 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCourse Recommender Systems Need to Consider the Job Market
Apr 16, 2024



Current course recommender systems primarily leverage learner-course interactions, course content, learner preferences, and supplementary course details like instructor, institution, ratings, and reviews, to make their recommendation. However, these systems often overlook a critical aspect: the evolving skill demand of the job market. This paper focuses on the perspective of academic researchers, working in collaboration with the industry, aiming to develop a course recommender system that incorporates job market skill demands. In light of the job market's rapid changes and the current state of research in course recommender systems, we outline essential properties for course recommender systems to address these demands effectively, including explainable, sequential, unsupervised, and aligned with the job market and user's goals. Our discussion extends to the challenges and research questions this objective entails, including unsupervised skill extraction from job listings, course descriptions, and resumes, as well as predicting recommendations that align with learner objectives and the job market and designing metrics to evaluate this alignment. Furthermore, we introduce an initial system that addresses some existing limitations of course recommender systems using large Language Models (LLMs) for skill extraction and Reinforcement Learning (RL) for alignment with the job market. We provide empirical results using open-source data to demonstrate its effectiveness.
JOBSKAPE: A Framework for Generating Synthetic Job Postings to Enhance Skill Matching
Feb 05, 2024



Recent approaches in skill matching, employing synthetic training data for classification or similarity model training, have shown promising results, reducing the need for time-consuming and expensive annotations. However, previous synthetic datasets have limitations, such as featuring only one skill per sentence and generally comprising short sentences. In this paper, we introduce JobSkape, a framework to generate synthetic data that tackles these limitations, specifically designed to enhance skill-to-taxonomy matching. Within this framework, we create SkillSkape, a comprehensive open-source synthetic dataset of job postings tailored for skill-matching tasks. We introduce several offline metrics that show that our dataset resembles real-world data. Additionally, we present a multi-step pipeline for skill extraction and matching tasks using large language models (LLMs), benchmarking against known supervised methodologies. We outline that the downstream evaluation results on real-world data can beat baselines, underscoring its efficacy and adaptability.
Robust and IP-Protecting Vertical Federated Learning against Unexpected Quitting of Parties
Mar 28, 2023Vertical federated learning (VFL) enables a service provider (i.e., active party) who owns labeled features to collaborate with passive parties who possess auxiliary features to improve model performance. Existing VFL approaches, however, have two major vulnerabilities when passive parties unexpectedly quit in the deployment phase of VFL - severe performance degradation and intellectual property (IP) leakage of the active party's labels. In this paper, we propose \textbf{Party-wise Dropout} to improve the VFL model's robustness against the unexpected exit of passive parties and a defense method called \textbf{DIMIP} to protect the active party's IP in the deployment phase. We evaluate our proposed methods on multiple datasets against different inference attacks. The results show that Party-wise Dropout effectively maintains model performance after the passive party quits, and DIMIP successfully disguises label information from the passive party's feature extractor, thereby mitigating IP leakage.
Fast Frontier-based Information-driven Autonomous Exploration with an MAV
Feb 13, 2020
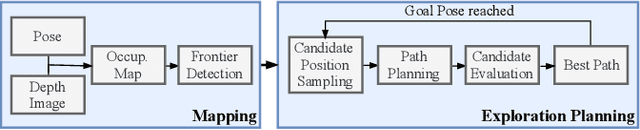

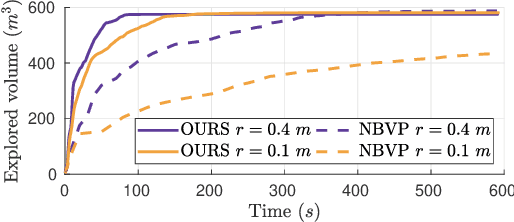
Exploration and collision-free navigation through an unknown environment is a fundamental task for autonomous robots. In this paper, a novel exploration strategy for Micro Aerial Vehicles (MAVs) is presented. The goal of the exploration strategy is the reduction of map entropy regarding occupancy probabilities, which is reflected in a utility function to be maximised. We achieve fast and efficient exploration performance with tight integration between our octree-based occupancy mapping approach, frontier extraction, and motion planning-as a hybrid between frontier-based and sampling-based exploration methods. The computationally expensive frontier clustering employed in classic frontier-based exploration is avoided by exploiting the implicit grouping of frontier voxels in the underlying octree map representation. Candidate next-views are sampled from the map frontiers and are evaluated using a utility function combining map entropy and travel time, where the former is computed efficiently using sparse raycasting. These optimisations along with the targeted exploration of frontier-based methods result in a fast and computationally efficient exploration planner. The proposed method is evaluated using both simulated and real-world experiments, demonstrating clear advantages over state-of-the-art approaches.
Evaluation Mechanism of Collective Intelligence for Heterogeneous Agents Group
Mar 01, 2019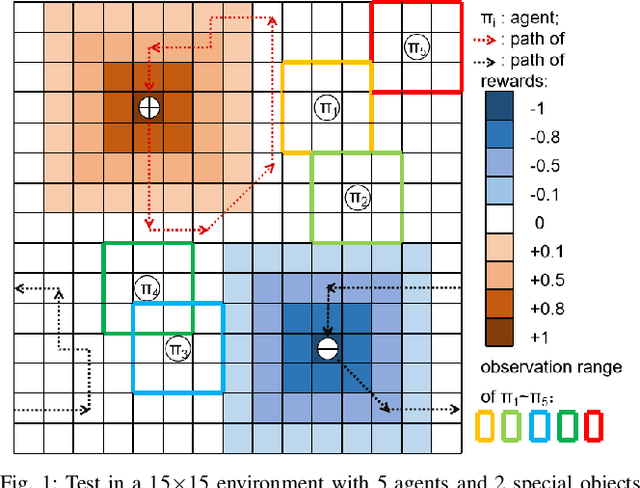
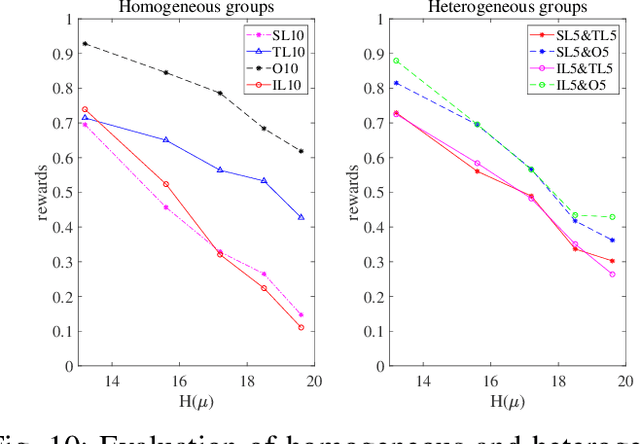
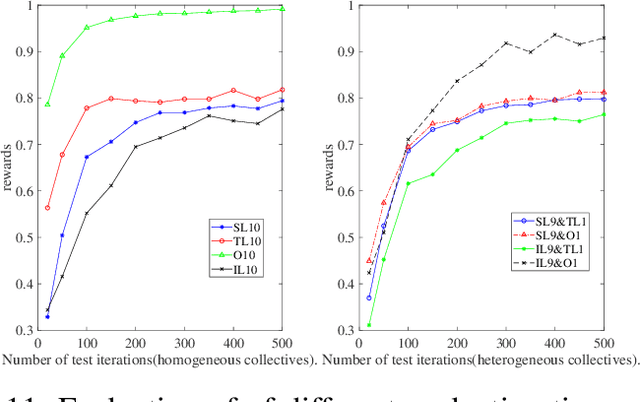
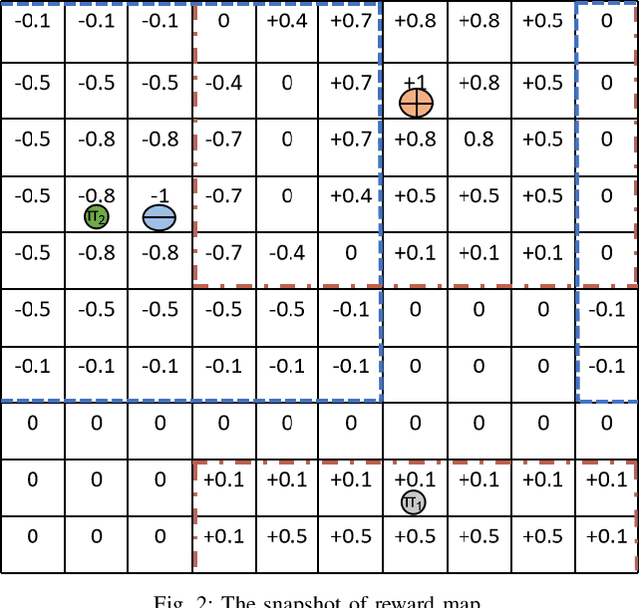
Collective intelligence is manifested when multiple agents coherently work in observation, interaction, decision-making and action. In this paper, we define and quantify the intelligence level of heterogeneous agents group with the improved Anytime Universal Intelligence Test(AUIT), based on an extension of the existing evaluation of homogeneous agents group. The relationship of intelligence level with agents composition, group size, spatial complexity and testing time is analyzed. The intelligence level of heterogeneous agents groups is compared with the homogeneous ones to analyze the effects of heterogeneity on collective intelligence. Our work will help to understand the essence of collective intelligence more deeply and reveal the effect of various key factors on group intelligence level.