 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap between Model Explanations in Partially Annotated Multi-label Classification
Apr 04, 2023Due to the expensive costs of collecting labels in multi-label classification datasets, partially annotated multi-label classification has become an emerging field in computer vision. One baseline approach to this task is to assume unobserved labels as negative labels, but this assumption induces label noise as a form of false negative. To understand the negative impact caused by false negative labels, we study how these labels affect the model's explanation. We observe that the explanation of two models, trained with full and partial labels each, highlights similar regions but with different scaling, where the latter tends to have lower attribution scores. Based on these findings, we propose to boost the attribution scores of the model trained with partial labels to make its explanation resemble that of the model trained with full labels. Even with the conceptually simple approach, the multi-label classification performance improves by a large margin in three different datasets on a single positive label setting and one on a large-scale partial label setting. Code is available at https://github.com/youngwk/BridgeGapExplanationPAMC.
Modularized Transfer Learning with Multiple Knowledge Graphs for Zero-shot Commonsense Reasoning
Jun 22, 2022
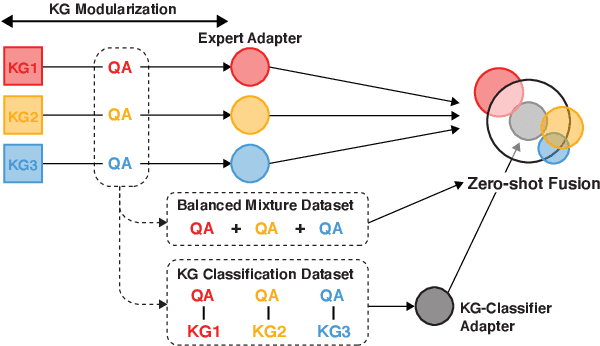
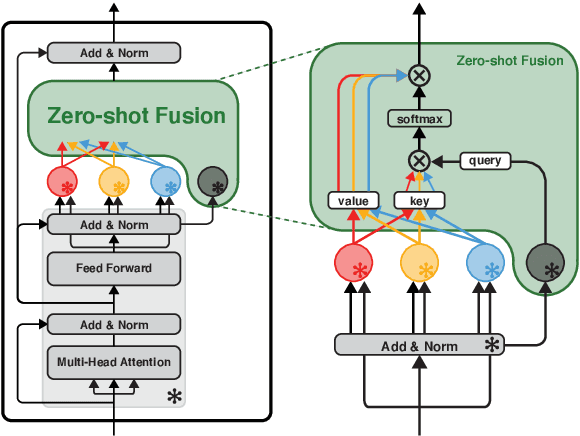

Commonsense reasoning systems should be able to generalize to diverse reasoning cases. However, most state-of-the-art approaches depend on expensive data annotations and overfit to a specific benchmark without learning how to perform general semantic reasoning. To overcome these drawbacks, zero-shot QA systems have shown promise as a robust learning scheme by transforming a commonsense knowledge graph (KG) into synthetic QA-form samples for model training. Considering the increasing type of different commonsense KGs, this paper aims to extend the zero-shot transfer learning scenario into multiple-source settings, where different KGs can be utilized synergetically. Towards this goal, we propose to mitigate the loss of knowledge from the interference among the different knowledge sources, by developing a modular variant of the knowledge aggregation as a new zero-shot commonsense reasoning framework. Results on five commonsense reasoning benchmarks demonstrate the efficacy of our framework, improving the performance with multiple KGs.
Large Loss Matters in Weakly Supervised Multi-Label Classification
Jun 08, 2022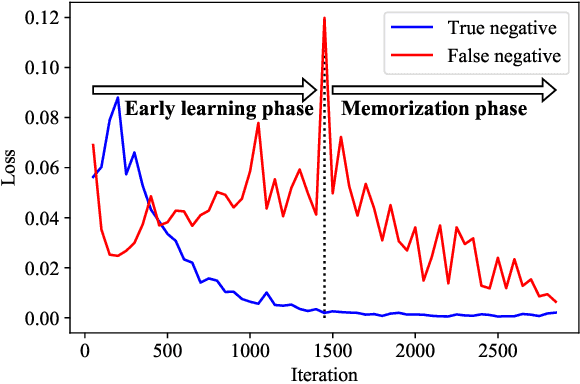

Weakly supervised multi-label classification (WSML) task, which is to learn a multi-label classification using partially observed labels per image, is becoming increasingly important due to its huge annotation cost. In this work, we first regard unobserved labels as negative labels, casting the WSML task into noisy multi-label classification. From this point of view, we empirically observe that memorization effect, which was first discovered in a noisy multi-class setting, also occurs in a multi-label setting. That is, the model first learns the representation of clean labels, and then starts memorizing noisy labels. Based on this finding, we propose novel methods for WSML which reject or correct the large loss samples to prevent model from memorizing the noisy label. Without heavy and complex components, our proposed methods outperform previous state-of-the-art WSML methods on several partial label settings including Pascal VOC 2012, MS COCO, NUSWIDE, CUB, and OpenImages V3 datasets. Various analysis also show that our methodology actually works well, validating that treating large loss properly matters in a weakly supervised multi-label classification. Our code is available at https://github.com/snucml/LargeLossMatters.
Dual Task Framework for Improving Persona-grounded Dialogue Dataset
Feb 16, 2022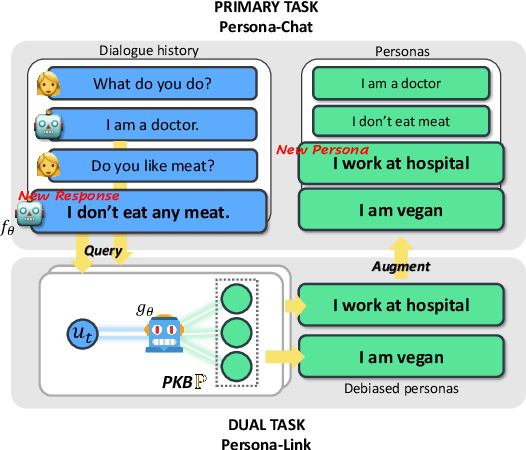
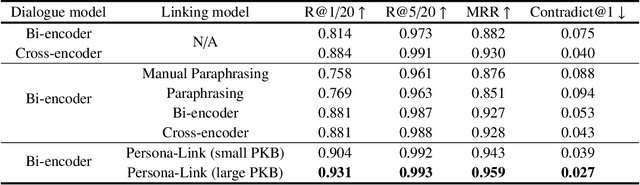

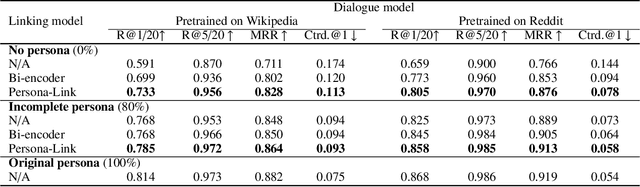
This paper introduces a simple yet effective data-centric approach for the task of improving persona-conditioned dialogue agents. Prior model-centric approaches unquestioningly depend on the raw crowdsourced benchmark datasets such as Persona-Chat. In contrast, we aim to fix annotation artifacts in benchmarking, which is orthogonally applicable to any dialogue model. Specifically, we augment relevant personas to improve dialogue dataset/agent, by leveraging the primal-dual structure of the two tasks, predicting dialogue responses and personas based on each other. Experiments on Persona-Chat show that our approach outperforms pre-trained LMs by an 11.7 point gain in terms of accuracy.
TrustAL: Trustworthy Active Learning using Knowledge Distillation
Jan 26, 2022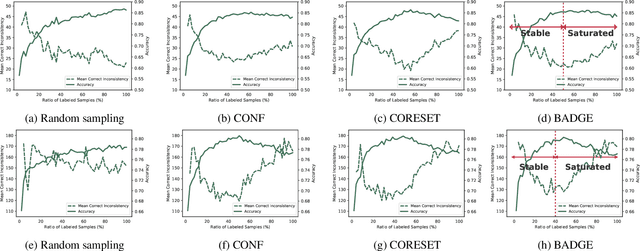
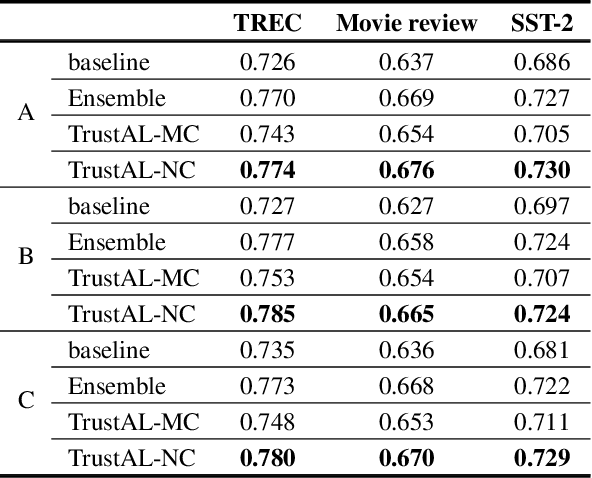
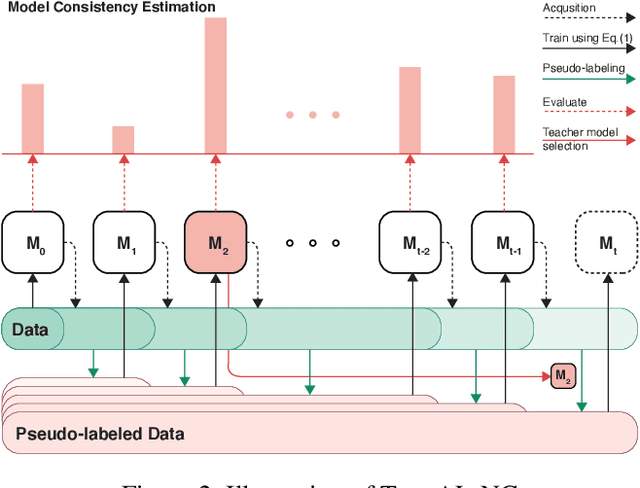
Active learning can be defined as iterations of data labeling, model training, and data acquisition, until sufficient labels are acquired. A traditional view of data acquisition is that, through iterations, knowledge from human labels and models is implicitly distilled to monotonically increase the accuracy and label consistency. Under this assumption, the most recently trained model is a good surrogate for the current labeled data, from which data acquisition is requested based on uncertainty/diversity. Our contribution is debunking this myth and proposing a new objective for distillation. First, we found example forgetting, which indicates the loss of knowledge learned across iterations. Second, for this reason, the last model is no longer the best teacher -- For mitigating such forgotten knowledge, we select one of its predecessor models as a teacher, by our proposed notion of "consistency". We show that this novel distillation is distinctive in the following three aspects; First, consistency ensures to avoid forgetting labels. Second, consistency improves both uncertainty/diversity of labeled data. Lastly, consistency redeems defective labels produced by human annotators.