 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models
May 12, 2025Current diffusion-based text-to-video methods are limited to producing short video clips of a single shot and lack the capability to generate multi-shot videos with discrete transitions where the same character performs distinct activities across the same or different backgrounds. To address this limitation we propose a framework that includes a dataset collection pipeline and architectural extensions to video diffusion models to enable text-to-multi-shot video generation. Our approach enables generation of multi-shot videos as a single video with full attention across all frames of all shots, ensuring character and background consistency, and allows users to control the number, duration, and content of shots through shot-specific conditioning. This is achieved by incorporating a transition token into the text-to-video model to control at which frames a new shot begins and a local attention masking strategy which controls the transition token's effect and allows shot-specific prompting. To obtain training data we propose a novel data collection pipeline to construct a multi-shot video dataset from existing single-shot video datasets. Extensive experiments demonstrate that fine-tuning a pre-trained text-to-video model for a few thousand iterations is enough for the model to subsequently be able to generate multi-shot videos with shot-specific control, outperforming the baselines. You can find more details in https://shotadapter.github.io/
SNED: Superposition Network Architecture Search for Efficient Video Diffusion Model
May 31, 2024



While AI-generated content has garnered significant attention, achieving photo-realistic video synthesis remains a formidable challenge. Despite the promising advances in diffusion models for video generation quality, the complex model architecture and substantial computational demands for both training and inference create a significant gap between these models and real-world applications. This paper presents SNED, a superposition network architecture search method for efficient video diffusion model. Our method employs a supernet training paradigm that targets various model cost and resolution options using a weight-sharing method. Moreover, we propose the supernet training sampling warm-up for fast training optimization. To showcase the flexibility of our method, we conduct experiments involving both pixel-space and latent-space video diffusion models. The results demonstrate that our framework consistently produces comparable results across different model options with high efficiency. According to the experiment for the pixel-space video diffusion model, we can achieve consistent video generation results simultaneously across 64 x 64 to 256 x 256 resolutions with a large range of model sizes from 640M to 1.6B number of parameters for pixel-space video diffusion models.
Personalized Residuals for Concept-Driven Text-to-Image Generation
May 21, 2024
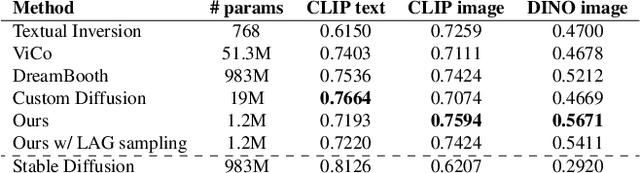
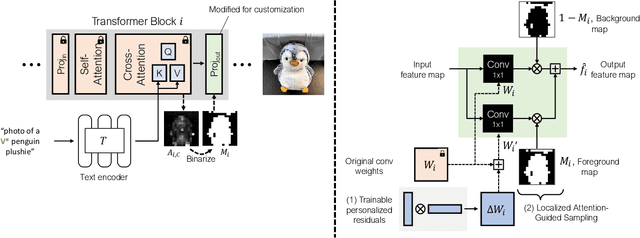
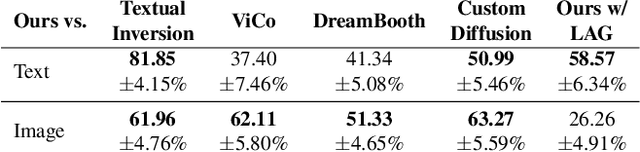
We present personalized residuals and localized attention-guided sampling for efficient concept-driven generation using text-to-image diffusion models. Our method first represents concepts by freezing the weights of a pretrained text-conditioned diffusion model and learning low-rank residuals for a small subset of the model's layers. The residual-based approach then directly enables application of our proposed sampling technique, which applies the learned residuals only in areas where the concept is localized via cross-attention and applies the original diffusion weights in all other regions. Localized sampling therefore combines the learned identity of the concept with the existing generative prior of the underlying diffusion model. We show that personalized residuals effectively capture the identity of a concept in ~3 minutes on a single GPU without the use of regularization images and with fewer parameters than previous models, and localized sampling allows using the original model as strong prior for large parts of the image.
Modulating Pretrained Diffusion Models for Multimodal Image Synthesis
Feb 24, 2023
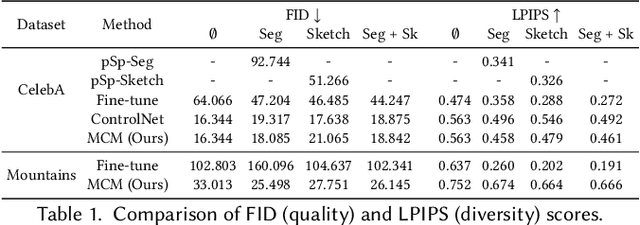


We present multimodal conditioning modules (MCM) for enabling conditional image synthesis using pretrained diffusion models. Previous multimodal synthesis works rely on training networks from scratch or fine-tuning pretrained networks, both of which are computationally expensive for large, state-of-the-art diffusion models. Our method uses pretrained networks but does not require any updates to the diffusion network's parameters. MCM is a small module trained to modulate the diffusion network's predictions during sampling using 2D modalities (e.g., semantic segmentation maps, sketches) that were unseen during the original training of the diffusion model. We show that MCM enables user control over the spatial layout of the image and leads to increased control over the image generation process. Training MCM is cheap as it does not require gradients from the original diffusion net, consists of only $\sim$1$\%$ of the number of parameters of the base diffusion model, and is trained using only a limited number of training examples. We evaluate our method on unconditional and text-conditional models to demonstrate the improved control over the generated images and their alignment with respect to the conditioning inputs.
SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model
Dec 09, 2022



Generic image inpainting aims to complete a corrupted image by borrowing surrounding information, which barely generates novel content. By contrast, multi-modal inpainting provides more flexible and useful controls on the inpainted content, \eg, a text prompt can be used to describe an object with richer attributes, and a mask can be used to constrain the shape of the inpainted object rather than being only considered as a missing area. We propose a new diffusion-based model named SmartBrush for completing a missing region with an object using both text and shape-guidance. While previous work such as DALLE-2 and Stable Diffusion can do text-guided inapinting they do not support shape guidance and tend to modify background texture surrounding the generated object. Our model incorporates both text and shape guidance with precision control. To preserve the background better, we propose a novel training and sampling strategy by augmenting the diffusion U-net with object-mask prediction. Lastly, we introduce a multi-task training strategy by jointly training inpainting with text-to-image generation to leverage more training data. We conduct extensive experiments showing that our model outperforms all baselines in terms of visual quality, mask controllability, and background preservation.
ASSET: Autoregressive Semantic Scene Editing with Transformers at High Resolutions
May 24, 2022
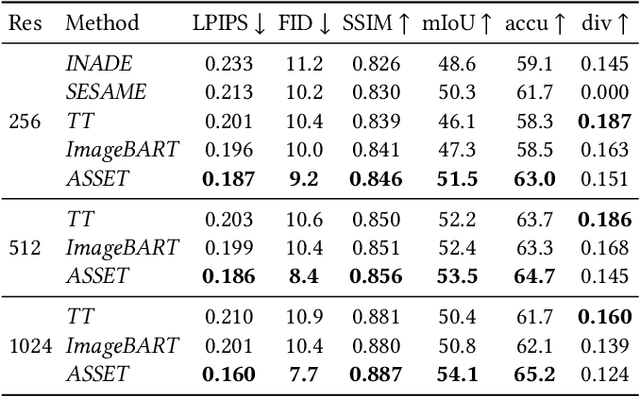
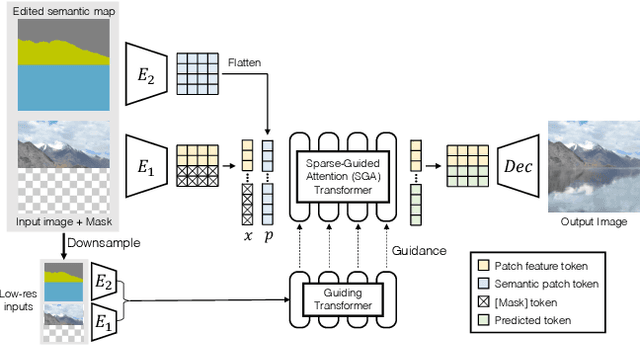
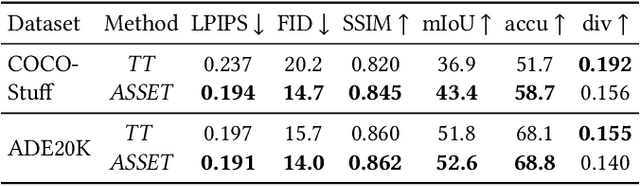
We present ASSET, a neural architecture for automatically modifying an input high-resolution image according to a user's edits on its semantic segmentation map. Our architecture is based on a transformer with a novel attention mechanism. Our key idea is to sparsify the transformer's attention matrix at high resolutions, guided by dense attention extracted at lower image resolutions. While previous attention mechanisms are computationally too expensive for handling high-resolution images or are overly constrained within specific image regions hampering long-range interactions, our novel attention mechanism is both computationally efficient and effective. Our sparsified attention mechanism is able to capture long-range interactions and context, leading to synthesizing interesting phenomena in scenes, such as reflections of landscapes onto water or flora consistent with the rest of the landscape, that were not possible to generate reliably with previous convnets and transformer approaches. We present qualitative and quantitative results, along with user studies, demonstrating the effectiveness of our method.
CharacterGAN: Few-Shot Keypoint Character Animation and Reposing
Feb 05, 2021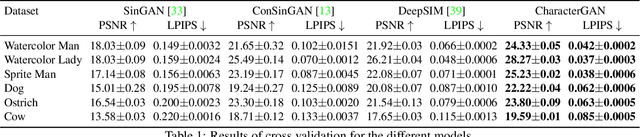
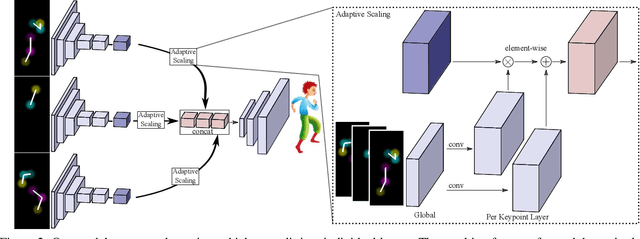
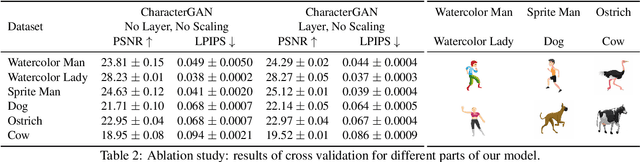

We introduce CharacterGAN, a generative model that can be trained on only a few samples (8 - 15) of a given character. Our model generates novel poses based on keypoint locations, which can be modified in real time while providing interactive feedback, allowing for intuitive reposing and animation. Since we only have very limited training samples, one of the key challenges lies in how to address (dis)occlusions, e.g. when a hand moves behind or in front of a body. To address this, we introduce a novel layering approach which explicitly splits the input keypoints into different layers which are processed independently. These layers represent different parts of the character and provide a strong implicit bias that helps to obtain realistic results even with strong (dis)occlusions. To combine the features of individual layers we use an adaptive scaling approach conditioned on all keypoints. Finally, we introduce a mask connectivity constraint to reduce distortion artifacts that occur with extreme out-of-distribution poses at test time. We show that our approach outperforms recent baselines and creates realistic animations for diverse characters. We also show that our model can handle discrete state changes, for example a profile facing left or right, that the different layers do indeed learn features specific for the respective keypoints in those layers, and that our model scales to larger datasets when more data is available.
Adversarial Text-to-Image Synthesis: A Review
Jan 25, 2021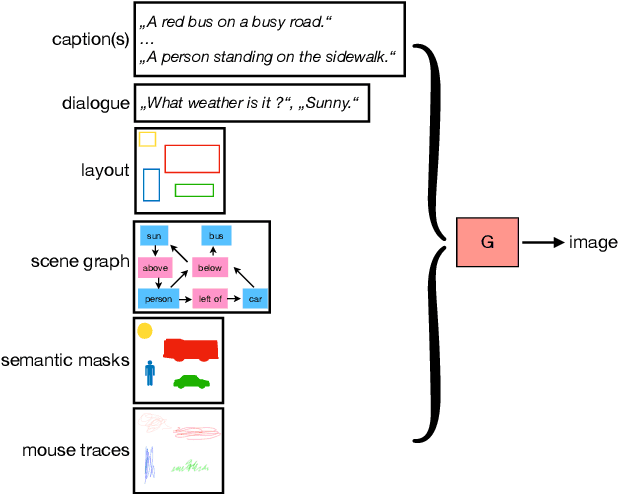
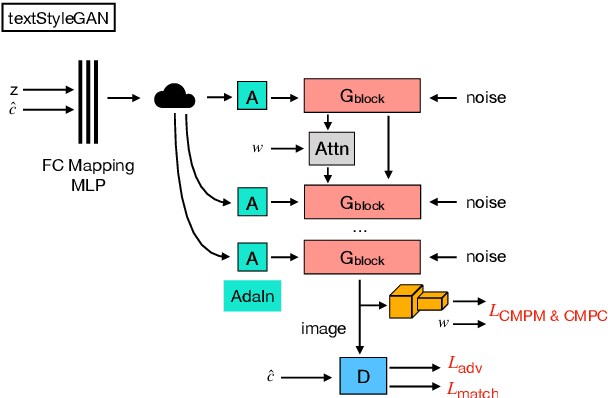

With the advent of generative adversarial networks, synthesizing images from textual descriptions has recently become an active research area. It is a flexible and intuitive way for conditional image generation with significant progress in the last years regarding visual realism, diversity, and semantic alignment. However, the field still faces several challenges that require further research efforts such as enabling the generation of high-resolution images with multiple objects, and developing suitable and reliable evaluation metrics that correlate with human judgement. In this review, we contextualize the state of the art of adversarial text-to-image synthesis models, their development since their inception five years ago, and propose a taxonomy based on the level of supervision. We critically examine current strategies to evaluate text-to-image synthesis models, highlight shortcomings, and identify new areas of research, ranging from the development of better datasets and evaluation metrics to possible improvements in architectural design and model training. This review complements previous surveys on generative adversarial networks with a focus on text-to-image synthesis which we believe will help researchers to further advance the field.
Crossmodal Language Grounding in an Embodied Neurocognitive Model
Jun 24, 2020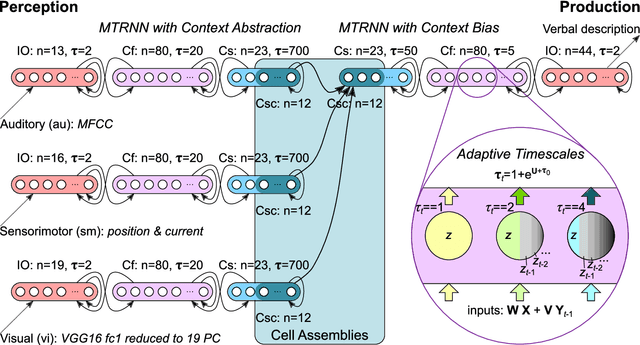

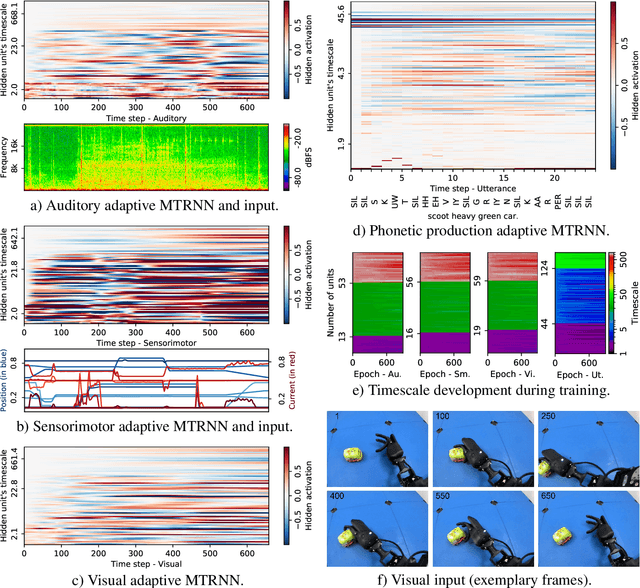
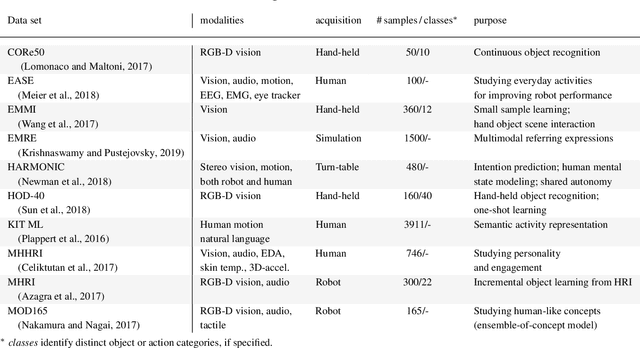
Human infants are able to acquire natural language seemingly easily at an early age. Their language learning seems to occur simultaneously with learning other cognitive functions as well as with playful interactions with the environment and caregivers. From a neuroscientific perspective, natural language is embodied, grounded in most, if not all, sensory and sensorimotor modalities, and acquired by means of crossmodal integration. However, characterising the underlying mechanisms in the brain is difficult and explaining the grounding of language in crossmodal perception and action remains challenging. In this paper, we present a neurocognitive model for language grounding which reflects bio-inspired mechanisms such as an implicit adaptation of timescales as well as end-to-end multimodal abstraction. It addresses developmental robotic interaction and extends its learning capabilities using larger-scale knowledge-based data. In our scenario, we utilise the humanoid robot NICO in obtaining the EMIL data collection, in which the cognitive robot interacts with objects in a children's playground environment while receiving linguistic labels from a caregiver. The model analysis shows that crossmodally integrated representations are sufficient for acquiring language merely from sensory input through interaction with objects in an environment. The representations self-organise hierarchically and embed temporal and spatial information through composition and decomposition. This model can also provide the basis for further crossmodal integration of perceptually grounded cognitive representations.
Improved Techniques for Training Single-Image GANs
Mar 25, 2020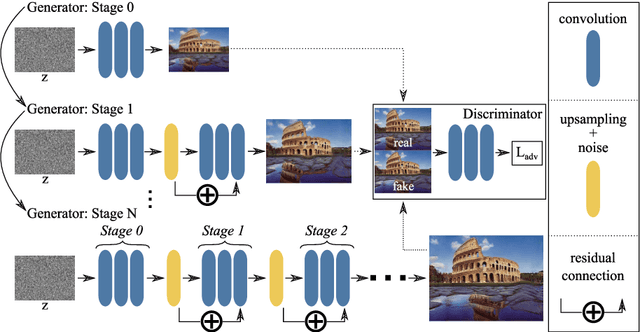



Recently there has been an interest in the potential of learning generative models from a single image, as opposed to from a large dataset. This task is of practical significance, as it means that generative models can be used in domains where collecting a large dataset is not feasible. However, training a model capable of generating realistic images from only a single sample is a difficult problem. In this work, we conduct a number of experiments to understand the challenges of training these methods and propose some best practices that we found allowed us to generate improved results over previous work in this space. One key piece is that unlike prior single image generation methods, we concurrently train several stages in a sequential multi-stage manner, allowing us to learn models with fewer stages of increasing image resolution. Compared to a recent state of the art baseline, our model is up to six times faster to train, has fewer parameters, and can better capture the global structure of images.