 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamming Attention Distillation: Binarizing Keys and Queries for Efficient Long-Context Transformers
Feb 03, 2025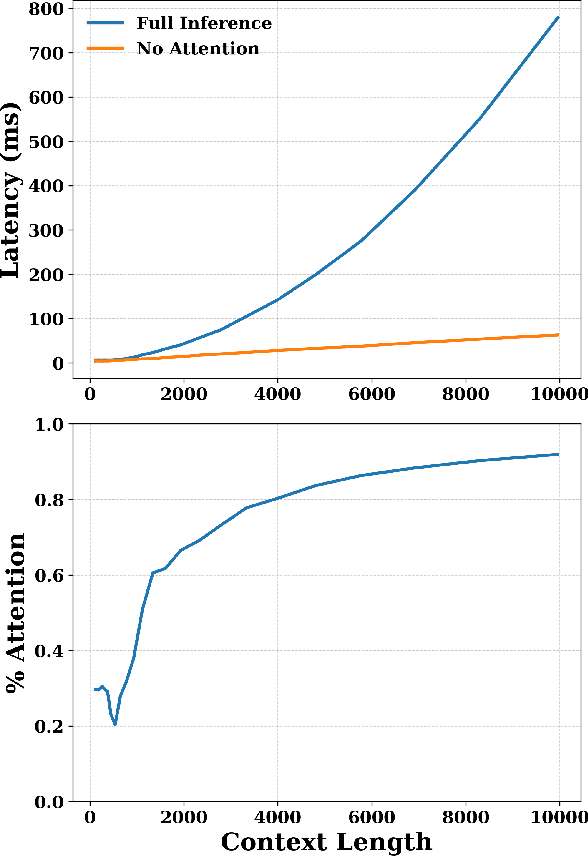
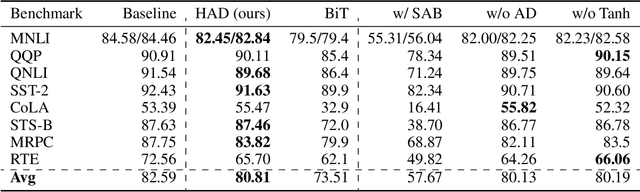
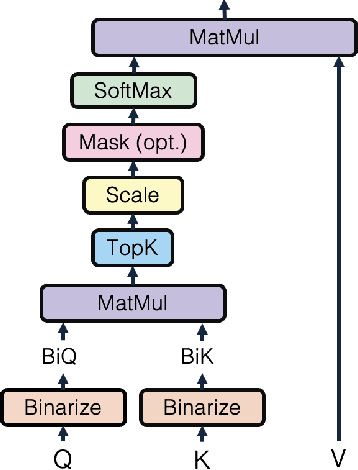
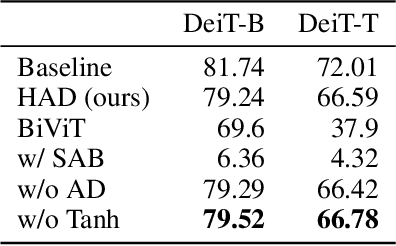
Pre-trained transformer models with extended context windows are notoriously expensive to run at scale, often limiting real-world deployment due to their high computational and memory requirements. In this paper, we introduce Hamming Attention Distillation (HAD), a novel framework that binarizes keys and queries in the attention mechanism to achieve significant efficiency gains. By converting keys and queries into {-1, +1} vectors and replacing dot-product operations with efficient Hamming distance computations, our method drastically reduces computational overhead. Additionally, we incorporate attention matrix sparsification to prune low-impact activations, which further reduces the cost of processing long-context sequences. \par Despite these aggressive compression strategies, our distilled approach preserves a high degree of representational power, leading to substantially improved accuracy compared to prior transformer binarization methods. We evaluate HAD on a range of tasks and models, including the GLUE benchmark, ImageNet, and QuALITY, demonstrating state-of-the-art performance among binarized Transformers while drastically reducing the computational costs of long-context inference. \par We implement HAD in custom hardware simulations, demonstrating superior performance characteristics compared to a custom hardware implementation of standard attention. HAD achieves just $\mathbf{1.78}\%$ performance losses on GLUE compared to $9.08\%$ in state-of-the-art binarization work, and $\mathbf{2.5}\%$ performance losses on ImageNet compared to $12.14\%$, all while targeting custom hardware with a $\mathbf{79}\%$ area reduction and $\mathbf{87}\%$ power reduction compared to its standard attention counterpart.
SAFER: Sharpness Aware layer-selective Finetuning for Enhanced Robustness in vision transformers
Jan 02, 2025



Vision transformers (ViTs) have become essential backbones in advanced computer vision applications and multi-modal foundation models. Despite their strengths, ViTs remain vulnerable to adversarial perturbations, comparable to or even exceeding the vulnerability of convolutional neural networks (CNNs). Furthermore, the large parameter count and complex architecture of ViTs make them particularly prone to adversarial overfitting, often compromising both clean and adversarial accuracy. This paper mitigates adversarial overfitting in ViTs through a novel, layer-selective fine-tuning approach: SAFER. Instead of optimizing the entire model, we identify and selectively fine-tune a small subset of layers most susceptible to overfitting, applying sharpness-aware minimization to these layers while freezing the rest of the model. Our method consistently enhances both clean and adversarial accuracy over baseline approaches. Typical improvements are around 5%, with some cases achieving gains as high as 20% across various ViT architectures and datasets.
Criticality Leveraged Adversarial Training (CLAT) for Boosted Performance via Parameter Efficiency
Aug 19, 2024



Adversarial training enhances neural network robustness but suffers from a tendency to overfit and increased generalization errors on clean data. This work introduces CLAT, an innovative approach that mitigates adversarial overfitting by introducing parameter efficiency into the adversarial training process, improving both clean accuracy and adversarial robustness. Instead of tuning the entire model, CLAT identifies and fine-tunes robustness-critical layers - those predominantly learning non-robust features - while freezing the remaining model to enhance robustness. It employs dynamic critical layer selection to adapt to changes in layer criticality throughout the fine-tuning process. Empirically, CLAT can be applied on top of existing adversarial training methods, significantly reduces the number of trainable parameters by approximately 95%, and achieves more than a 2% improvement in adversarial robustness compared to baseline methods.
LISSNAS: Locality-based Iterative Search Space Shrinkage for Neural Architecture Search
Jul 06, 2023



Search spaces hallmark the advancement of Neural Architecture Search (NAS). Large and complex search spaces with versatile building operators and structures provide more opportunities to brew promising architectures, yet pose severe challenges on efficient exploration and exploitation. Subsequently, several search space shrinkage methods optimize by selecting a single sub-region that contains some well-performing networks. Small performance and efficiency gains are observed with these methods but such techniques leave room for significantly improved search performance and are ineffective at retaining architectural diversity. We propose LISSNAS, an automated algorithm that shrinks a large space into a diverse, small search space with SOTA search performance. Our approach leverages locality, the relationship between structural and performance similarity, to efficiently extract many pockets of well-performing networks. We showcase our method on an array of search spaces spanning various sizes and datasets. We accentuate the effectiveness of our shrunk spaces when used in one-shot search by achieving the best Top-1 accuracy in two different search spaces. Our method achieves a SOTA Top-1 accuracy of 77.6\% in ImageNet under mobile constraints, best-in-class Kendal-Tau, architectural diversity, and search space size.