Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Task Framework for Improving Persona-grounded Dialogue Dataset
Paper and Code
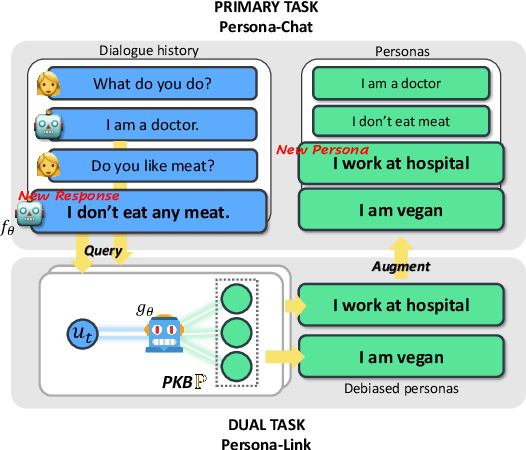
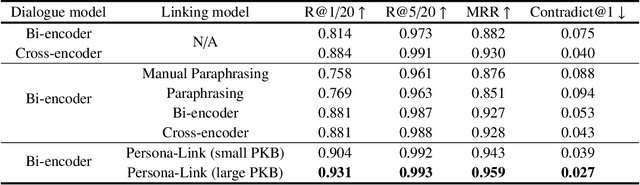

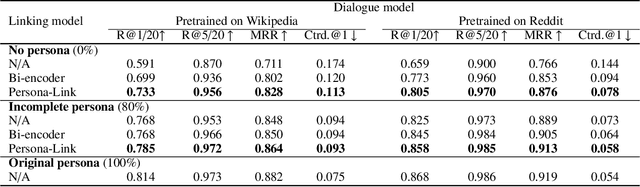
This paper introduces a simple yet effective data-centric approach for the task of improving persona-conditioned dialogue agents. Prior model-centric approaches unquestioningly depend on the raw crowdsourced benchmark datasets such as Persona-Chat. In contrast, we aim to fix annotation artifacts in benchmarking, which is orthogonally applicable to any dialogue model. Specifically, we augment relevant personas to improve dialogue dataset/agent, by leveraging the primal-dual structure of the two tasks, predicting dialogue responses and personas based on each other. Experiments on Persona-Chat show that our approach outperforms pre-trained LMs by an 11.7 point gain in terms of accuracy.
* Accepted to AAAI2022
View paper on