 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Conditional Diffusion Model with Mean Field Communication as Wireless Resource Allocation Planner
Oct 27, 2025In wireless communication systems, efficient and adaptive resource allocation plays a crucial role in enhancing overall Quality of Service (QoS). While centralized Multi-Agent Reinforcement Learning (MARL) frameworks rely on a central coordinator for policy training and resource scheduling, they suffer from scalability issues and privacy risks. In contrast, the Distributed Training with Decentralized Execution (DTDE) paradigm enables distributed learning and decision-making, but it struggles with non-stationarity and limited inter-agent cooperation, which can severely degrade system performance. To overcome these challenges, we propose the Multi-Agent Conditional Diffusion Model Planner (MA-CDMP) for decentralized communication resource management. Built upon the Model-Based Reinforcement Learning (MBRL) paradigm, MA-CDMP employs Diffusion Models (DMs) to capture environment dynamics and plan future trajectories, while an inverse dynamics model guides action generation, thereby alleviating the sample inefficiency and slow convergence of conventional DTDE methods. Moreover, to approximate large-scale agent interactions, a Mean-Field (MF) mechanism is introduced as an assistance to the classifier in DMs. This design mitigates inter-agent non-stationarity and enhances cooperation with minimal communication overhead in distributed settings. We further theoretically establish an upper bound on the distributional approximation error introduced by the MF-based diffusion generation, guaranteeing convergence stability and reliable modeling of multi-agent stochastic dynamics. Extensive experiments demonstrate that MA-CDMP consistently outperforms existing MARL baselines in terms of average reward and QoS metrics, showcasing its scalability and practicality for real-world wireless network optimization.
Geometric Meta-Learning via Coupled Ricci Flow: Unifying Knowledge Representation and Quantum Entanglement
Mar 25, 2025This paper establishes a unified framework integrating geometric flows with deep learning through three fundamental innovations. First, we propose a thermodynamically coupled Ricci flow that dynamically adapts parameter space geometry to loss landscape topology, formally proved to preserve isometric knowledge embedding (Theorem~\ref{thm:isometric}). Second, we derive explicit phase transition thresholds and critical learning rates (Theorem~\ref{thm:critical}) through curvature blowup analysis, enabling automated singularity resolution via geometric surgery (Lemma~\ref{lem:surgery}). Third, we establish an AdS/CFT-type holographic duality (Theorem~\ref{thm:ads}) between neural networks and conformal field theories, providing entanglement entropy bounds for regularization design. Experiments demonstrate 2.1$\times$ convergence acceleration and 63\% topological simplification while maintaining $\mathcal{O}(N\log N)$ complexity, outperforming Riemannian baselines by 15.2\% in few-shot accuracy. Theoretically, we prove exponential stability (Theorem~\ref{thm:converge}) through a new Lyapunov function combining Perelman entropy with Wasserstein gradient flows, fundamentally advancing geometric deep learning.
Instant square lattice structured illumination microscopy: an optimal strategy towards photon-saving and real-time super-resolution observation
Feb 05, 2024Over the past decade, structured illumination microscopy (SIM) has found its niche in super-resolution (SR) microscopy due to its fast imaging speed and low excitation intensity. However, due to the significantly higher light dose compared to wide-field microscopy and the time-consuming post-processing procedures, long-term, real-time, super-resolution observation of living cells is still out of reach for most SIM setups, which inevitably limits its routine use by cell biologists. Here, we describe square lattice SIM (SL-SIM) for long-duration live cell imaging by using the square lattice optical field as illumination, which allows continuous super-resolved observation over long periods of time. In addition, by extending the previous joint spatial-frequency reconstruction concept to SL-SIM, a high-speed reconstruction strategy is validated in the GPU environment, whose reconstruction time is even shorter than image acquisition time, thus enabling real-time observation. We have demonstrated the potential of SL-SIM on various biological applications, ranging from microtubule cytoskeleton dynamics to the interactions of mitochondrial cristae and DNAs in COS7 cells. The inherent lower light dose and user-friendly workflow of the SL-SIM could help make long-duration, real-time and super-resolved observations accessible to biological laboratories.
Self-Critical Alternate Learning based Semantic Broadcast Communication
Dec 03, 2023



Semantic communication (SemCom) has been deemed as a promising communication paradigm to break through the bottleneck of traditional communications. Nonetheless, most of the existing works focus more on point-to-point communication scenarios and its extension to multi-user scenarios is not that straightforward due to its cost-inefficiencies to directly scale the JSCC framework to the multi-user communication system. Meanwhile, previous methods optimize the system by differentiable bit-level supervision, easily leading to a "semantic gap". Therefore, we delve into multi-user broadcast communication (BC) based on the universal transformer (UT) and propose a reinforcement learning (RL) based self-critical alternate learning (SCAL) algorithm, named SemanticBC-SCAL, to capably adapt to the different BC channels from one transmitter (TX) to multiple receivers (RXs) for sentence generation task. In particular, to enable stable optimization via a nondifferentiable semantic metric, we regard sentence similarity as a reward and formulate this learning process as an RL problem. Considering the huge decision space, we adopt a lightweight but efficient self-critical supervision to guide the learning process. Meanwhile, an alternate learning mechanism is developed to provide cost-effective learning, in which the encoder and decoders are updated asynchronously with different iterations. Notably, the incorporation of RL makes SemanticBC-SCAL compliant with any user-defined semantic similarity metric and simultaneously addresses the channel non-differentiability issue by alternate learning. Besides, the convergence of SemanticBC-SCAL is also theoretically established. Extensive simulation results have been conducted to verify the effectiveness and superiorness of our approach, especially in low SNRs.
Fast List Decoding of High-Rate Polar Codes
Nov 14, 2023



Due to the ability to provide superior error-correction performance, the successive cancellation list (SCL) algorithm is widely regarded as one of the most promising decoding algorithms for polar codes with short-to-moderate code lengths. However, the application of SCL decoding in low-latency communication scenarios is limited due to its sequential nature. To reduce the decoding latency, developing tailored fast and efficient list decoding algorithms of specific polar substituent codes (special nodes) is a promising solution. Recently, fast list decoding algorithms are proposed by considering special nodes with low code rates. Aiming to further speedup the SCL decoding, this paper presents fast list decoding algorithms for two types of high-rate special nodes, namely single-parity-check (SPC) nodes and sequence rate one or single-parity-check (SR1/SPC) nodes. In particular, we develop two classes of fast list decoding algorithms for these nodes, where the first class uses a sequential decoding procedure to yield decoding latency that is linear with the list size, and the second further parallelizes the decoding process by pre-determining the redundant candidate paths offline. Simulation results show that the proposed list decoding algorithms are able to achieve up to 70.7\% lower decoding latency than state-of-the-art fast SCL decoders, while exhibiting the same error-correction performance.
Fast Successive-Cancellation Decoding of Polar Codes with Sequence Nodes
Apr 26, 2022

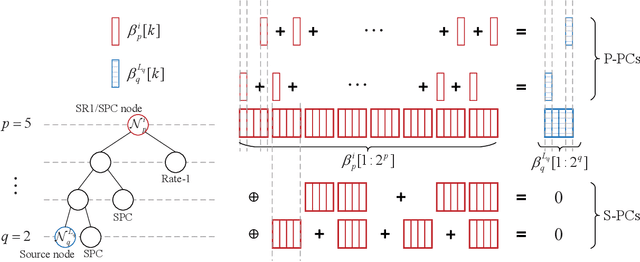

Due to the sequential nature of the successive-cancellation (SC) algorithm, the decoding of polar codes suffers from significant decoding latencies. Fast SC decoding is able to speed up the SC decoding process, by implementing parallel decoders at the intermediate levels of the SC decoding tree for some special nodes with specific information and frozen bit patterns. To further improve the parallelism of SC decoding, this paper present a new class of special node composed of a sequence of rate one or single-parity-check (SR1/SPC) nodes, which envelops a wide variety of existing special node types. Then, we analyse the parity constraints caused by the frozen bits in each descendant node, such that the decoding performance of the SR1/SPC node can be preserved once the parity constraints are satisfied. Finally, a generalized fast SC decoding algorithm is proposed for the SR1/SPC node, where the corresponding parity constraints are taken into consideration. Simulation results show that compared with the state-of-the-art fast SC decoding algorithms, the proposed decoding algorithm achieves a higher degree of parallelism, especially for high-rate polar codes, without tangibly altering the error-correction performance.
ProsoSpeech: Enhancing Prosody With Quantized Vector Pre-training in Text-to-Speech
Feb 16, 2022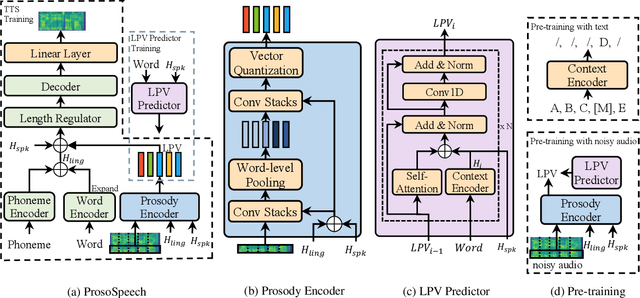
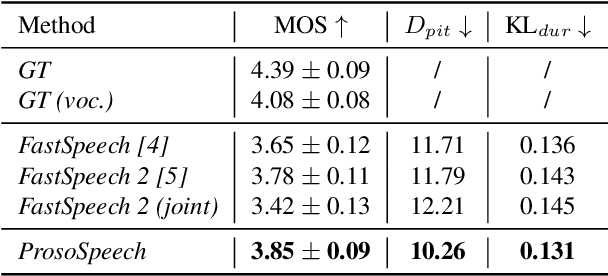

Expressive text-to-speech (TTS) has become a hot research topic recently, mainly focusing on modeling prosody in speech. Prosody modeling has several challenges: 1) the extracted pitch used in previous prosody modeling works have inevitable errors, which hurts the prosody modeling; 2) different attributes of prosody (e.g., pitch, duration and energy) are dependent on each other and produce the natural prosody together; and 3) due to high variability of prosody and the limited amount of high-quality data for TTS training, the distribution of prosody cannot be fully shaped. To tackle these issues, we propose ProsoSpeech, which enhances the prosody using quantized latent vectors pre-trained on large-scale unpaired and low-quality text and speech data. Specifically, we first introduce a word-level prosody encoder, which quantizes the low-frequency band of the speech and compresses prosody attributes in the latent prosody vector (LPV). Then we introduce an LPV predictor, which predicts LPV given word sequence. We pre-train the LPV predictor on large-scale text and low-quality speech data and fine-tune it on the high-quality TTS dataset. Finally, our model can generate expressive speech conditioned on the predicted LPV. Experimental results show that ProsoSpeech can generate speech with richer prosody compared with baseline methods.
Speaker Embedding-aware Neural Diarization for Flexible Number of Speakers with Textual Information
Nov 28, 2021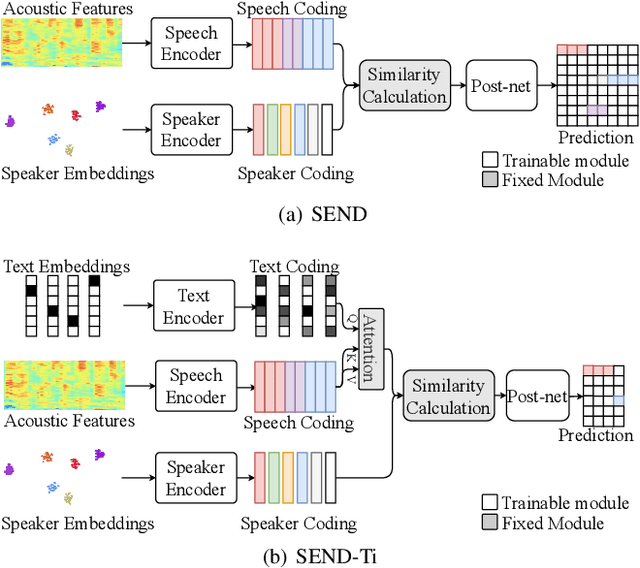

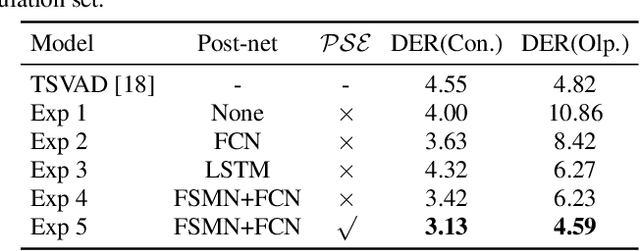

Overlapping speech diarization is always treated as a multi-label classification problem. In this paper, we reformulate this task as a single-label prediction problem by encoding the multi-speaker labels with power set. Specifically, we propose the speaker embedding-aware neural diarization (SEND) method, which predicts the power set encoded labels according to the similarities between speech features and given speaker embeddings. Our method is further extended and integrated with downstream tasks by utilizing the textual information, which has not been well studied in previous literature. The experimental results show that our method achieves lower diarization error rate than the target-speaker voice activity detection. When textual information is involved, the diarization errors can be further reduced. For the real meeting scenario, our method can achieve 34.11% relative improvement compared with the Bayesian hidden Markov model based clustering algorithm.
FedSpeech: Federated Text-to-Speech with Continual Learning
Oct 14, 2021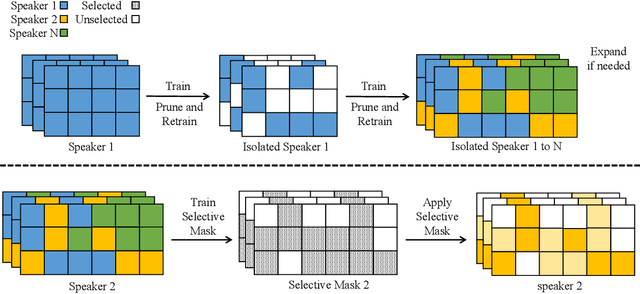



Federated learning enables collaborative training of machine learning models under strict privacy restrictions and federated text-to-speech aims to synthesize natural speech of multiple users with a few audio training samples stored in their devices locally. However, federated text-to-speech faces several challenges: very few training samples from each speaker are available, training samples are all stored in local device of each user, and global model is vulnerable to various attacks. In this paper, we propose a novel federated learning architecture based on continual learning approaches to overcome the difficulties above. Specifically, 1) we use gradual pruning masks to isolate parameters for preserving speakers' tones; 2) we apply selective masks for effectively reusing knowledge from tasks; 3) a private speaker embedding is introduced to keep users' privacy. Experiments on a reduced VCTK dataset demonstrate the effectiveness of FedSpeech: it nearly matches multi-task training in terms of multi-speaker speech quality; moreover, it sufficiently retains the speakers' tones and even outperforms the multi-task training in the speaker similarity experiment.
* Accepted by IJCAI 2021
BeamTransformer: Microphone Array-based Overlapping Speech Detection
Sep 09, 2021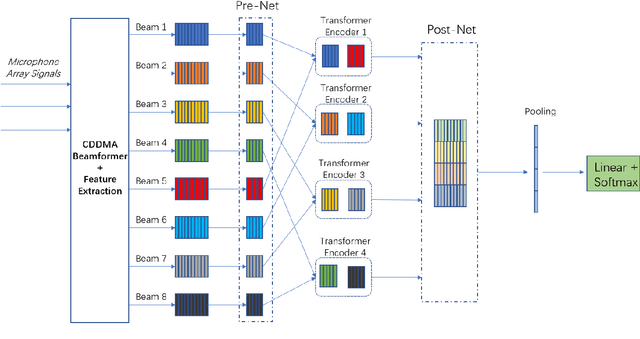

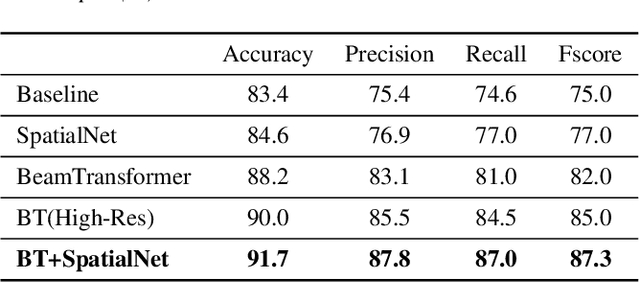
We propose BeamTransformer, an efficient architecture to leverage beamformer's edge in spatial filtering and transformer's capability in context sequence modeling. BeamTransformer seeks to optimize modeling of sequential relationship among signals from different spatial direction. Overlapping speech detection is one of the tasks where such optimization is favorable. In this paper we effectively apply BeamTransformer to detect overlapping segments. Comparing to single-channel approach, BeamTransformer exceeds in learning to identify the relationship among different beam sequences and hence able to make predictions not only from the acoustic signals but also the localization of the source. The results indicate that a successful incorporation of microphone array signals can lead to remarkable gains. Moreover, BeamTransformer takes one step further, as speech from overlapped speakers have been internally separated into different beams.