 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Scaling with Diffusion Language Models via Reward-Guided Stitching
Feb 26, 2026Reasoning with large language models often benefits from generating multiple chains-of-thought, but existing aggregation strategies are typically trajectory-level (e.g., selecting the best trace or voting on the final answer), discarding useful intermediate work from partial or "nearly correct" attempts. We propose Stitching Noisy Diffusion Thoughts, a self-consistency framework that turns cheap diffusion-sampled reasoning into a reusable pool of step-level candidates. Given a problem, we (i) sample many diverse, low-cost reasoning trajectories using a masked diffusion language model, (ii) score every intermediate step with an off-the-shelf process reward model (PRM), and (iii) stitch these highest-quality steps across trajectories into a composite rationale. This rationale then conditions an autoregressive (AR) model (solver) to recompute only the final answer. This modular pipeline separates exploration (diffusion) from evaluation and solution synthesis, avoiding monolithic unified hybrids while preserving broad search. Across math reasoning benchmarks, we find that step-level recombination is most beneficial on harder problems, and ablations highlight the importance of the final AR solver in converting stitched but imperfect rationales into accurate answers. Using low-confidence diffusion sampling with parallel, independent rollouts, our training-free framework improves average accuracy by up to 23.8% across six math and coding tasks. At the same time, it achieves up to a 1.8x latency reduction relative to both traditional diffusion models (e.g., Dream, LLaDA) and unified architectures (e.g., TiDAR). Code is available at https://github.com/roymiles/diffusion-stitching.
A Benchmark for Deep Information Synthesis
Feb 24, 2026Large language model (LLM)-based agents are increasingly used to solve complex tasks involving tool use, such as web browsing, code execution, and data analysis. However, current evaluation benchmarks do not adequately assess their ability to solve real-world tasks that require synthesizing information from multiple sources and inferring insights beyond simple fact retrieval. To address this, we introduce DEEPSYNTH, a novel benchmark designed to evaluate agents on realistic, time-consuming problems that combine information gathering, synthesis, and structured reasoning to produce insights. DEEPSYNTH contains 120 tasks collected across 7 domains and data sources covering 67 countries. DEEPSYNTH is constructed using a multi-stage data collection pipeline that requires annotators to collect official data sources, create hypotheses, perform manual analysis, and design tasks with verifiable answers. When evaluated on DEEPSYNTH, 11 state-of-the-art LLMs and deep research agents achieve a maximum F1 score of 8.97 and 17.5 on the LLM-judge metric, underscoring the difficulty of the benchmark. Our analysis reveals that current agents struggle with hallucinations and reasoning over large information spaces, highlighting DEEPSYNTH as a crucial benchmark for guiding future research.
SATGround: A Spatially-Aware Approach for Visual Grounding in Remote Sensing
Dec 09, 2025Vision-language models (VLMs) are emerging as powerful generalist tools for remote sensing, capable of integrating information across diverse tasks and enabling flexible, instruction-based interactions via a chat interface. In this work, we enhance VLM-based visual grounding in satellite imagery by proposing a novel structured localization mechanism. Our approach involves finetuning a pretrained VLM on a diverse set of instruction-following tasks, while interfacing a dedicated grounding module through specialized control tokens for localization. This method facilitates joint reasoning over both language and spatial information, significantly enhancing the model's ability to precisely localize objects in complex satellite scenes. We evaluate our framework on several remote sensing benchmarks, consistently improving the state-of-the-art, including a 24.8% relative improvement over previous methods on visual grounding. Our results highlight the benefits of integrating structured spatial reasoning into VLMs, paving the way for more reliable real-world satellite data analysis.
Dissecting Temporal Understanding in Text-to-Audio Retrieval
Sep 01, 2024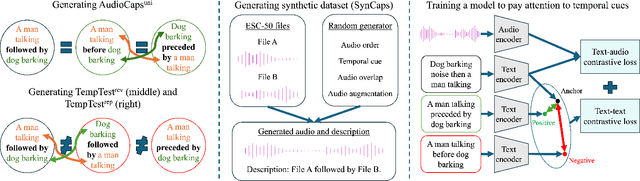
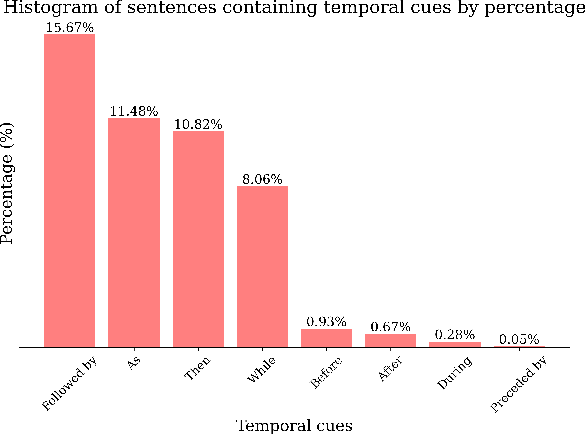
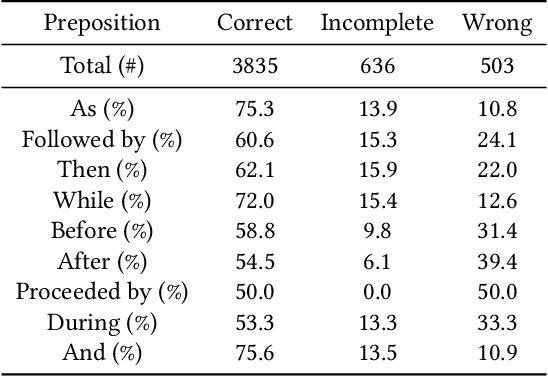
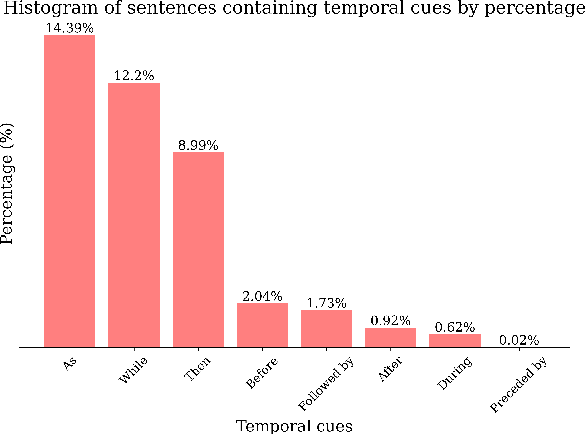
Recent advancements in machine learning have fueled research on multimodal tasks, such as for instance text-to-video and text-to-audio retrieval. These tasks require models to understand the semantic content of video and audio data, including objects, and characters. The models also need to learn spatial arrangements and temporal relationships. In this work, we analyse the temporal ordering of sounds, which is an understudied problem in the context of text-to-audio retrieval. In particular, we dissect the temporal understanding capabilities of a state-of-the-art model for text-to-audio retrieval on the AudioCaps and Clotho datasets. Additionally, we introduce a synthetic text-audio dataset that provides a controlled setting for evaluating temporal capabilities of recent models. Lastly, we present a loss function that encourages text-audio models to focus on the temporal ordering of events. Code and data are available at https://www.robots.ox.ac.uk/~vgg/research/audio-retrieval/dtu/.
A SOUND APPROACH: Using Large Language Models to generate audio descriptions for egocentric text-audio retrieval
Feb 29, 2024Video databases from the internet are a valuable source of text-audio retrieval datasets. However, given that sound and vision streams represent different "views" of the data, treating visual descriptions as audio descriptions is far from optimal. Even if audio class labels are present, they commonly are not very detailed, making them unsuited for text-audio retrieval. To exploit relevant audio information from video-text datasets, we introduce a methodology for generating audio-centric descriptions using Large Language Models (LLMs). In this work, we consider the egocentric video setting and propose three new text-audio retrieval benchmarks based on the EpicMIR and EgoMCQ tasks, and on the EpicSounds dataset. Our approach for obtaining audio-centric descriptions gives significantly higher zero-shot performance than using the original visual-centric descriptions. Furthermore, we show that using the same prompts, we can successfully employ LLMs to improve the retrieval on EpicSounds, compared to using the original audio class labels of the dataset. Finally, we confirm that LLMs can be used to determine the difficulty of identifying the action associated with a sound.
Audio Retrieval with Natural Language Queries: A Benchmark Study
Dec 17, 2021



The objectives of this work are cross-modal text-audio and audio-text retrieval, in which the goal is to retrieve the audio content from a pool of candidates that best matches a given written description and vice versa. Text-audio retrieval enables users to search large databases through an intuitive interface: they simply issue free-form natural language descriptions of the sound they would like to hear. To study the tasks of text-audio and audio-text retrieval, which have received limited attention in the existing literature, we introduce three challenging new benchmarks. We first construct text-audio and audio-text retrieval benchmarks from the AudioCaps and Clotho audio captioning datasets. Additionally, we introduce the SoundDescs benchmark, which consists of paired audio and natural language descriptions for a diverse collection of sounds that are complementary to those found in AudioCaps and Clotho. We employ these three benchmarks to establish baselines for cross-modal text-audio and audio-text retrieval, where we demonstrate the benefits of pre-training on diverse audio tasks. We hope that our benchmarks will inspire further research into audio retrieval with free-form text queries. Code, audio features for all datasets used, and the \datasetName dataset will be made publicly available.
Audio Retrieval with Natural Language Queries
May 05, 2021

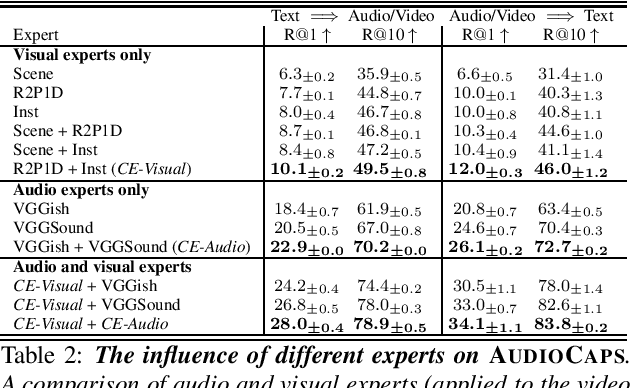
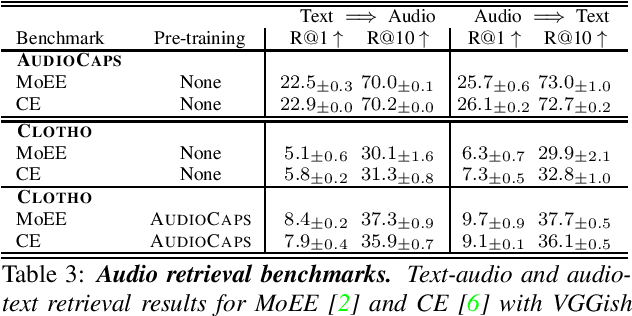
We consider the task of retrieving audio using free-form natural language queries. To study this problem, which has received limited attention in the existing literature, we introduce challenging new benchmarks for text-based audio retrieval using text annotations sourced from the Audiocaps and Clotho datasets. We then employ these benchmarks to establish baselines for cross-modal audio retrieval, where we demonstrate the benefits of pre-training on diverse audio tasks. We hope that our benchmarks will inspire further research into cross-modal text-based audio retrieval with free-form text queries.
QuerYD: A video dataset with high-quality textual and audio narrations
Nov 22, 2020
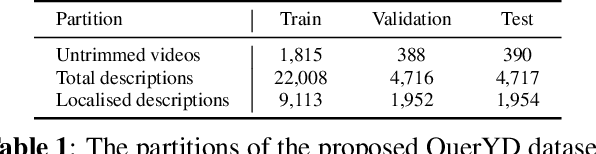


We introduce QuerYD, a new large-scale dataset for retrieval and event localisation in video. A unique feature of our dataset is the availability of two audio tracks for each video: the original audio, and a high-quality spoken description of the visual content. The dataset is based on YouDescribe, a volunteer project that assists visually-impaired people by attaching voiced narrations to existing YouTube videos. This ever-growing collection of videos contains highly detailed, temporally aligned audio and text annotations. The content descriptions are more relevant than dialogue, and more detailed than previous description attempts, which can be observed to contain many superficial or uninformative descriptions. To demonstrate the utility of the QuerYD dataset, we show that it can be used to train and benchmark strong models for retrieval and event localisation. All data, code and models will be made available, and we hope that QuerYD inspires further research on video understanding with written and spoken natural language.