 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-GPS: Guidlines for Prediction Strategy for Dynamic Expert Duplication in MoE Load Balancing
Jun 09, 2025In multi-GPU Mixture-of-Experts (MoE) network, experts are distributed across different GPUs, which creates load imbalance as each expert processes different number of tokens. Recent works improve MoE inference load balance by dynamically duplicating popular experts to more GPUs to process excessive tokens, which requires predicting the distribution before routing. In this paper, we discuss the tradeoff of prediction strategies, accuracies, overhead, and end-to-end system performance. We propose MoE-GPS, a framework that guides the selection of the optimal predictor design under various system configurations, by quantifying the performance impact to system-level model runtime. Specifically, we advocate for Distribution-Only Prediction, a prediction strategy that only predicts overall token distribution which significantly reduces overhead compared to the traditional Token-to-Expert Prediction. On Mixtral 8x7B MMLU dataset, MoE-GPS suggests Distribution-Only Prediction which improves end-to-end inference performance by more than 23% compared with Token-to-Expert Prediction.
A Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
Knowledge Graph Tuning: Real-time Large Language Model Personalization based on Human Feedback
May 30, 2024



Large language models (LLMs) have demonstrated remarkable proficiency in a range of natural language processing tasks. Once deployed, LLMs encounter users with personalized factual knowledge, and such personalized knowledge is consistently reflected through users' interactions with the LLMs. To enhance user experience, real-time model personalization is essential, allowing LLMs to adapt user-specific knowledge based on user feedback during human-LLM interactions. Existing methods mostly require back-propagation to finetune the model parameters, which incurs high computational and memory costs. In addition, these methods suffer from low interpretability, which will cause unforeseen impacts on model performance during long-term use, where the user's personalized knowledge is accumulated extensively.To address these challenges, we propose Knowledge Graph Tuning (KGT), a novel approach that leverages knowledge graphs (KGs) to personalize LLMs. KGT extracts personalized factual knowledge triples from users' queries and feedback and optimizes KGs without modifying the LLM parameters. Our method improves computational and memory efficiency by avoiding back-propagation and ensures interpretability by making the KG adjustments comprehensible to humans.Experiments with state-of-the-art LLMs, including GPT-2, Llama2, and Llama3, show that KGT significantly improves personalization performance while reducing latency and GPU memory costs. Ultimately, KGT offers a promising solution of effective, efficient, and interpretable real-time LLM personalization during user interactions with the LLMs.
SiDA: Sparsity-Inspired Data-Aware Serving for Efficient and Scalable Large Mixture-of-Experts Models
Oct 29, 2023



Mixture-of-Experts (MoE) has emerged as a favorable architecture in the era of large models due to its inherent advantage, i.e., enlarging model capacity without incurring notable computational overhead. Yet, the realization of such benefits often results in ineffective GPU memory utilization, as large portions of the model parameters remain dormant during inference. Moreover, the memory demands of large models consistently outpace the memory capacity of contemporary GPUs. Addressing this, we introduce SiDA (Sparsity-inspired Data-Aware), an efficient inference approach tailored for large MoE models. SiDA judiciously exploits both the system's main memory, which is now abundant and readily scalable, and GPU memory by capitalizing on the inherent sparsity on expert activation in MoE models. By adopting a data-aware perspective, SiDA achieves enhanced model efficiency with a neglectable performance drop. Specifically, SiDA attains a remarkable speedup in MoE inference with up to 3.93X throughput increasing, up to 75% latency reduction, and up to 80% GPU memory saving with down to 1% performance drop. This work paves the way for scalable and efficient deployment of large MoE models, even in memory-constrained systems.
Robust and IP-Protecting Vertical Federated Learning against Unexpected Quitting of Parties
Mar 28, 2023Vertical federated learning (VFL) enables a service provider (i.e., active party) who owns labeled features to collaborate with passive parties who possess auxiliary features to improve model performance. Existing VFL approaches, however, have two major vulnerabilities when passive parties unexpectedly quit in the deployment phase of VFL - severe performance degradation and intellectual property (IP) leakage of the active party's labels. In this paper, we propose \textbf{Party-wise Dropout} to improve the VFL model's robustness against the unexpected exit of passive parties and a defense method called \textbf{DIMIP} to protect the active party's IP in the deployment phase. We evaluate our proposed methods on multiple datasets against different inference attacks. The results show that Party-wise Dropout effectively maintains model performance after the passive party quits, and DIMIP successfully disguises label information from the passive party's feature extractor, thereby mitigating IP leakage.
Rethinking Normalization Methods in Federated Learning
Oct 07, 2022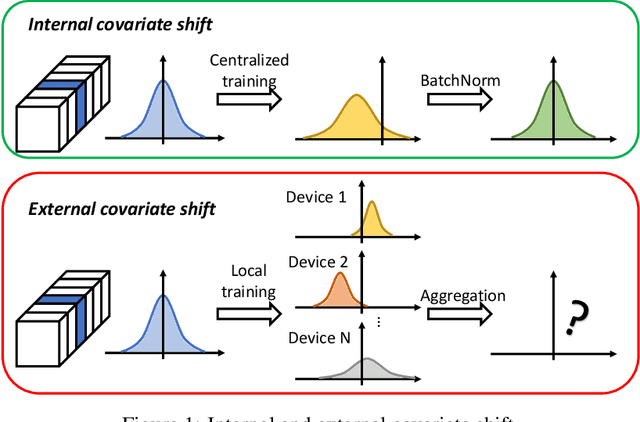

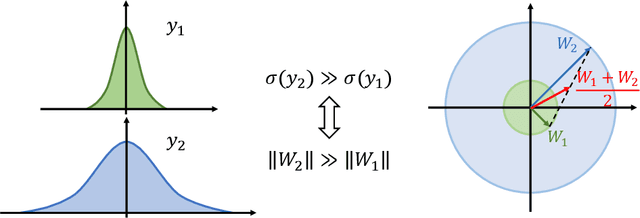
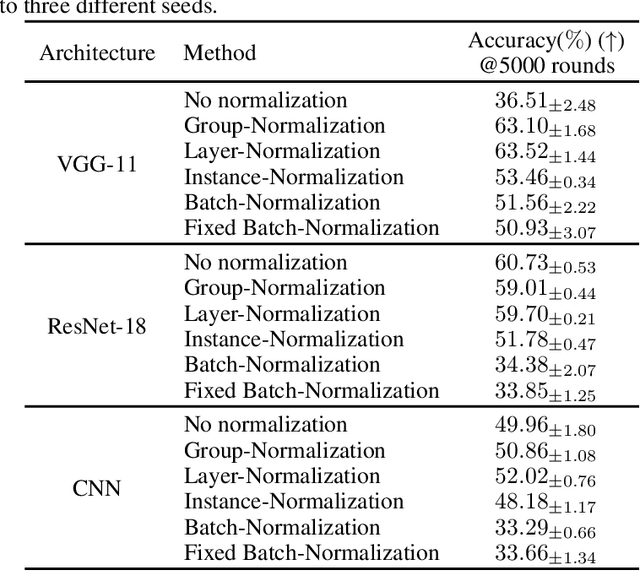
Federated learning (FL) is a popular distributed learning framework that can reduce privacy risks by not explicitly sharing private data. In this work, we explicitly uncover external covariate shift problem in FL, which is caused by the independent local training processes on different devices. We demonstrate that external covariate shifts will lead to the obliteration of some devices' contributions to the global model. Further, we show that normalization layers are indispensable in FL since their inherited properties can alleviate the problem of obliterating some devices' contributions. However, recent works have shown that batch normalization, which is one of the standard components in many deep neural networks, will incur accuracy drop of the global model in FL. The essential reason for the failure of batch normalization in FL is poorly studied. We unveil that external covariate shift is the key reason why batch normalization is ineffective in FL. We also show that layer normalization is a better choice in FL which can mitigate the external covariate shift and improve the performance of the global model. We conduct experiments on CIFAR10 under non-IID settings. The results demonstrate that models with layer normalization converge fastest and achieve the best or comparable accuracy for three different model architectures.
Improved Input Reprogramming for GAN Conditioning
Feb 07, 2022

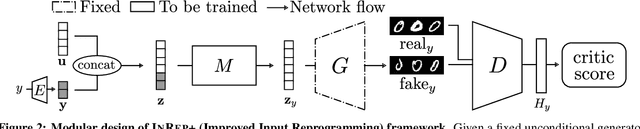
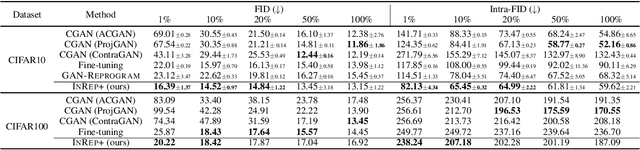
We study the GAN conditioning problem, whose goal is to convert a pretrained unconditional GAN into a conditional GAN using labeled data. We first identify and analyze three approaches to this problem -- conditional GAN training from scratch, fine-tuning, and input reprogramming. Our analysis reveals that when the amount of labeled data is small, input reprogramming performs the best. Motivated by real-world scenarios with scarce labeled data, we focus on the input reprogramming approach and carefully analyze the existing algorithm. After identifying a few critical issues of the previous input reprogramming approach, we propose a new algorithm called InRep+. Our algorithm InRep+ addresses the existing issues with the novel uses of invertible neural networks and Positive-Unlabeled (PU) learning. Via extensive experiments, we show that InRep+ outperforms all existing methods, particularly when label information is scarce, noisy, and/or imbalanced. For instance, for the task of conditioning a CIFAR10 GAN with 1% labeled data, InRep+ achieves an average Intra-FID of 76.24, whereas the second-best method achieves 114.51.