 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoCVR: An Egocentric Benchmark for Fine-Grained Composed Video Retrieval
Jul 23, 2024In Composed Video Retrieval, a video and a textual description which modifies the video content are provided as inputs to the model. The aim is to retrieve the relevant video with the modified content from a database of videos. In this challenging task, the first step is to acquire large-scale training datasets and collect high-quality benchmarks for evaluation. In this work, we introduce EgoCVR, a new evaluation benchmark for fine-grained Composed Video Retrieval using large-scale egocentric video datasets. EgoCVR consists of 2,295 queries that specifically focus on high-quality temporal video understanding. We find that existing Composed Video Retrieval frameworks do not achieve the necessary high-quality temporal video understanding for this task. To address this shortcoming, we adapt a simple training-free method, propose a generic re-ranking framework for Composed Video Retrieval, and demonstrate that this achieves strong results on EgoCVR. Our code and benchmark are freely available at https://github.com/ExplainableML/EgoCVR.
Video-adverb retrieval with compositional adverb-action embeddings
Sep 26, 2023Retrieving adverbs that describe an action in a video poses a crucial step towards fine-grained video understanding. We propose a framework for video-to-adverb retrieval (and vice versa) that aligns video embeddings with their matching compositional adverb-action text embedding in a joint embedding space. The compositional adverb-action text embedding is learned using a residual gating mechanism, along with a novel training objective consisting of triplet losses and a regression target. Our method achieves state-of-the-art performance on five recent benchmarks for video-adverb retrieval. Furthermore, we introduce dataset splits to benchmark video-adverb retrieval for unseen adverb-action compositions on subsets of the MSR-VTT Adverbs and ActivityNet Adverbs datasets. Our proposed framework outperforms all prior works for the generalisation task of retrieving adverbs from videos for unseen adverb-action compositions. Code and dataset splits are available at https://hummelth.github.io/ReGaDa/.
Text-to-feature diffusion for audio-visual few-shot learning
Sep 07, 2023
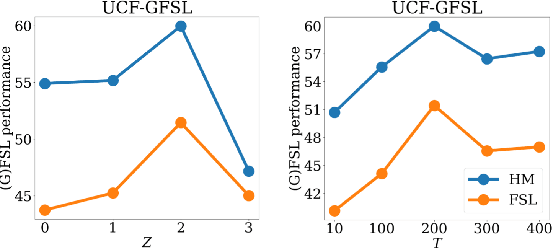
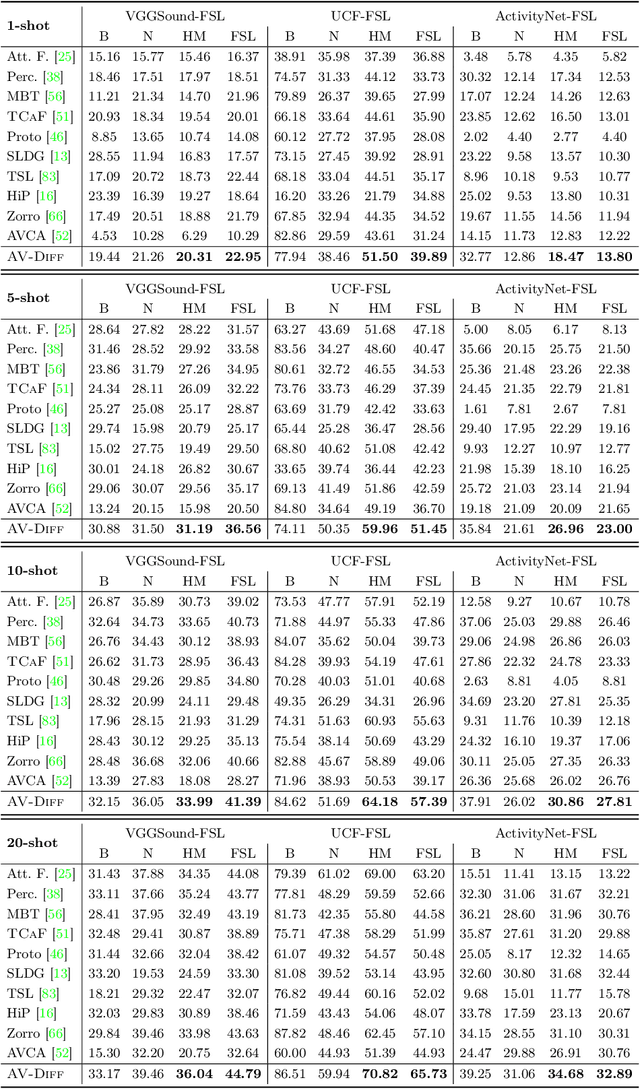
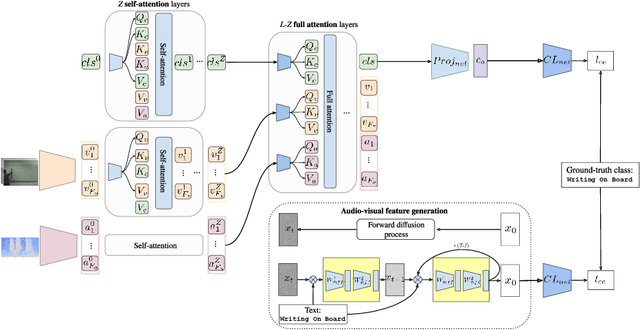
Training deep learning models for video classification from audio-visual data commonly requires immense amounts of labeled training data collected via a costly process. A challenging and underexplored, yet much cheaper, setup is few-shot learning from video data. In particular, the inherently multi-modal nature of video data with sound and visual information has not been leveraged extensively for the few-shot video classification task. Therefore, we introduce a unified audio-visual few-shot video classification benchmark on three datasets, i.e. the VGGSound-FSL, UCF-FSL, ActivityNet-FSL datasets, where we adapt and compare ten methods. In addition, we propose AV-DIFF, a text-to-feature diffusion framework, which first fuses the temporal and audio-visual features via cross-modal attention and then generates multi-modal features for the novel classes. We show that AV-DIFF obtains state-of-the-art performance on our proposed benchmark for audio-visual (generalised) few-shot learning. Our benchmark paves the way for effective audio-visual classification when only limited labeled data is available. Code and data are available at https://github.com/ExplainableML/AVDIFF-GFSL.
Semantic Image Synthesis with Semantically Coupled VQ-Model
Sep 06, 2022



Semantic image synthesis enables control over unconditional image generation by allowing guidance on what is being generated. We conditionally synthesize the latent space from a vector quantized model (VQ-model) pre-trained to autoencode images. Instead of training an autoregressive Transformer on separately learned conditioning latents and image latents, we find that jointly learning the conditioning and image latents significantly improves the modeling capabilities of the Transformer model. While our jointly trained VQ-model achieves a similar reconstruction performance to a vanilla VQ-model for both semantic and image latents, tying the two modalities at the autoencoding stage proves to be an important ingredient to improve autoregressive modeling performance. We show that our model improves semantic image synthesis using autoregressive models on popular semantic image datasets ADE20k, Cityscapes and COCO-Stuff.
Temporal and cross-modal attention for audio-visual zero-shot learning
Jul 20, 2022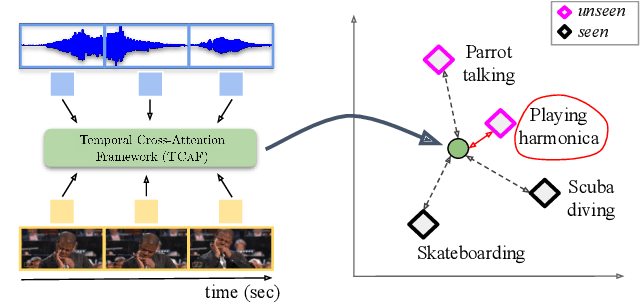
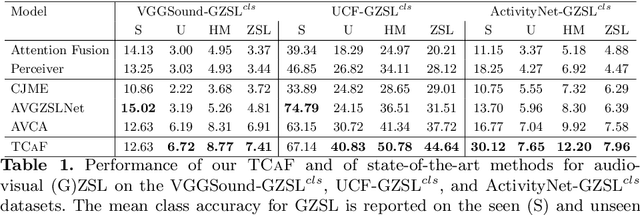


Audio-visual generalised zero-shot learning for video classification requires understanding the relations between the audio and visual information in order to be able to recognise samples from novel, previously unseen classes at test time. The natural semantic and temporal alignment between audio and visual data in video data can be exploited to learn powerful representations that generalise to unseen classes at test time. We propose a multi-modal and Temporal Cross-attention Framework (\modelName) for audio-visual generalised zero-shot learning. Its inputs are temporally aligned audio and visual features that are obtained from pre-trained networks. Encouraging the framework to focus on cross-modal correspondence across time instead of self-attention within the modalities boosts the performance significantly. We show that our proposed framework that ingests temporal features yields state-of-the-art performance on the \ucf, \vgg, and \activity benchmarks for (generalised) zero-shot learning. Code for reproducing all results is available at \url{https://github.com/ExplainableML/TCAF-GZSL}.
Where and When: Space-Time Attention for Audio-Visual Explanations
May 04, 2021
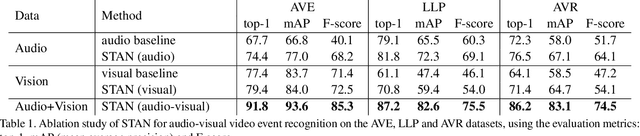
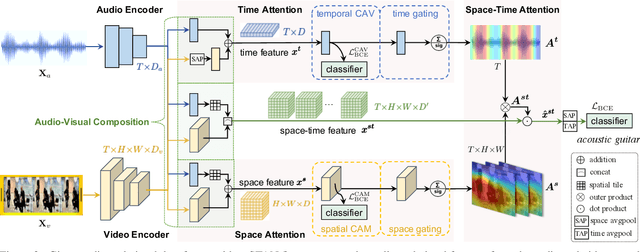

Explaining the decision of a multi-modal decision-maker requires to determine the evidence from both modalities. Recent advances in XAI provide explanations for models trained on still images. However, when it comes to modeling multiple sensory modalities in a dynamic world, it remains underexplored how to demystify the mysterious dynamics of a complex multi-modal model. In this work, we take a crucial step forward and explore learnable explanations for audio-visual recognition. Specifically, we propose a novel space-time attention network that uncovers the synergistic dynamics of audio and visual data over both space and time. Our model is capable of predicting the audio-visual video events, while justifying its decision by localizing where the relevant visual cues appear, and when the predicted sounds occur in videos. We benchmark our model on three audio-visual video event datasets, comparing extensively to multiple recent multi-modal representation learners and intrinsic explanation models. Experimental results demonstrate the clear superior performance of our model over the existing methods on audio-visual video event recognition. Moreover, we conduct an in-depth study to analyze the explainability of our model based on robustness analysis via perturbation tests and pointing games using human annotations.
Crossmodal Language Grounding in an Embodied Neurocognitive Model
Jun 24, 2020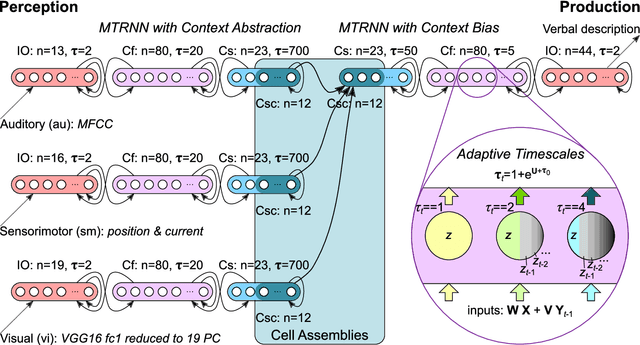

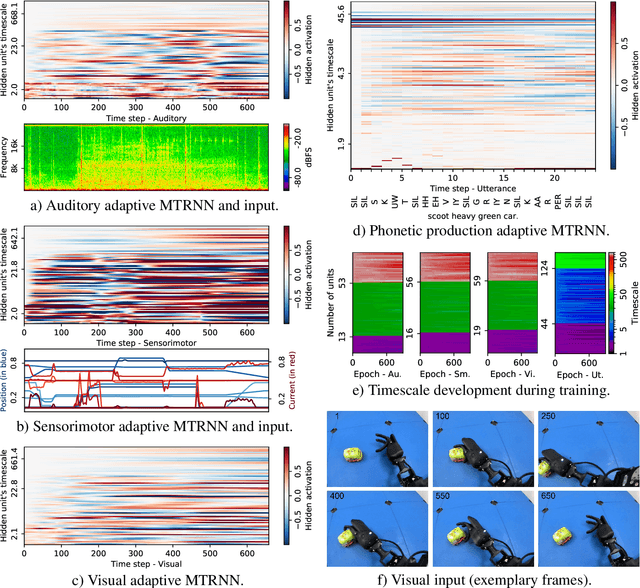
Human infants are able to acquire natural language seemingly easily at an early age. Their language learning seems to occur simultaneously with learning other cognitive functions as well as with playful interactions with the environment and caregivers. From a neuroscientific perspective, natural language is embodied, grounded in most, if not all, sensory and sensorimotor modalities, and acquired by means of crossmodal integration. However, characterising the underlying mechanisms in the brain is difficult and explaining the grounding of language in crossmodal perception and action remains challenging. In this paper, we present a neurocognitive model for language grounding which reflects bio-inspired mechanisms such as an implicit adaptation of timescales as well as end-to-end multimodal abstraction. It addresses developmental robotic interaction and extends its learning capabilities using larger-scale knowledge-based data. In our scenario, we utilise the humanoid robot NICO in obtaining the EMIL data collection, in which the cognitive robot interacts with objects in a children's playground environment while receiving linguistic labels from a caregiver. The model analysis shows that crossmodally integrated representations are sufficient for acquiring language merely from sensory input through interaction with objects in an environment. The representations self-organise hierarchically and embed temporal and spatial information through composition and decomposition. This model can also provide the basis for further crossmodal integration of perceptually grounded cognitive representations.