 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamming Attention Distillation: Binarizing Keys and Queries for Efficient Long-Context Transformers
Feb 03, 2025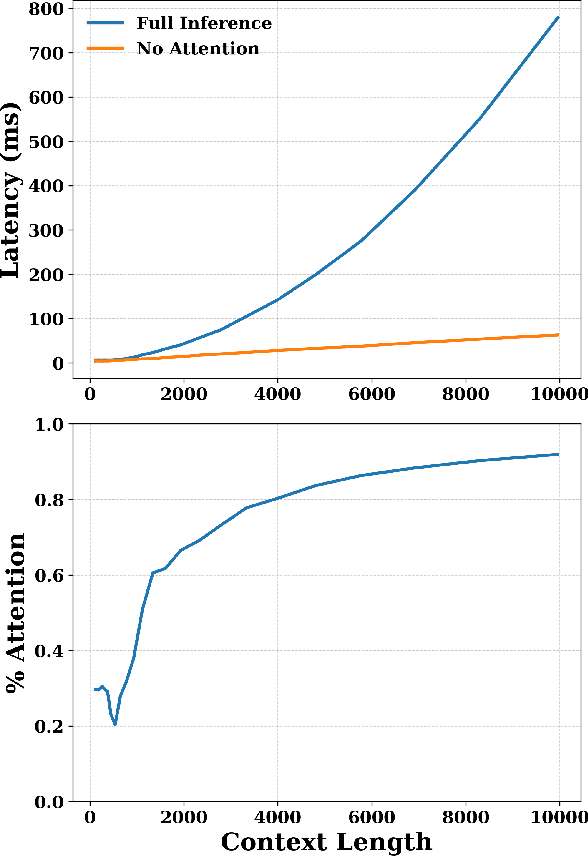
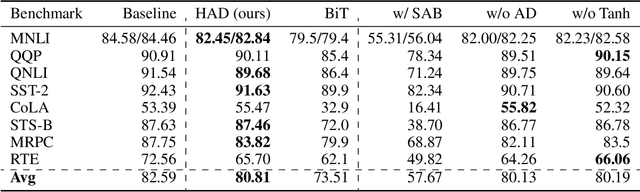
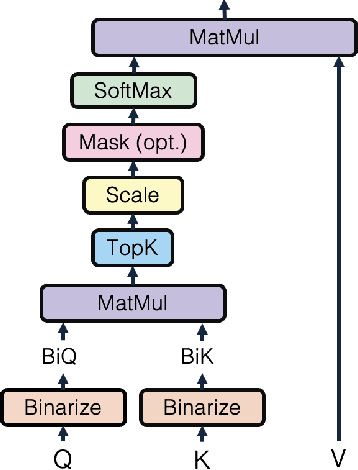
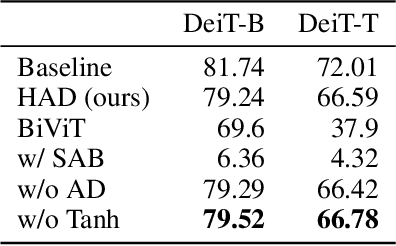
Pre-trained transformer models with extended context windows are notoriously expensive to run at scale, often limiting real-world deployment due to their high computational and memory requirements. In this paper, we introduce Hamming Attention Distillation (HAD), a novel framework that binarizes keys and queries in the attention mechanism to achieve significant efficiency gains. By converting keys and queries into {-1, +1} vectors and replacing dot-product operations with efficient Hamming distance computations, our method drastically reduces computational overhead. Additionally, we incorporate attention matrix sparsification to prune low-impact activations, which further reduces the cost of processing long-context sequences. \par Despite these aggressive compression strategies, our distilled approach preserves a high degree of representational power, leading to substantially improved accuracy compared to prior transformer binarization methods. We evaluate HAD on a range of tasks and models, including the GLUE benchmark, ImageNet, and QuALITY, demonstrating state-of-the-art performance among binarized Transformers while drastically reducing the computational costs of long-context inference. \par We implement HAD in custom hardware simulations, demonstrating superior performance characteristics compared to a custom hardware implementation of standard attention. HAD achieves just $\mathbf{1.78}\%$ performance losses on GLUE compared to $9.08\%$ in state-of-the-art binarization work, and $\mathbf{2.5}\%$ performance losses on ImageNet compared to $12.14\%$, all while targeting custom hardware with a $\mathbf{79}\%$ area reduction and $\mathbf{87}\%$ power reduction compared to its standard attention counterpart.
A Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
MonoSparse-CAM: Harnessing Monotonicity and Sparsity for Enhanced Tree Model Processing on CAMs
Jul 12, 2024



Despite significant advancements in AI driven by neural networks, tree-based machine learning (TBML) models excel on tabular data. These models exhibit promising energy efficiency, and high performance, particularly when accelerated on analog content-addressable memory (aCAM) arrays. However, optimizing their hardware deployment, especially in leveraging TBML model structure and aCAM circuitry, remains challenging. In this paper, we introduce MonoSparse-CAM, a novel content-addressable memory (CAM) based computing optimization technique. MonoSparse-CAM efficiently leverages TBML model sparsity and CAM array circuits, enhancing processing performance. Our experiments show that MonoSparse-CAM reduces energy consumption by up to 28.56x compared to raw processing and 18.51x compared to existing deployment optimization techniques. Additionally, it consistently achieves at least 1.68x computational efficiency over current methods. By enabling energy-efficient CAM-based computing while preserving performance regardless of the array sparsity, MonoSparse-CAM addresses the high energy consumption problem of CAM which hinders processing of large arrays. Our contributions are twofold: we propose MonoSparse-CAM as an effective deployment optimization solution for CAM-based computing, and we investigate the impact of TBML model structure on array sparsity. This work provides crucial insights for energy-efficient TBML on hardware, highlighting a significant advancement in sustainable AI technologies.
WiSleep: Scalable Sleep Monitoring and Analytics Using Passive WiFi Sensing
Feb 07, 2021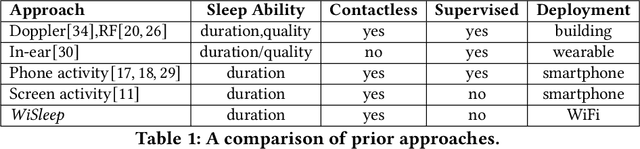
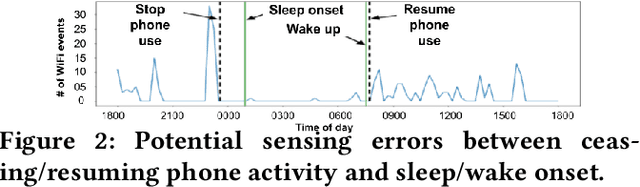

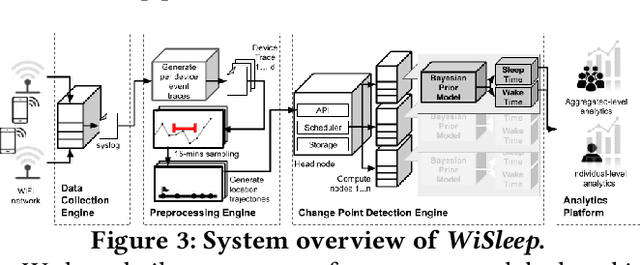
Sleep deprivation is a public health concern that significantly impacts one's well-being and performance. Sleep is an intimate experience, and state-of-the-art sleep monitoring solutions are highly-personalized to individual users. With a motivation to expand sleep monitoring at a large-scale and contribute sleep data to public health understanding, we present WiSleep, a sleep monitoring and analytics platform using smartphone network connections that are passively sensed from WiFi infrastructure. We propose an unsupervised ensemble model of Bayesian change point detection to predict sleep and wake-up times. Then, we validate our approach using ground truth from a user study in campus dormitories and a private home. Our results find WiSleep outperforming established methods for users with irregular sleep patterns while yielding comparable accuracy for regular sleepers with an average 79.5\% accuracy. This is comparable to client-side based methods, albeit utilizing only coarse-grained information. Finally, we show that WiSleep can process data from 20,000 users on a single commodity server, allowing it to scale to large campus populations with low server requirements.