 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack into Plato's Cave: Examining Cross-modal Representational Convergence at Scale
Apr 20, 2026The Platonic Representation Hypothesis suggests that neural networks trained on different modalities (e.g., text and images) align and eventually converge toward the same representation of reality. If true, this has significant implications for whether modality choice matters at all. We show that the experimental evidence for this hypothesis is fragile and depends critically on the evaluation regime. Alignment is measured using mutual nearest neighbors on small datasets ($\approx$1K samples) and degrades substantially as the dataset is scaled to millions of samples. The alignment that remains between model representations reflects coarse semantic overlap rather than consistent fine-grained structure. Moreover, the evaluations in Huh et al. are done in a one-to-one image-caption setting, a constraint that breaks down in realistic many-to-many settings and further reduces alignment. We also find that the reported trend of stronger language models increasingly aligning with vision does not appear to hold for newer models. Overall, our findings suggest that the current evidence for cross-modal representational convergence is considerably weaker than subsequent works have taken it to be. Models trained on different modalities may learn equally rich representations of the world, just not the same one.
It's Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models
Dec 31, 2025Contemporary text-to-image models exhibit a surprising degree of mode collapse, as can be seen when sampling several images given the same text prompt. While previous work has attempted to address this issue by steering the model using guidance mechanisms, or by generating a large pool of candidates and refining them, in this work we take a different direction and aim for diversity in generations via noise optimization. Specifically, we show that a simple noise optimization objective can mitigate mode collapse while preserving the fidelity of the base model. We also analyze the frequency characteristics of the noise and show that alternative noise initializations with different frequency profiles can improve both optimization and search. Our experiments demonstrate that noise optimization yields superior results in terms of generation quality and variety.
VGGSounder: Audio-Visual Evaluations for Foundation Models
Aug 12, 2025The emergence of audio-visual foundation models underscores the importance of reliably assessing their multi-modal understanding. The VGGSound dataset is commonly used as a benchmark for evaluation audio-visual classification. However, our analysis identifies several limitations of VGGSound, including incomplete labelling, partially overlapping classes, and misaligned modalities. These lead to distorted evaluations of auditory and visual capabilities. To address these limitations, we introduce VGGSounder, a comprehensively re-annotated, multi-label test set that extends VGGSound and is specifically designed to evaluate audio-visual foundation models. VGGSounder features detailed modality annotations, enabling precise analyses of modality-specific performance. Furthermore, we reveal model limitations by analysing performance degradation when adding another input modality with our new modality confusion metric.
Dissecting Temporal Understanding in Text-to-Audio Retrieval
Sep 01, 2024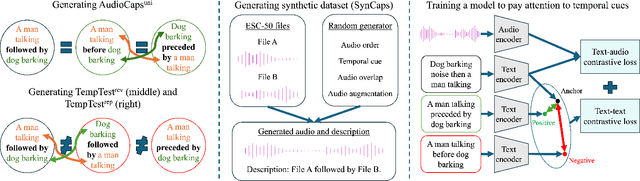
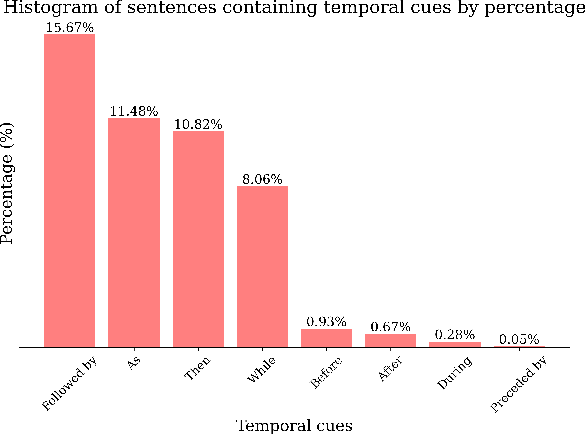
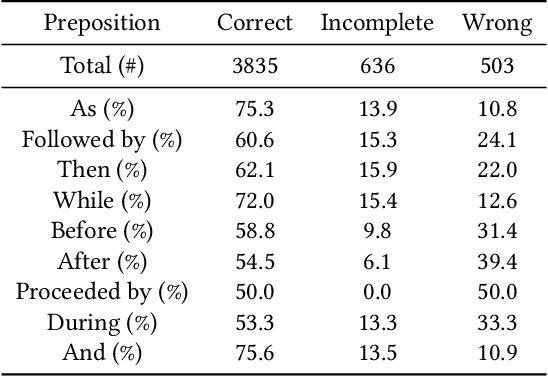
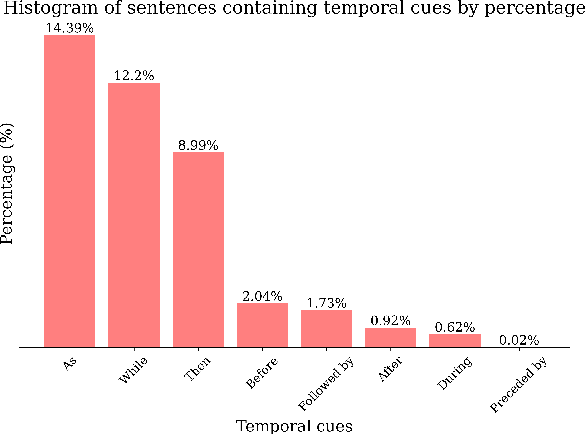
Recent advancements in machine learning have fueled research on multimodal tasks, such as for instance text-to-video and text-to-audio retrieval. These tasks require models to understand the semantic content of video and audio data, including objects, and characters. The models also need to learn spatial arrangements and temporal relationships. In this work, we analyse the temporal ordering of sounds, which is an understudied problem in the context of text-to-audio retrieval. In particular, we dissect the temporal understanding capabilities of a state-of-the-art model for text-to-audio retrieval on the AudioCaps and Clotho datasets. Additionally, we introduce a synthetic text-audio dataset that provides a controlled setting for evaluating temporal capabilities of recent models. Lastly, we present a loss function that encourages text-audio models to focus on the temporal ordering of events. Code and data are available at https://www.robots.ox.ac.uk/~vgg/research/audio-retrieval/dtu/.
Audio-Visual Generalized Zero-Shot Learning using Pre-Trained Large Multi-Modal Models
Apr 09, 2024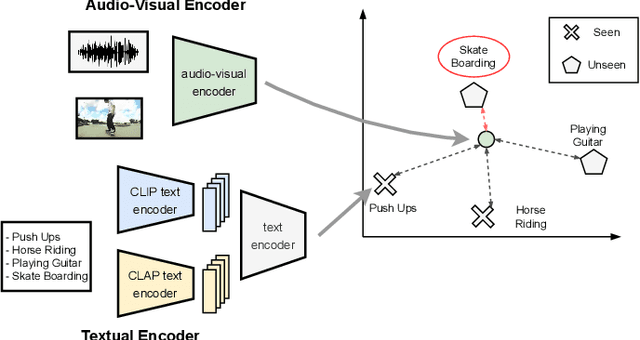

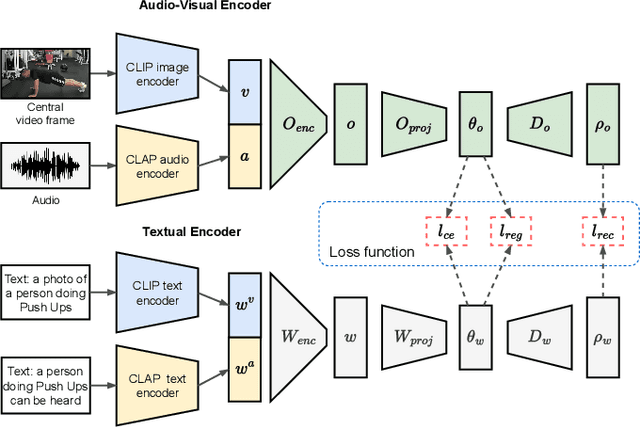

Audio-visual zero-shot learning methods commonly build on features extracted from pre-trained models, e.g. video or audio classification models. However, existing benchmarks predate the popularization of large multi-modal models, such as CLIP and CLAP. In this work, we explore such large pre-trained models to obtain features, i.e. CLIP for visual features, and CLAP for audio features. Furthermore, the CLIP and CLAP text encoders provide class label embeddings which are combined to boost the performance of the system. We propose a simple yet effective model that only relies on feed-forward neural networks, exploiting the strong generalization capabilities of the new audio, visual and textual features. Our framework achieves state-of-the-art performance on VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL with our new features. Code and data available at: https://github.com/dkurzend/ClipClap-GZSL.
A SOUND APPROACH: Using Large Language Models to generate audio descriptions for egocentric text-audio retrieval
Feb 29, 2024Video databases from the internet are a valuable source of text-audio retrieval datasets. However, given that sound and vision streams represent different "views" of the data, treating visual descriptions as audio descriptions is far from optimal. Even if audio class labels are present, they commonly are not very detailed, making them unsuited for text-audio retrieval. To exploit relevant audio information from video-text datasets, we introduce a methodology for generating audio-centric descriptions using Large Language Models (LLMs). In this work, we consider the egocentric video setting and propose three new text-audio retrieval benchmarks based on the EpicMIR and EgoMCQ tasks, and on the EpicSounds dataset. Our approach for obtaining audio-centric descriptions gives significantly higher zero-shot performance than using the original visual-centric descriptions. Furthermore, we show that using the same prompts, we can successfully employ LLMs to improve the retrieval on EpicSounds, compared to using the original audio class labels of the dataset. Finally, we confirm that LLMs can be used to determine the difficulty of identifying the action associated with a sound.
Zero-shot audio captioning with audio-language model guidance and audio context keywords
Nov 14, 2023Zero-shot audio captioning aims at automatically generating descriptive textual captions for audio content without prior training for this task. Different from speech recognition which translates audio content that contains spoken language into text, audio captioning is commonly concerned with ambient sounds, or sounds produced by a human performing an action. Inspired by zero-shot image captioning methods, we propose ZerAuCap, a novel framework for summarising such general audio signals in a text caption without requiring task-specific training. In particular, our framework exploits a pre-trained large language model (LLM) for generating the text which is guided by a pre-trained audio-language model to produce captions that describe the audio content. Additionally, we use audio context keywords that prompt the language model to generate text that is broadly relevant to sounds. Our proposed framework achieves state-of-the-art results in zero-shot audio captioning on the AudioCaps and Clotho datasets. Our code is available at https://github.com/ExplainableML/ZerAuCap.
Zero-shot Translation of Attention Patterns in VQA Models to Natural Language
Nov 08, 2023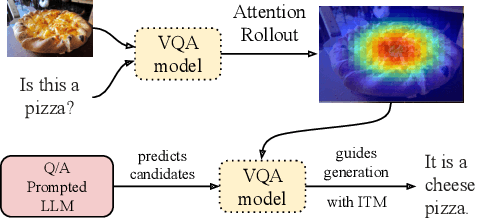
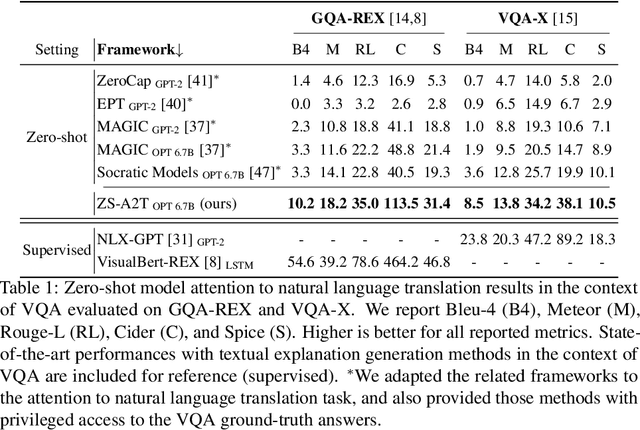
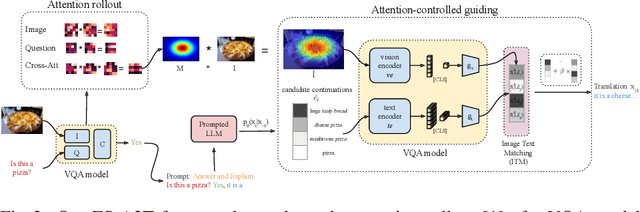

Converting a model's internals to text can yield human-understandable insights about the model. Inspired by the recent success of training-free approaches for image captioning, we propose ZS-A2T, a zero-shot framework that translates the transformer attention of a given model into natural language without requiring any training. We consider this in the context of Visual Question Answering (VQA). ZS-A2T builds on a pre-trained large language model (LLM), which receives a task prompt, question, and predicted answer, as inputs. The LLM is guided to select tokens which describe the regions in the input image that the VQA model attended to. Crucially, we determine this similarity by exploiting the text-image matching capabilities of the underlying VQA model. Our framework does not require any training and allows the drop-in replacement of different guiding sources (e.g. attribution instead of attention maps), or language models. We evaluate this novel task on textual explanation datasets for VQA, giving state-of-the-art performances for the zero-shot setting on GQA-REX and VQA-X. Our code is available at: https://github.com/ExplainableML/ZS-A2T.
Video-adverb retrieval with compositional adverb-action embeddings
Sep 26, 2023Retrieving adverbs that describe an action in a video poses a crucial step towards fine-grained video understanding. We propose a framework for video-to-adverb retrieval (and vice versa) that aligns video embeddings with their matching compositional adverb-action text embedding in a joint embedding space. The compositional adverb-action text embedding is learned using a residual gating mechanism, along with a novel training objective consisting of triplet losses and a regression target. Our method achieves state-of-the-art performance on five recent benchmarks for video-adverb retrieval. Furthermore, we introduce dataset splits to benchmark video-adverb retrieval for unseen adverb-action compositions on subsets of the MSR-VTT Adverbs and ActivityNet Adverbs datasets. Our proposed framework outperforms all prior works for the generalisation task of retrieving adverbs from videos for unseen adverb-action compositions. Code and dataset splits are available at https://hummelth.github.io/ReGaDa/.
Text-to-feature diffusion for audio-visual few-shot learning
Sep 07, 2023
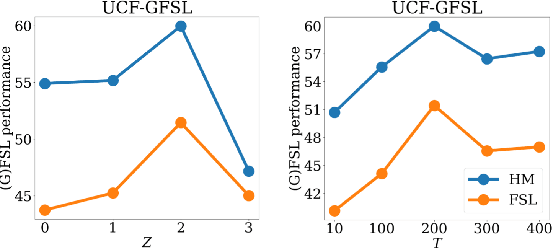
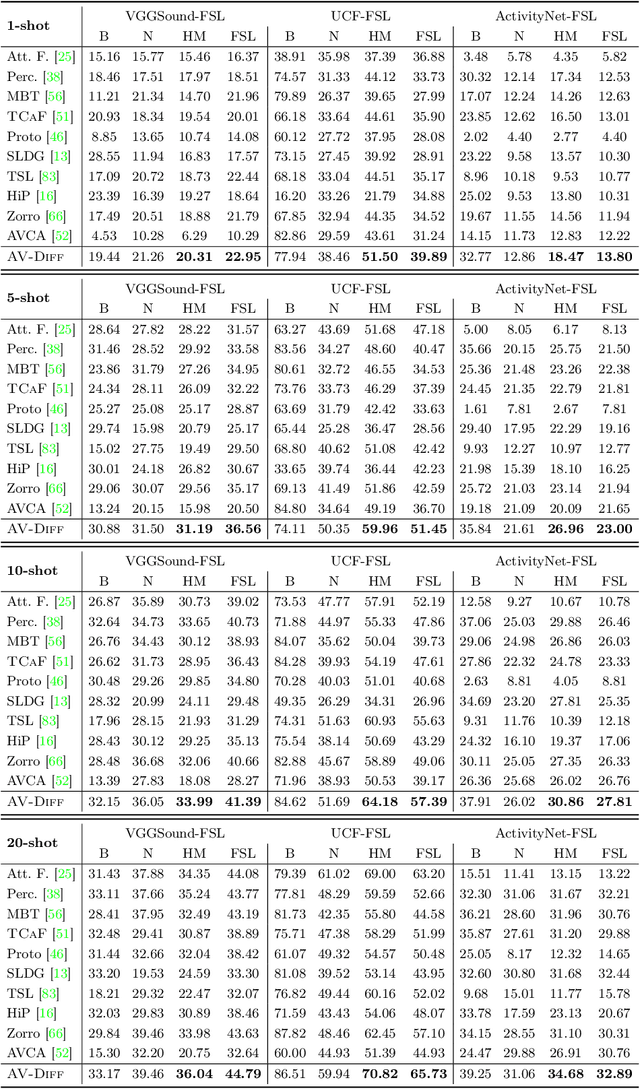
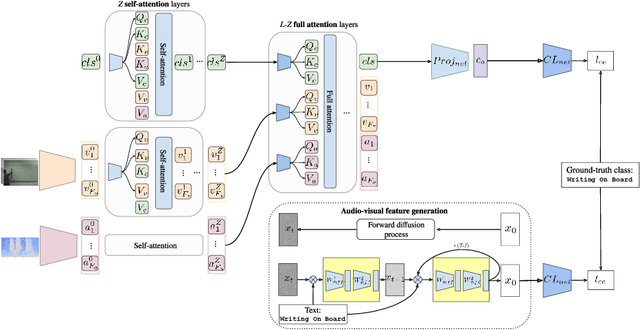
Training deep learning models for video classification from audio-visual data commonly requires immense amounts of labeled training data collected via a costly process. A challenging and underexplored, yet much cheaper, setup is few-shot learning from video data. In particular, the inherently multi-modal nature of video data with sound and visual information has not been leveraged extensively for the few-shot video classification task. Therefore, we introduce a unified audio-visual few-shot video classification benchmark on three datasets, i.e. the VGGSound-FSL, UCF-FSL, ActivityNet-FSL datasets, where we adapt and compare ten methods. In addition, we propose AV-DIFF, a text-to-feature diffusion framework, which first fuses the temporal and audio-visual features via cross-modal attention and then generates multi-modal features for the novel classes. We show that AV-DIFF obtains state-of-the-art performance on our proposed benchmark for audio-visual (generalised) few-shot learning. Our benchmark paves the way for effective audio-visual classification when only limited labeled data is available. Code and data are available at https://github.com/ExplainableML/AVDIFF-GFSL.