 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Compromise: Pareto-Lenient Consensus for Efficient Multi-Preference LLM Alignment
Apr 07, 2026Transcending the single-preference paradigm, aligning LLMs with diverse human values is pivotal for robust deployment. Contemporary Multi-Objective Preference Alignment (MPA) approaches predominantly rely on static linear scalarization or rigid gradient projection to navigate these trade-offs. However, by enforcing strict conflict avoidance or simultaneous descent, these paradigms often prematurely converge to local stationary points. While mathematically stable, these points represent a conservative compromise where the model sacrifices potential global Pareto improvements to avoid transient local trade-offs. To break this deadlock, we propose Pareto-Lenient Consensus (PLC), a game-theoretic framework that reimagines alignment as a dynamic negotiation process. Unlike rigid approaches, PLC introduces consensus-driven lenient gradient rectification, which dynamically tolerates local degradation provided there is a sufficient dominant coalition surplus, thereby empowering the optimization trajectory to escape local suboptimal equilibrium and explore the distal Pareto-optimal frontier. Theoretical analysis validates PLC can facilitate stalemate escape and asymptotically converge to a Pareto consensus equilibrium. Moreover, extensive experiments show that PLC surpasses baselines in both fixed-preference alignment and global Pareto frontier quality. This work highlights the potential of negotiation-driven alignment as a promising avenue for MPA. Our codes are available at https://anonymous.4open.science/r/aaa-6BB8.
Communications-Incentivized Collaborative Reasoning in NetGPT through Agentic Reinforcement Learning
Jan 31, 2026The evolution of next-Generation (xG) wireless networks marks a paradigm shift from connectivity-centric architectures to Artificial Intelligence (AI)-native designs that tightly integrate data, computing, and communication. Yet existing AI deployments in communication systems remain largely siloed, offering isolated optimizations without intrinsic adaptability, dynamic task delegation, or multi-agent collaboration. In this work, we propose a unified agentic NetGPT framework for AI-native xG networks, wherein a NetGPT core can either perform autonomous reasoning or delegate sub-tasks to domain-specialized agents via agentic communication. The framework establishes clear modular responsibilities and interoperable workflows, enabling scalable, distributed intelligence across the network. To support continual refinement of collaborative reasoning strategies, the framework is further enhanced through Agentic reinforcement learning under partially observable conditions and stochastic external states. The training pipeline incorporates masked loss against external agent uncertainty, entropy-guided exploration, and multi-objective rewards that jointly capture task quality, coordination efficiency, and resource constraints. Through this process, NetGPT learns when and how to collaborate, effectively balancing internal reasoning with agent invocation. Overall, this work provides a foundational architecture and training methodology for self-evolving, AI-native xG networks capable of autonomous sensing, reasoning, and action in complex communication environments.
In-Context Source and Channel Coding
Jan 15, 2026Separate Source-Channel Coding (SSCC) remains attractive for text transmission due to its modularity and compatibility with mature entropy coders and powerful channel codes. However, SSCC often suffers from a pronounced cliff effect in low Signal-to-Noise Ratio (SNR) regimes, where residual bit errors after channel decoding can catastrophically break lossless source decoding, especially for Arithmetic Coding (AC) driven by Large Language Models (LLMs). This paper proposes a receiver-side In-Context Decoding (ICD) framework that enhances SSCC robustness without modifying the transmitter. ICD leverages an Error Correction Code Transformer (ECCT) to obtain bit-wise reliability for the decoded information bits. Based on the context-consistent bitstream, ICD constructs a confidence-ranked candidate pool via reliability-guided bit flipping, samples a compact yet diverse subset of candidates, and applies an LLM-based arithmetic decoder to obtain both reconstructions and sequence-level log-likelihoods. A reliability-likelihood fusion rule then selects the final output. We further provide theoretical guarantees on the stability and convergence of the proposed sampling procedure. Extensive experiments over Additive White Gaussian Noise (AWGN) and Rayleigh fading channels demonstrate consistent gains compared with conventional SSCC baselines and representative Joint Source-Channel Coding (JSCC) schemes.
Multi-Agent Conditional Diffusion Model with Mean Field Communication as Wireless Resource Allocation Planner
Oct 27, 2025In wireless communication systems, efficient and adaptive resource allocation plays a crucial role in enhancing overall Quality of Service (QoS). While centralized Multi-Agent Reinforcement Learning (MARL) frameworks rely on a central coordinator for policy training and resource scheduling, they suffer from scalability issues and privacy risks. In contrast, the Distributed Training with Decentralized Execution (DTDE) paradigm enables distributed learning and decision-making, but it struggles with non-stationarity and limited inter-agent cooperation, which can severely degrade system performance. To overcome these challenges, we propose the Multi-Agent Conditional Diffusion Model Planner (MA-CDMP) for decentralized communication resource management. Built upon the Model-Based Reinforcement Learning (MBRL) paradigm, MA-CDMP employs Diffusion Models (DMs) to capture environment dynamics and plan future trajectories, while an inverse dynamics model guides action generation, thereby alleviating the sample inefficiency and slow convergence of conventional DTDE methods. Moreover, to approximate large-scale agent interactions, a Mean-Field (MF) mechanism is introduced as an assistance to the classifier in DMs. This design mitigates inter-agent non-stationarity and enhances cooperation with minimal communication overhead in distributed settings. We further theoretically establish an upper bound on the distributional approximation error introduced by the MF-based diffusion generation, guaranteeing convergence stability and reliable modeling of multi-agent stochastic dynamics. Extensive experiments demonstrate that MA-CDMP consistently outperforms existing MARL baselines in terms of average reward and QoS metrics, showcasing its scalability and practicality for real-world wireless network optimization.
AirLLM: Diffusion Policy-based Adaptive LoRA for Remote Fine-Tuning of LLM over the Air
Jul 15, 2025
Operating Large Language Models (LLMs) on edge devices is increasingly challenged by limited communication bandwidth and strained computational and memory costs. Thus, cloud-assisted remote fine-tuning becomes indispensable. Nevertheless, existing Low-Rank Adaptation (LoRA) approaches typically employ fixed or heuristic rank configurations, and the subsequent over-the-air transmission of all LoRA parameters could be rather inefficient. To address this limitation, we develop AirLLM, a hierarchical diffusion policy framework for communication-aware LoRA adaptation. Specifically, AirLLM models the rank configuration as a structured action vector that spans all LoRA-inserted projections. To solve the underlying high-dimensional sequential decision-making problem, a Proximal Policy Optimization (PPO) agent generates coarse-grained decisions by jointly observing wireless states and linguistic complexity, which are then refined via Denoising Diffusion Implicit Models (DDIM) to produce high-resolution, task- and channel-adaptive rank vectors. The two modules are optimized alternatively, with the DDIM trained under the Classifier-Free Guidance (CFG) paradigm to maintain alignment with PPO rewards. Experiments under varying signal-to-noise ratios demonstrate that AirLLM consistently enhances fine-tuning performance while significantly reducing transmission costs, highlighting the effectiveness of reinforcement-driven, diffusion-refined rank adaptation for scalable and efficient remote fine-tuning over the air.
RALLY: Role-Adaptive LLM-Driven Yoked Navigation for Agentic UAV Swarms
Jul 02, 2025Intelligent control of Unmanned Aerial Vehicles (UAVs) swarms has emerged as a critical research focus, and it typically requires the swarm to navigate effectively while avoiding obstacles and achieving continuous coverage over multiple mission targets. Although traditional Multi-Agent Reinforcement Learning (MARL) approaches offer dynamic adaptability, they are hindered by the semantic gap in numerical communication and the rigidity of homogeneous role structures, resulting in poor generalization and limited task scalability. Recent advances in Large Language Model (LLM)-based control frameworks demonstrate strong semantic reasoning capabilities by leveraging extensive prior knowledge. However, due to the lack of online learning and over-reliance on static priors, these works often struggle with effective exploration, leading to reduced individual potential and overall system performance. To address these limitations, we propose a Role-Adaptive LLM-Driven Yoked navigation algorithm RALLY. Specifically, we first develop an LLM-driven semantic decision framework that uses structured natural language for efficient semantic communication and collaborative reasoning. Afterward, we introduce a dynamic role-heterogeneity mechanism for adaptive role switching and personalized decision-making. Furthermore, we propose a Role-value Mixing Network (RMIX)-based assignment strategy that integrates LLM offline priors with MARL online policies to enable semi-offline training of role selection strategies. Experiments in the Multi-Agent Particle Environment (MPE) environment and a Software-In-The-Loop (SITL) platform demonstrate that RALLY outperforms conventional approaches in terms of task coverage, convergence speed, and generalization, highlighting its strong potential for collaborative navigation in agentic multi-UAV systems.
Topology-Assisted Spatio-Temporal Pattern Disentangling for Scalable MARL in Large-scale Autonomous Traffic Control
Jun 14, 2025Intelligent Transportation Systems (ITSs) have emerged as a promising solution towards ameliorating urban traffic congestion, with Traffic Signal Control (TSC) identified as a critical component. Although Multi-Agent Reinforcement Learning (MARL) algorithms have shown potential in optimizing TSC through real-time decision-making, their scalability and effectiveness often suffer from large-scale and complex environments. Typically, these limitations primarily stem from a fundamental mismatch between the exponential growth of the state space driven by the environmental heterogeneities and the limited modeling capacity of current solutions. To address these issues, this paper introduces a novel MARL framework that integrates Dynamic Graph Neural Networks (DGNNs) and Topological Data Analysis (TDA), aiming to enhance the expressiveness of environmental representations and improve agent coordination. Furthermore, inspired by the Mixture of Experts (MoE) architecture in Large Language Models (LLMs), a topology-assisted spatial pattern disentangling (TSD)-enhanced MoE is proposed, which leverages topological signatures to decouple graph features for specialized processing, thus improving the model's ability to characterize dynamic and heterogeneous local observations. The TSD module is also integrated into the policy and value networks of the Multi-agent Proximal Policy Optimization (MAPPO) algorithm, further improving decision-making efficiency and robustness. Extensive experiments conducted on real-world traffic scenarios, together with comprehensive theoretical analysis, validate the superior performance of the proposed framework, highlighting the model's scalability and effectiveness in addressing the complexities of large-scale TSC tasks.
Tool-Aided Evolutionary LLM for Generative Policy Toward Efficient Resource Management in Wireless Federated Learning
May 16, 2025
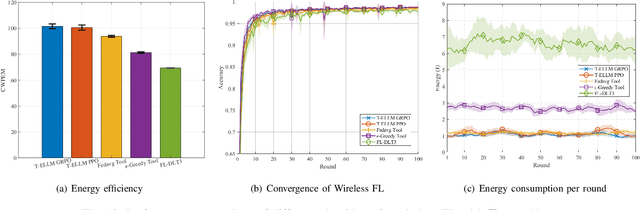
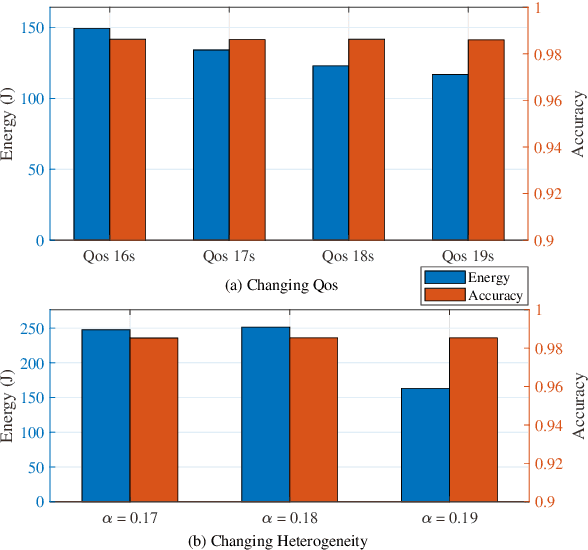
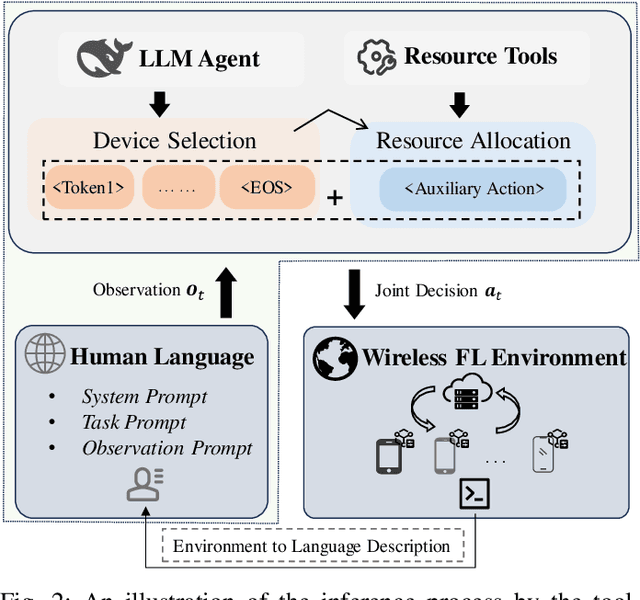
Federated Learning (FL) enables distributed model training across edge devices in a privacy-friendly manner. However, its efficiency heavily depends on effective device selection and high-dimensional resource allocation in dynamic and heterogeneous wireless environments. Conventional methods demand a confluence of domain-specific expertise, extensive hyperparameter tuning, and/or heavy interaction cost. This paper proposes a Tool-aided Evolutionary Large Language Model (T-ELLM) framework to generate a qualified policy for device selection in a wireless FL environment. Unlike conventional optimization methods, T-ELLM leverages natural language-based scenario prompts to enhance generalization across varying network conditions. The framework decouples the joint optimization problem mathematically, enabling tractable learning of device selection policies while delegating resource allocation to convex optimization tools. To improve adaptability, T-ELLM integrates a sample-efficient, model-based virtual learning environment that captures the relationship between device selection and learning performance, facilitating subsequent group relative policy optimization. This concerted approach reduces reliance on real-world interactions, minimizing communication overhead while maintaining high-fidelity decision-making. Theoretical analysis proves that the discrepancy between virtual and real environments is bounded, ensuring the advantage function learned in the virtual environment maintains a provably small deviation from real-world conditions. Experimental results demonstrate that T-ELLM outperforms benchmark methods in energy efficiency and exhibits robust adaptability to environmental changes.
Reinforcement Learning-Based Heterogeneous Multi-Task Optimization in Semantic Broadcast Communications
Apr 28, 2025



Semantic broadcast communications (Semantic BC) for image transmission have achieved significant performance gains for single-task scenarios. Nevertheless, extending these methods to multi-task scenarios remains challenging, as different tasks typically require distinct objective functions, leading to potential conflicts within the shared encoder. In this paper, we propose a tri-level reinforcement learning (RL)-based multi-task Semantic BC framework, termed SemanticBC-TriRL, which effectively resolves such conflicts and enables the simultaneous support of multiple downstream tasks at the receiver side, including image classification and content reconstruction tasks. Specifically, the proposed framework employs a bottom-up tri-level alternating learning strategy, formulated as a constrained multi-objective optimization problem. At the first level, task-specific decoders are locally optimized using supervised learning. At the second level, the shared encoder is updated via proximal policy optimization (PPO), guided by task-oriented rewards. At the third level, a multi-gradient aggregation-based task weighting module adaptively adjusts task priorities and steers the encoder optimization. Through this hierarchical learning process, the encoder and decoders are alternately trained, and the three levels are cohesively integrated via constrained learning objective. Besides, the convergence of SemanticBC-TriRL is also theoretically established. Extensive simulation results demonstrate the superior performance of the proposed framework across diverse channel conditions, particularly in low SNR regimes, and confirm its scalability with increasing numbers of receivers.
Separate Source Channel Coding Is Still What You Need: An LLM-based Rethinking
Jan 08, 2025



Along with the proliferating research interest in Semantic Communication (SemCom), Joint Source Channel Coding (JSCC) has dominated the attention due to the widely assumed existence in efficiently delivering information semantics. %has emerged as a pivotal area of research, aiming to enhance the efficiency and reliability of information transmission through deep learning-based methods. Nevertheless, this paper challenges the conventional JSCC paradigm, and advocates for adoption of Separate Source Channel Coding (SSCC) to enjoy the underlying more degree of freedom for optimization. We demonstrate that SSCC, after leveraging the strengths of Large Language Model (LLM) for source coding and Error Correction Code Transformer (ECCT) complemented for channel decoding, offers superior performance over JSCC. Our proposed framework also effectively highlights the compatibility challenges between SemCom approaches and digital communication systems, particularly concerning the resource costs associated with the transmission of high precision floating point numbers. Through comprehensive evaluations, we establish that empowered by LLM-based compression and ECCT-enhanced error correction, SSCC remains a viable and effective solution for modern communication systems. In other words, separate source and channel coding is still what we need!