 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Temporal Understanding in Text-to-Audio Retrieval
Paper and Code
Sep 01, 2024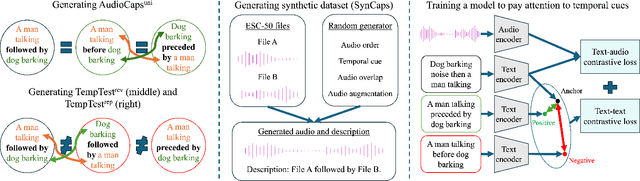
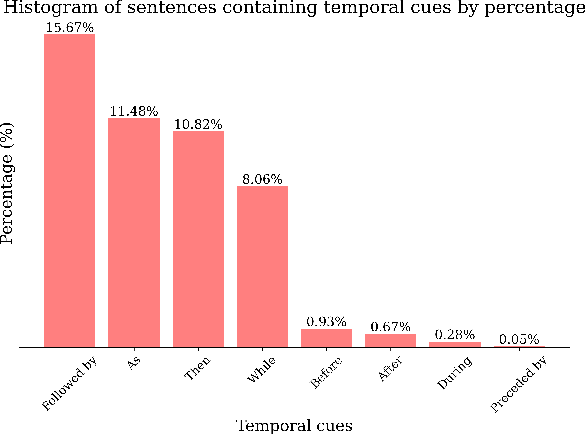
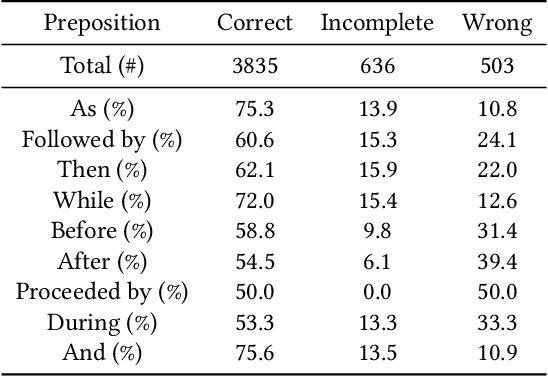
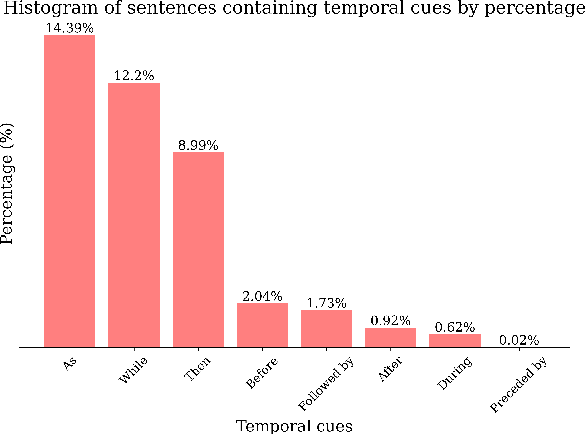
Recent advancements in machine learning have fueled research on multimodal tasks, such as for instance text-to-video and text-to-audio retrieval. These tasks require models to understand the semantic content of video and audio data, including objects, and characters. The models also need to learn spatial arrangements and temporal relationships. In this work, we analyse the temporal ordering of sounds, which is an understudied problem in the context of text-to-audio retrieval. In particular, we dissect the temporal understanding capabilities of a state-of-the-art model for text-to-audio retrieval on the AudioCaps and Clotho datasets. Additionally, we introduce a synthetic text-audio dataset that provides a controlled setting for evaluating temporal capabilities of recent models. Lastly, we present a loss function that encourages text-audio models to focus on the temporal ordering of events. Code and data are available at https://www.robots.ox.ac.uk/~vgg/research/audio-retrieval/dtu/.