 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-Based Heterogeneous Multi-Task Optimization in Semantic Broadcast Communications
Apr 28, 2025



Semantic broadcast communications (Semantic BC) for image transmission have achieved significant performance gains for single-task scenarios. Nevertheless, extending these methods to multi-task scenarios remains challenging, as different tasks typically require distinct objective functions, leading to potential conflicts within the shared encoder. In this paper, we propose a tri-level reinforcement learning (RL)-based multi-task Semantic BC framework, termed SemanticBC-TriRL, which effectively resolves such conflicts and enables the simultaneous support of multiple downstream tasks at the receiver side, including image classification and content reconstruction tasks. Specifically, the proposed framework employs a bottom-up tri-level alternating learning strategy, formulated as a constrained multi-objective optimization problem. At the first level, task-specific decoders are locally optimized using supervised learning. At the second level, the shared encoder is updated via proximal policy optimization (PPO), guided by task-oriented rewards. At the third level, a multi-gradient aggregation-based task weighting module adaptively adjusts task priorities and steers the encoder optimization. Through this hierarchical learning process, the encoder and decoders are alternately trained, and the three levels are cohesively integrated via constrained learning objective. Besides, the convergence of SemanticBC-TriRL is also theoretically established. Extensive simulation results demonstrate the superior performance of the proposed framework across diverse channel conditions, particularly in low SNR regimes, and confirm its scalability with increasing numbers of receivers.
Enhancing Automatic Modulation Recognition through Robust Global Feature Extraction
Jan 02, 2024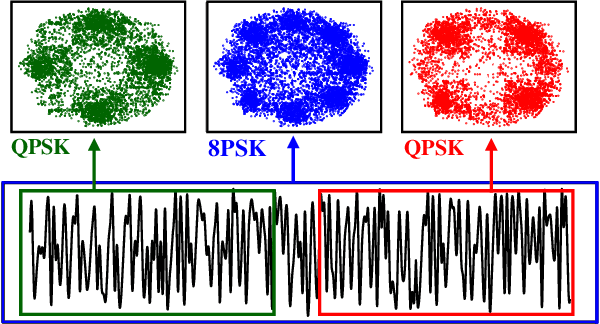
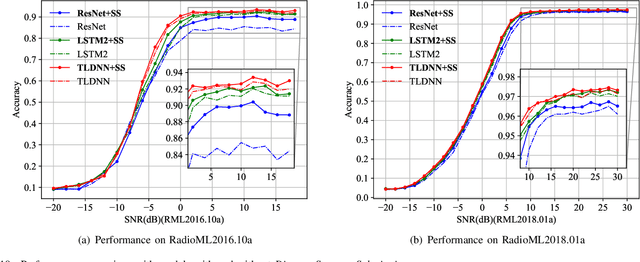
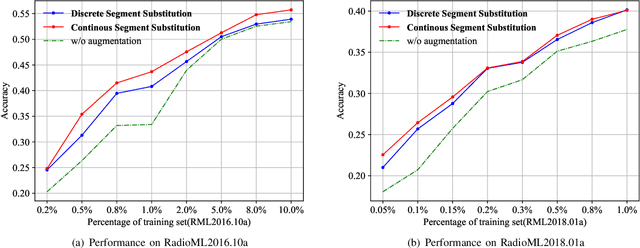

Automatic Modulation Recognition (AMR) plays a crucial role in wireless communication systems. Deep learning AMR strategies have achieved tremendous success in recent years. Modulated signals exhibit long temporal dependencies, and extracting global features is crucial in identifying modulation schemes. Traditionally, human experts analyze patterns in constellation diagrams to classify modulation schemes. Classical convolutional-based networks, due to their limited receptive fields, excel at extracting local features but struggle to capture global relationships. To address this limitation, we introduce a novel hybrid deep framework named TLDNN, which incorporates the architectures of the transformer and long short-term memory (LSTM). We utilize the self-attention mechanism of the transformer to model the global correlations in signal sequences while employing LSTM to enhance the capture of temporal dependencies. To mitigate the impact like RF fingerprint features and channel characteristics on model generalization, we propose data augmentation strategies known as segment substitution (SS) to enhance the model's robustness to modulation-related features. Experimental results on widely-used datasets demonstrate that our method achieves state-of-the-art performance and exhibits significant advantages in terms of complexity. Our proposed framework serves as a foundational backbone that can be extended to different datasets. We have verified the effectiveness of our augmentation approach in enhancing the generalization of the models, particularly in few-shot scenarios. Code is available at \url{https://github.com/AMR-Master/TLDNN}.
Self-Critical Alternate Learning based Semantic Broadcast Communication
Dec 03, 2023



Semantic communication (SemCom) has been deemed as a promising communication paradigm to break through the bottleneck of traditional communications. Nonetheless, most of the existing works focus more on point-to-point communication scenarios and its extension to multi-user scenarios is not that straightforward due to its cost-inefficiencies to directly scale the JSCC framework to the multi-user communication system. Meanwhile, previous methods optimize the system by differentiable bit-level supervision, easily leading to a "semantic gap". Therefore, we delve into multi-user broadcast communication (BC) based on the universal transformer (UT) and propose a reinforcement learning (RL) based self-critical alternate learning (SCAL) algorithm, named SemanticBC-SCAL, to capably adapt to the different BC channels from one transmitter (TX) to multiple receivers (RXs) for sentence generation task. In particular, to enable stable optimization via a nondifferentiable semantic metric, we regard sentence similarity as a reward and formulate this learning process as an RL problem. Considering the huge decision space, we adopt a lightweight but efficient self-critical supervision to guide the learning process. Meanwhile, an alternate learning mechanism is developed to provide cost-effective learning, in which the encoder and decoders are updated asynchronously with different iterations. Notably, the incorporation of RL makes SemanticBC-SCAL compliant with any user-defined semantic similarity metric and simultaneously addresses the channel non-differentiability issue by alternate learning. Besides, the convergence of SemanticBC-SCAL is also theoretically established. Extensive simulation results have been conducted to verify the effectiveness and superiorness of our approach, especially in low SNRs.
Data Augmentation of Bridging the Delay Gap for DL-based Massive MIMO CSI Feedback
Aug 01, 2023In massive multiple-input multiple-output (MIMO) systems under the frequency division duplexing (FDD) mode, the user equipment (UE) needs to feed channel state information (CSI) back to the base station (BS). Though deep learning approaches have made a hit in the CSI feedback problem, whether they can remain excellent in actual environments needs to be further investigated. In this letter, we point out that the real-time dataset in application often has the domain gap from the training dataset caused by the time delay. To bridge the gap, we propose bubble-shift (B-S) data augmentation, which attempts to offset performance degradation by changing the delay and remaining the channel information as much as possible. Moreover, random-generation (R-G) data augmentation is especially proposed for outdoor scenarios due to the complex distribution of its channels. It generalizes the characteristics of the channel matrix and alleviates the over-fitting problem. Simulation results show that the proposed data augmentation boosts the robustness of networks in both indoor and outdoor environments. The open source codes are available at https://github.com/zhanghy23/CRNet-Aug.
Deep Learning for Hybrid Beamforming with Finite Feedback in GSM Aided mmWave MIMO Systems
Feb 15, 2023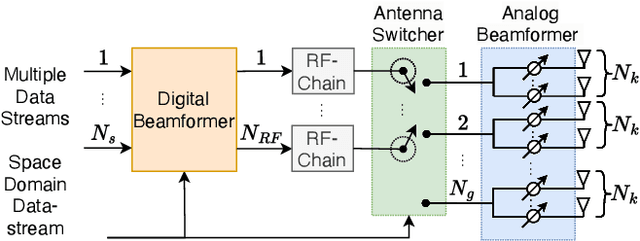


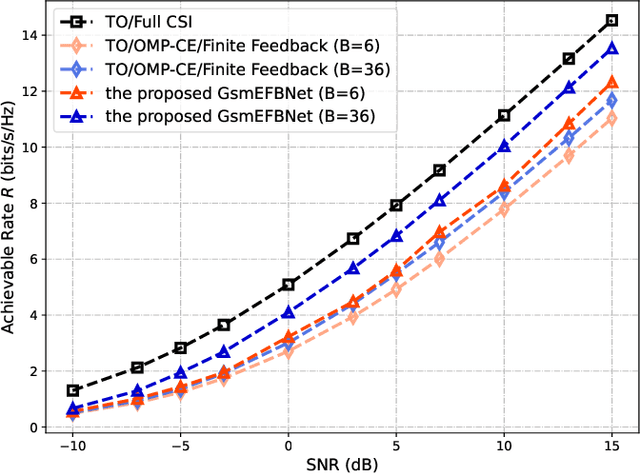
Hybrid beamforming is widely recognized as an important technique for millimeter wave (mmWave) multiple input multiple output (MIMO) systems. Generalized spatial modulation (GSM) is further introduced to improve the spectrum efficiency. However, most of the existing works on beamforming assume the perfect channel state information (CSI), which is unrealistic in practical systems. In this paper, joint optimization of downlink pilot training, channel estimation, CSI feedback, and hybrid beamforming is considered in GSM aided frequency division duplexing (FDD) mmWave MIMO systems. With the help of deep learning, the GSM hybrid beamformers are designed via unsupervised learning in an end-to-end way. Experiments show that the proposed multi-resolution network named GsmEFBNet can reach a better achievable rate with fewer feedback bits compared with the conventional algorithm.
Towards Efficient Subarray Hybrid Beamforming: Attention Network-based Practical Feedback in FDD Massive MU-MIMO Systems
Feb 05, 2023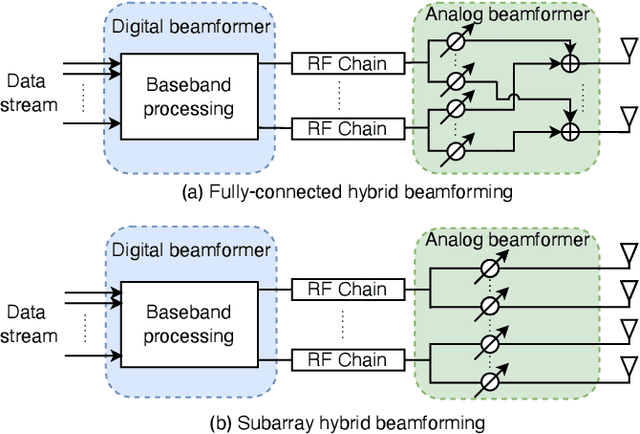



Channel state information (CSI) feedback is necessary for the frequency division duplexing (FDD) multiple input multiple output (MIMO) systems due to the channel non-reciprocity. With the help of deep learning, many works have succeeded in rebuilding the compressed ideal CSI for massive MIMO. However, simple CSI reconstruction is of limited practicality since the channel estimation and the targeted beamforming design are not considered. In this paper, a jointly optimized network is introduced for channel estimation and feedback so that a spectral-efficient beamformer can be learned. Moreover, the deployment-friendly subarray hybrid beamforming architecture is applied and a practical lightweight end-to-end network is specially designed. Experiments show that the proposed network is over 10 times lighter at the resource-sensitive user equipment compared with the previous state-of-the-art method with only a minor performance loss.
Semantics-Empowered Communication: A Tutorial-cum-Survey
Dec 21, 2022



Along with the springing up of semantics-empowered communication (SemCom) researches, it is now witnessing an unprecedentedly growing interest towards a wide range of aspects (e.g., theories, applications, metrics and implementations) in both academia and industry. In this work, we primarily aim to provide a comprehensive survey on both the background and research taxonomy, as well as a detailed technical tutorial. Specifically, we start by reviewing the literature and answering the "what" and "why" questions in semantic transmissions. Afterwards, we present corresponding ecosystems, including theories, metrics, datasets and toolkits, on top of which the taxonomy for research directions is presented. Furthermore, we propose to categorize the critical enabling techniques by explicit and implicit reasoning-based methods, and elaborate on how they evolve and contribute to modern content \& channel semantics-empowered communications. Besides reviewing and summarizing the latest efforts in SemCom, we discuss the relations with other communication levels (e.g., reliable and goal-oriented communications) from a holistic and unified viewpoint. Subsequently, in order to facilitate the future developments and industrial applications, we also highlight advanced practical techniques for boosting semantic accuracy, robustness, and large-scale scalability, just to mention a few. Finally, we discuss the technical challenges that shed light on future research opportunities.
Quantization Adaptor for Bit-Level Deep Learning-Based Massive MIMO CSI Feedback
Nov 09, 2022

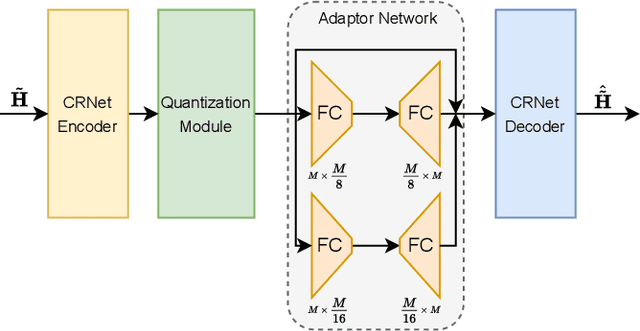

In massive multiple-input multiple-output (MIMO) systems, the user equipment (UE) needs to feed the channel state information (CSI) back to the base station (BS) for the following beamforming. But the large scale of antennas in massive MIMO systems causes huge feedback overhead. Deep learning (DL) based methods can compress the CSI at the UE and recover it at the BS, which reduces the feedback cost significantly. But the compressed CSI must be quantized into bit streams for transmission. In this paper, we propose an adaptor-assisted quantization strategy for bit-level DL-based CSI feedback. First, we design a network-aided adaptor and an advanced training scheme to adaptively improve the quantization and reconstruction accuracy. Moreover, for easy practical employment, we introduce the expert knowledge of data distribution and propose a pluggable and cost-free adaptor scheme. Experiments show that compared with the state-of-the-art feedback quantization method, this adaptor-aided quantization strategy can achieve better quantization accuracy and reconstruction performance with less or no additional cost. The open-source codes are available at https://github.com/zhang-xd18/QCRNet.
Better Lightweight Network for Free: Codeword Mimic Learning for Massive MIMO CSI feedback
Oct 29, 2022The channel state information (CSI) needs to be fed back from the user equipment (UE) to the base station (BS) in frequency division duplexing (FDD) multiple-input multiple-output (MIMO) system. Recently, neural networks are widely applied to CSI compressed feedback since the original overhead is too large for the massive MIMO system. Notably, lightweight feedback networks attract special attention due to their practicality of deployment. However, the feedback accuracy is likely to be harmed by the network compression. In this paper, a cost free distillation technique named codeword mimic (CM) is proposed to train better feedback networks with the practical lightweight encoder. A mimic-explore training strategy with a special distillation scheduler is designed to enhance the CM learning. Experiments show that the proposed CM learning outperforms the previous state-of-the-art feedback distillation method, boosting the performance of the lightweight feedback network without any extra inference cost.
Elastic-Link for Binarized Neural Network
Dec 19, 2021
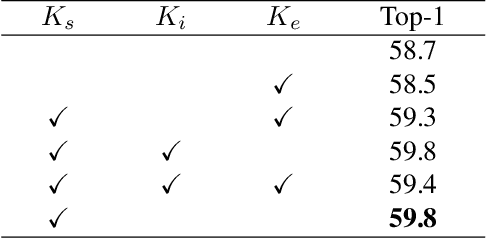
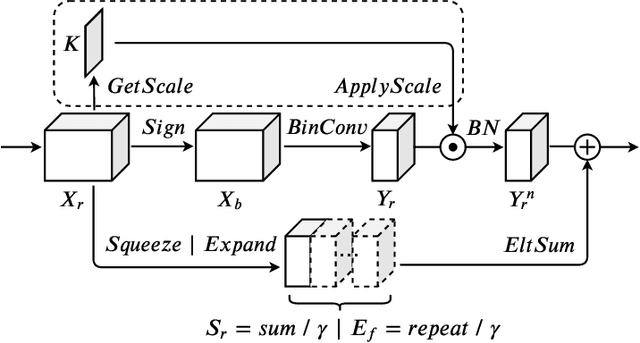
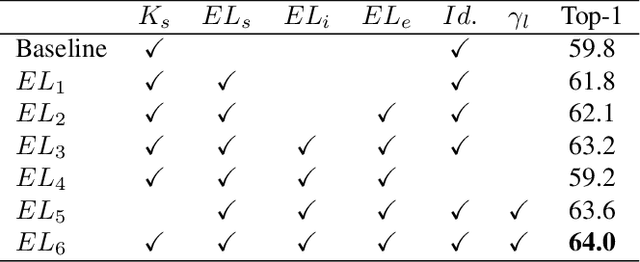
Recent work has shown that Binarized Neural Networks (BNNs) are able to greatly reduce computational costs and memory footprints, facilitating model deployment on resource-constrained devices. However, in comparison to their full-precision counterparts, BNNs suffer from severe accuracy degradation. Research aiming to reduce this accuracy gap has thus far largely focused on specific network architectures with few or no 1x1 convolutional layers, for which standard binarization methods do not work well. Because 1x1 convolutions are common in the design of modern architectures (e.g. GoogleNet, ResNet, DenseNet), it is crucial to develop a method to binarize them effectively for BNNs to be more widely adopted. In this work, we propose an "Elastic-Link" (EL) module to enrich information flow within a BNN by adaptively adding real-valued input features to the subsequent convolutional output features. The proposed EL module is easily implemented and can be used in conjunction with other methods for BNNs. We demonstrate that adding EL to BNNs produces a significant improvement on the challenging large-scale ImageNet dataset. For example, we raise the top-1 accuracy of binarized ResNet26 from 57.9% to 64.0%. EL also aids convergence in the training of binarized MobileNet, for which a top-1 accuracy of 56.4% is achieved. Finally, with the integration of ReActNet, it yields a new state-of-the-art result of 71.9% top-1 accuracy.