the positive answer. To mitigate potential misguidance of the LLM given that many of the state-object compositions are rare or completely infeasible, we observe that the in-context learning ability of LLMs is essential. We present an extensive study identifying Vicuna and ChatGPT as best performing, and we demonstrate that our FLM consistently improves OW-CZSL performance across all three benchmarks.
LoFT: LoRA-fused Training Dataset Generation with Few-shot Guidance
May 16, 2025Despite recent advances in text-to-image generation, using synthetically generated data seldom brings a significant boost in performance for supervised learning. Oftentimes, synthetic datasets do not faithfully recreate the data distribution of real data, i.e., they lack the fidelity or diversity needed for effective downstream model training. While previous work has employed few-shot guidance to address this issue, existing methods still fail to capture and generate features unique to specific real images. In this paper, we introduce a novel dataset generation framework named LoFT, LoRA-Fused Training-data Generation with Few-shot Guidance. Our method fine-tunes LoRA weights on individual real images and fuses them at inference time, producing synthetic images that combine the features of real images for improved diversity and fidelity of generated data. We evaluate the synthetic data produced by LoFT on 10 datasets, using 8 to 64 real images per class as guidance and scaling up to 1000 images per class. Our experiments show that training on LoFT-generated data consistently outperforms other synthetic dataset methods, significantly increasing accuracy as the dataset size increases. Additionally, our analysis demonstrates that LoFT generates datasets with high fidelity and sufficient diversity, which contribute to the performance improvement. The code is available at https://github.com/ExplainableML/LoFT.
Does Feasibility Matter? Understanding the Impact of Feasibility on Synthetic Training Data
May 15, 2025With the development of photorealistic diffusion models, models trained in part or fully on synthetic data achieve progressively better results. However, diffusion models still routinely generate images that would not exist in reality, such as a dog floating above the ground or with unrealistic texture artifacts. We define the concept of feasibility as whether attributes in a synthetic image could realistically exist in the real-world domain; synthetic images containing attributes that violate this criterion are considered infeasible. Intuitively, infeasible images are typically considered out-of-distribution; thus, training on such images is expected to hinder a model's ability to generalize to real-world data, and they should therefore be excluded from the training set whenever possible. However, does feasibility really matter? In this paper, we investigate whether enforcing feasibility is necessary when generating synthetic training data for CLIP-based classifiers, focusing on three target attributes: background, color, and texture. We introduce VariReal, a pipeline that minimally edits a given source image to include feasible or infeasible attributes given by the textual prompt generated by a large language model. Our experiments show that feasibility minimally affects LoRA-fine-tuned CLIP performance, with mostly less than 0.3% difference in top-1 accuracy across three fine-grained datasets. Also, the attribute matters on whether the feasible/infeasible images adversarially influence the classification performance. Finally, mixing feasible and infeasible images in training datasets does not significantly impact performance compared to using purely feasible or infeasible datasets.
DataDream: Few-shot Guided Dataset Generation
Jul 16, 2024
While text-to-image diffusion models have been shown to achieve state-of-the-art results in image synthesis, they have yet to prove their effectiveness in downstream applications. Previous work has proposed to generate data for image classifier training given limited real data access. However, these methods struggle to generate in-distribution images or depict fine-grained features, thereby hindering the generalization of classification models trained on synthetic datasets. We propose DataDream, a framework for synthesizing classification datasets that more faithfully represents the real data distribution when guided by few-shot examples of the target classes. DataDream fine-tunes LoRA weights for the image generation model on the few real images before generating the training data using the adapted model. We then fine-tune LoRA weights for CLIP using the synthetic data to improve downstream image classification over previous approaches on a large variety of datasets. We demonstrate the efficacy of DataDream through extensive experiments, surpassing state-of-the-art classification accuracy with few-shot data across 7 out of 10 datasets, while being competitive on the other 3. Additionally, we provide insights into the impact of various factors, such as the number of real-shot and generated images as well as the fine-tuning compute on model performance. The code is available at https://github.com/ExplainableML/DataDream.
Improving Intervention Efficacy via Concept Realignment in Concept Bottleneck Models
May 02, 2024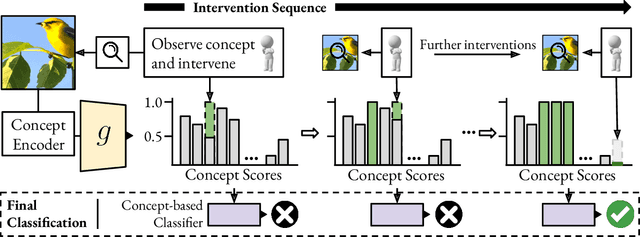


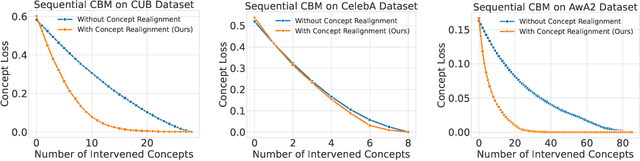
Concept Bottleneck Models (CBMs) ground image classification on human-understandable concepts to allow for interpretable model decisions. Crucially, the CBM design inherently allows for human interventions, in which expert users are given the ability to modify potentially misaligned concept choices to influence the decision behavior of the model in an interpretable fashion. However, existing approaches often require numerous human interventions per image to achieve strong performances, posing practical challenges in scenarios where obtaining human feedback is expensive. In this paper, we find that this is noticeably driven by an independent treatment of concepts during intervention, wherein a change of one concept does not influence the use of other ones in the model's final decision. To address this issue, we introduce a trainable concept intervention realignment module, which leverages concept relations to realign concept assignments post-intervention. Across standard, real-world benchmarks, we find that concept realignment can significantly improve intervention efficacy; significantly reducing the number of interventions needed to reach a target classification performance or concept prediction accuracy. In addition, it easily integrates into existing concept-based architectures without requiring changes to the models themselves. This reduced cost of human-model collaboration is crucial to enhancing the feasibility of CBMs in resource-constrained environments.
Waffling around for Performance: Visual Classification with Random Words and Broad Concepts
Jun 12, 2023



The visual classification performance of vision-language models such as CLIP can benefit from additional semantic knowledge, e.g. via large language models (LLMs) such as GPT-3. Further extending classnames with LLM-generated class descriptors, e.g. ``waffle, \textit{which has a round shape}'', or averaging retrieval scores over multiple such descriptors, has been shown to improve generalization performance. In this work, we study this behavior in detail and propose \texttt{Waffle}CLIP, a framework for zero-shot visual classification which achieves similar performance gains on a large number of visual classification tasks by simply replacing LLM-generated descriptors with random character and word descriptors \textbf{without} querying external models. We extend these results with an extensive experimental study on the impact and shortcomings of additional semantics introduced via LLM-generated descriptors, and showcase how semantic context is better leveraged by automatically querying LLMs for high-level concepts, while jointly resolving potential class name ambiguities. Link to the codebase: https://github.com/ExplainableML/WaffleCLIP.
Exposing and Mitigating Spurious Correlations for Cross-Modal Retrieval
Apr 06, 2023



Cross-modal retrieval methods are the preferred tool to search databases for the text that best matches a query image and vice versa. However, image-text retrieval models commonly learn to memorize spurious correlations in the training data, such as frequent object co-occurrence, instead of looking at the actual underlying reasons for the prediction in the image. For image-text retrieval, this manifests in retrieved sentences that mention objects that are not present in the query image. In this work, we introduce ODmAP@k, an object decorrelation metric that measures a model's robustness to spurious correlations in the training data. We use automatic image and text manipulations to control the presence of such object correlations in designated test data. Additionally, our data synthesis technique is used to tackle model biases due to spurious correlations of semantically unrelated objects in the training data. We apply our proposed pipeline, which involves the finetuning of image-text retrieval frameworks on carefully designed synthetic data, to three state-of-the-art models for image-text retrieval. This results in significant improvements for all three models, both in terms of the standard retrieval performance and in terms of our object decorrelation metric. The code is available at https://github.com/ExplainableML/Spurious_CM_Retrieval.
Bridging the Gap between Model Explanations in Partially Annotated Multi-label Classification
Apr 04, 2023Due to the expensive costs of collecting labels in multi-label classification datasets, partially annotated multi-label classification has become an emerging field in computer vision. One baseline approach to this task is to assume unobserved labels as negative labels, but this assumption induces label noise as a form of false negative. To understand the negative impact caused by false negative labels, we study how these labels affect the model's explanation. We observe that the explanation of two models, trained with full and partial labels each, highlights similar regions but with different scaling, where the latter tends to have lower attribution scores. Based on these findings, we propose to boost the attribution scores of the model trained with partial labels to make its explanation resemble that of the model trained with full labels. Even with the conceptually simple approach, the multi-label classification performance improves by a large margin in three different datasets on a single positive label setting and one on a large-scale partial label setting. Code is available at https://github.com/youngwk/BridgeGapExplanationPAMC.
Posterior Annealing: Fast Calibrated Uncertainty for Regression
Feb 21, 2023Bayesian deep learning approaches that allow uncertainty estimation for regression problems often converge slowly and yield poorly calibrated uncertainty estimates that can not be effectively used for quantification. Recently proposed post hoc calibration techniques are seldom applicable to regression problems and often add overhead to an already slow model training phase. This work presents a fast calibrated uncertainty estimation method for regression tasks, called posterior annealing, that consistently improves the convergence of deep regression models and yields calibrated uncertainty without any post hoc calibration phase. Unlike previous methods for calibrated uncertainty in regression that focus only on low-dimensional regression problems, our method works well on a wide spectrum of regression problems. Our empirical analysis shows that our approach is generalizable to various network architectures including, multilayer perceptrons, 1D/2D convolutional networks, and graph neural networks, on five vastly diverse tasks, i.e., chaotic particle trajectory denoising, physical property prediction of molecules using 3D atomistic representation, natural image super-resolution, and medical image translation using MRI images.
Large Loss Matters in Weakly Supervised Multi-Label Classification
Jun 08, 2022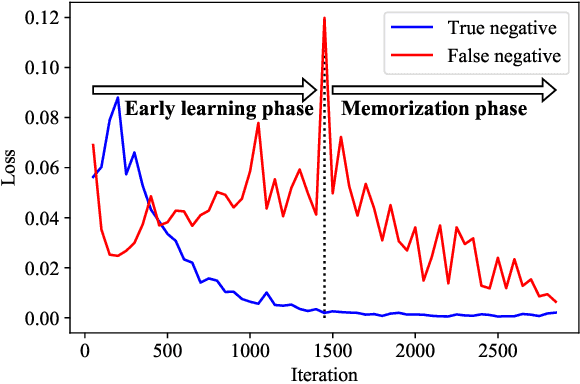

Weakly supervised multi-label classification (WSML) task, which is to learn a multi-label classification using partially observed labels per image, is becoming increasingly important due to its huge annotation cost. In this work, we first regard unobserved labels as negative labels, casting the WSML task into noisy multi-label classification. From this point of view, we empirically observe that memorization effect, which was first discovered in a noisy multi-class setting, also occurs in a multi-label setting. That is, the model first learns the representation of clean labels, and then starts memorizing noisy labels. Based on this finding, we propose novel methods for WSML which reject or correct the large loss samples to prevent model from memorizing the noisy label. Without heavy and complex components, our proposed methods outperform previous state-of-the-art WSML methods on several partial label settings including Pascal VOC 2012, MS COCO, NUSWIDE, CUB, and OpenImages V3 datasets. Various analysis also show that our methodology actually works well, validating that treating large loss properly matters in a weakly supervised multi-label classification. Our code is available at https://github.com/snucml/LargeLossMatters.