 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Me, I'm an Expert: Decoding and Steering Authority Bias in Large Language Models
Jan 19, 2026Prior research demonstrates that performance of language models on reasoning tasks can be influenced by suggestions, hints and endorsements. However, the influence of endorsement source credibility remains underexplored. We investigate whether language models exhibit systematic bias based on the perceived expertise of the provider of the endorsement. Across 4 datasets spanning mathematical, legal, and medical reasoning, we evaluate 11 models using personas representing four expertise levels per domain. Our results reveal that models are increasingly susceptible to incorrect/misleading endorsements as source expertise increases, with higher-authority sources inducing not only accuracy degradation but also increased confidence in wrong answers. We also show that this authority bias is mechanistically encoded within the model and a model can be steered away from the bias, thereby improving its performance even when an expert gives a misleading endorsement.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Detecting Natural Language Biases with Prompt-based Learning
Sep 11, 2023



In this project, we want to explore the newly emerging field of prompt engineering and apply it to the downstream task of detecting LM biases. More concretely, we explore how to design prompts that can indicate 4 different types of biases: (1) gender, (2) race, (3) sexual orientation, and (4) religion-based. Within our project, we experiment with different manually crafted prompts that can draw out the subtle biases that may be present in the language model. We apply these prompts to multiple variations of popular and well-recognized models: BERT, RoBERTa, and T5 to evaluate their biases. We provide a comparative analysis of these models and assess them using a two-fold method: use human judgment to decide whether model predictions are biased and utilize model-level judgment (through further prompts) to understand if a model can self-diagnose the biases of its own prediction.
WiSleep: Scalable Sleep Monitoring and Analytics Using Passive WiFi Sensing
Feb 07, 2021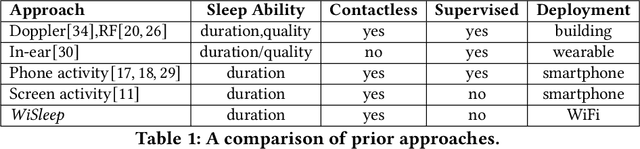
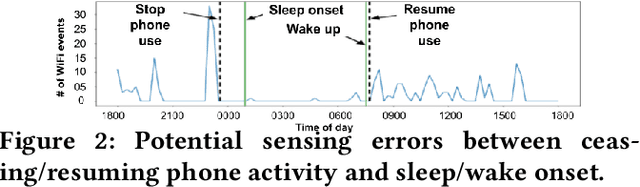

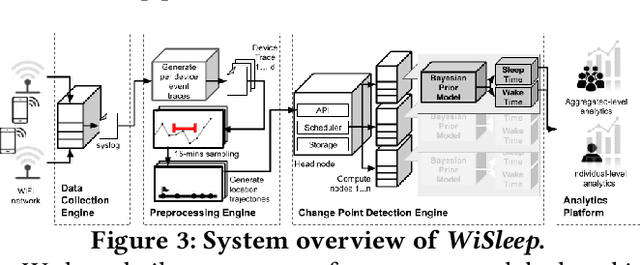
Sleep deprivation is a public health concern that significantly impacts one's well-being and performance. Sleep is an intimate experience, and state-of-the-art sleep monitoring solutions are highly-personalized to individual users. With a motivation to expand sleep monitoring at a large-scale and contribute sleep data to public health understanding, we present WiSleep, a sleep monitoring and analytics platform using smartphone network connections that are passively sensed from WiFi infrastructure. We propose an unsupervised ensemble model of Bayesian change point detection to predict sleep and wake-up times. Then, we validate our approach using ground truth from a user study in campus dormitories and a private home. Our results find WiSleep outperforming established methods for users with irregular sleep patterns while yielding comparable accuracy for regular sleepers with an average 79.5\% accuracy. This is comparable to client-side based methods, albeit utilizing only coarse-grained information. Finally, we show that WiSleep can process data from 20,000 users on a single commodity server, allowing it to scale to large campus populations with low server requirements.
Federated Learning: Opportunities and Challenges
Jan 14, 2021

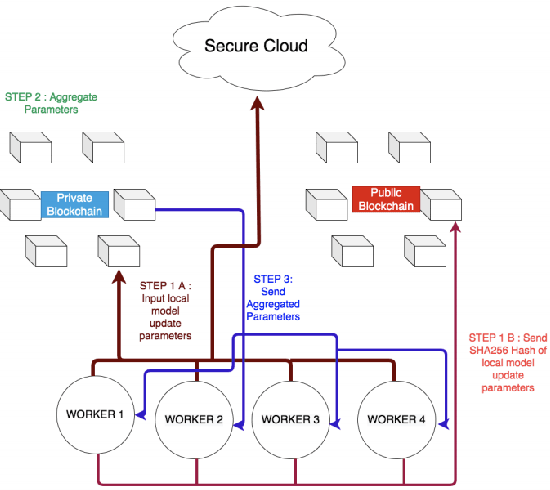
Federated Learning (FL) is a concept first introduced by Google in 2016, in which multiple devices collaboratively learn a machine learning model without sharing their private data under the supervision of a central server. This offers ample opportunities in critical domains such as healthcare, finance etc, where it is risky to share private user information to other organisations or devices. While FL appears to be a promising Machine Learning (ML) technique to keep the local data private, it is also vulnerable to attacks like other ML models. Given the growing interest in the FL domain, this report discusses the opportunities and challenges in federated learning.
Explainable AI: Deep Reinforcement Learning Agents for Residential Demand Side Cost Savings in Smart Grids
Oct 30, 2019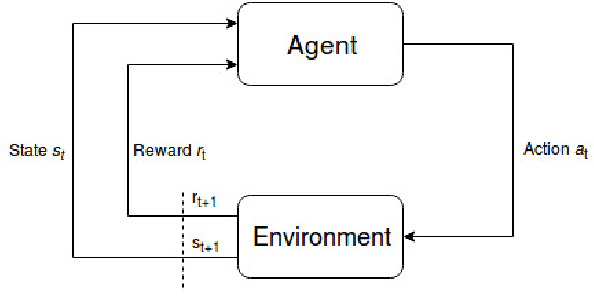

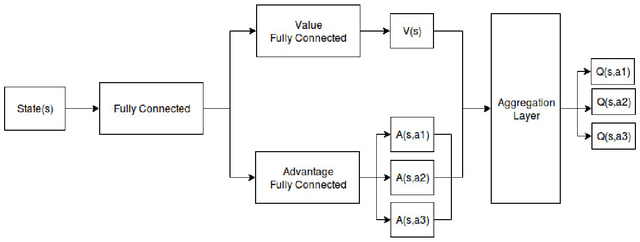
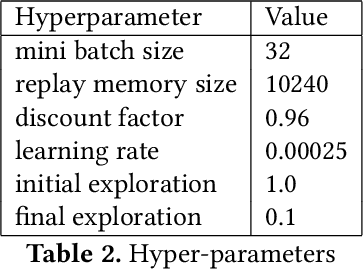
Motivated by recent advancements in Deep Reinforcement Learning (RL), we have developed an RL agent to manage the operation of storage devices in a household and is designed to maximize demand-side cost savings. The proposed technique is data-driven, and the RL agent learns from scratch how to efficiently use the energy storage device given variable tariff structures. In most of the studies, the RL agent is considered as a black box, and how the agent has learned is often ignored. We explain the learning progression of the RL agent, and the strategies it follows based on the capacity of the storage device.