 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Natural Language Biases with Prompt-based Learning
Sep 11, 2023



In this project, we want to explore the newly emerging field of prompt engineering and apply it to the downstream task of detecting LM biases. More concretely, we explore how to design prompts that can indicate 4 different types of biases: (1) gender, (2) race, (3) sexual orientation, and (4) religion-based. Within our project, we experiment with different manually crafted prompts that can draw out the subtle biases that may be present in the language model. We apply these prompts to multiple variations of popular and well-recognized models: BERT, RoBERTa, and T5 to evaluate their biases. We provide a comparative analysis of these models and assess them using a two-fold method: use human judgment to decide whether model predictions are biased and utilize model-level judgment (through further prompts) to understand if a model can self-diagnose the biases of its own prediction.
CancerGPT: Few-shot Drug Pair Synergy Prediction using Large Pre-trained Language Models
Apr 18, 2023Large pre-trained language models (LLMs) have been shown to have significant potential in few-shot learning across various fields, even with minimal training data. However, their ability to generalize to unseen tasks in more complex fields, such as biology, has yet to be fully evaluated. LLMs can offer a promising alternative approach for biological inference, particularly in cases where structured data and sample size are limited, by extracting prior knowledge from text corpora. Our proposed few-shot learning approach uses LLMs to predict the synergy of drug pairs in rare tissues that lack structured data and features. Our experiments, which involved seven rare tissues from different cancer types, demonstrated that the LLM-based prediction model achieved significant accuracy with very few or zero samples. Our proposed model, the CancerGPT (with $\sim$ 124M parameters), was even comparable to the larger fine-tuned GPT-3 model (with $\sim$ 175B parameters). Our research is the first to tackle drug pair synergy prediction in rare tissues with limited data. We are also the first to utilize an LLM-based prediction model for biological reaction prediction tasks.
ASSET: Autoregressive Semantic Scene Editing with Transformers at High Resolutions
May 24, 2022
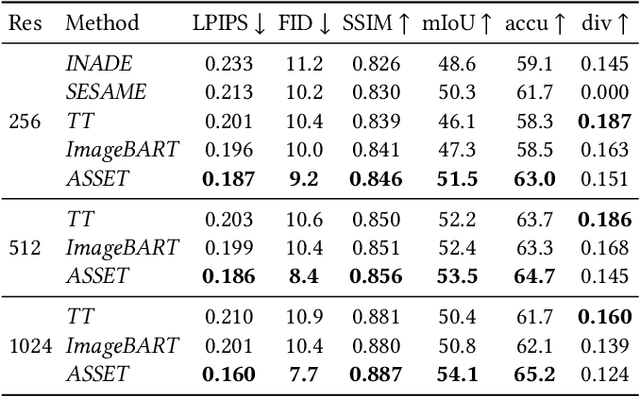
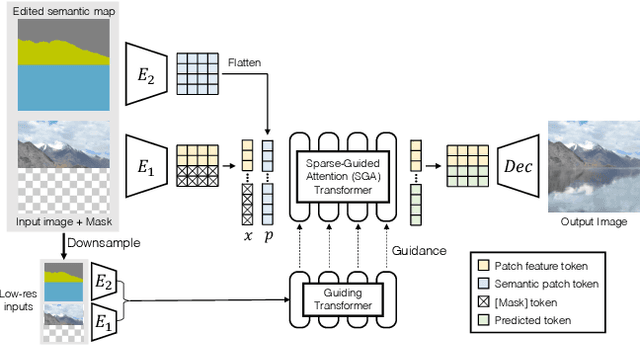
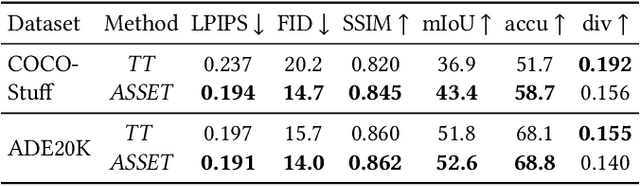
We present ASSET, a neural architecture for automatically modifying an input high-resolution image according to a user's edits on its semantic segmentation map. Our architecture is based on a transformer with a novel attention mechanism. Our key idea is to sparsify the transformer's attention matrix at high resolutions, guided by dense attention extracted at lower image resolutions. While previous attention mechanisms are computationally too expensive for handling high-resolution images or are overly constrained within specific image regions hampering long-range interactions, our novel attention mechanism is both computationally efficient and effective. Our sparsified attention mechanism is able to capture long-range interactions and context, leading to synthesizing interesting phenomena in scenes, such as reflections of landscapes onto water or flora consistent with the rest of the landscape, that were not possible to generate reliably with previous convnets and transformer approaches. We present qualitative and quantitative results, along with user studies, demonstrating the effectiveness of our method.